




LightGBM 简介
LightGBM[1]是一个开源、分布式、高性能梯度增强(GBDT、GBRT、GBM 或 MART)框架。该框架专门用于创建高质量和 GPU 支持的决策树算法,用于排名、分类和许多其他机器学习任务。LightGBM 是微软DMTK[2]项目的一部分。
LightGBM on Spark 的优点
可组合性:LightGBM 模型可以合并到现有的 SparkML 管道中,并用于批处理、流处理和服务工作负载。 性能:在 Spark 上的 LightGBM 比在 Higgs 数据集上的 SparkML 快 10-30%,并且实现了 15%的 AUC 增长。平行实验[3]已经验证了 LightGBM 可以通过在特定设置中使用多台机器进行训练来实现线性加速。 功能:LightGBM 提供了大量的可调参数[4],人们可以使用这些参数定制他们的决策树系统。Spark 上的 LightGBM 还支持分位数回归等新类型的问题。 跨平台 Spark 上的 LightGBM 可在 Spark, PySpark 和 SparklyR 上使用
LightGBM 用法:
LightGBMClassifier:用于构建分类模型。
例如,为了预测一家公司是否会破产,我们可以使用LightGBMClassifier构建一个二分类模型。
LightGBMRegressor:用于构建回归模型。
例如,为了预测房价,我们可以使用LightGBMRegressor构建一个回归模型。
LightGBMRanker:用于构建排名模型。
例如,为了预测网站搜索结果的相关性,我们可以使用LightGBMRanker构建一个排名模型。
LightGBM 分类器破产预测

在本例中,我们使用 LightGBM 构建一个分类模型来预测破产。
初始化 SparkSession
import pysparkspark = pyspark.sql.SparkSession.builder.master("local[*]")\.appName("mmlspark") \ .config("spark.jars.packages", "com.microsoft.ml.spark:mmlspark_2.12:1.0.0-rc3-76-aad223e0-SNAPSHOT,org.apache.hadoop:hadoop-azure:3.3.1") \ .config("spark.jars.repositories", "https://mmlspark.azureedge.net/maven") \ .config("spark.executor.memory", "4g") \ .enableHiveSupport()\ .getOrCreate()import mmlspark
⚠️
在本地环境运行,需要手动配置 mmlspark 包, 根据 spark 版本以及 scala 版本选择, 目前官方 release 的 rc3 版本并不支持 Spark 3 及最新的 LightGBM 3.2.1, 如果想支持 Spark 3 或者想支持最新版本的 LightGBM,推荐使用 master 版本。
读取 azure storage 需要额外的包(
org.apache.hadoop:hadoop-azure:3.3.1
)来支持,否则报错如下,
Class org.apache.hadoop.fs.azure.NativeAzureFileSystem$Secure not found
读取数据
df = spark.read.format("csv")\ .option("header", True)\ .option("inferSchema", True)\ .load("wasbs://publicwasb@mmlspark.blob.core.windows.net/company_bankruptcy_prediction_data.csv")# print dataset sizeprint("records read: " + str(df.count()))print("Schema: ")df.printSchema()
分割测试集与训练集
train, test = df.randomSplit([0.85, 0.15], seed=1)
将特征转换为向量
from pyspark.ml.feature import VectorAssemblerfeature_cols = df.columns[1:]featurizer = VectorAssembler( inputCols=feature_cols, outputCol='features')train_data = featurizer.transform(train)['Bankrupt?', 'features']test_data = featurizer.transform(test)['Bankrupt?', 'features']
检查样本是否为不平衡数据
train_data.groupBy("Bankrupt?").count().toPandas()
| Bankrupt? | count |
|---|---|
| 1 | 194 |
| 0 | 5591 |
从上面结果看,为不平衡数据,训练模型的时候 isUnbalance 参数赋值 True。
模型训练
from mmlspark.lightgbm import LightGBMClassifiermodel = LightGBMClassifier(objective="binary" , featuresCol="features" , labelCol="Bankrupt?" , isUnbalance=True)model = model.fit(train_data)
保存与加载模型
from mmlspark.lightgbm import LightGBMClassificationModel#保存模型model.saveNativeModel("lgbmclassifier.model")#加载模型model = LightGBMClassificationModel.loadNativeModelFromFile("lgbmclassifier.model")
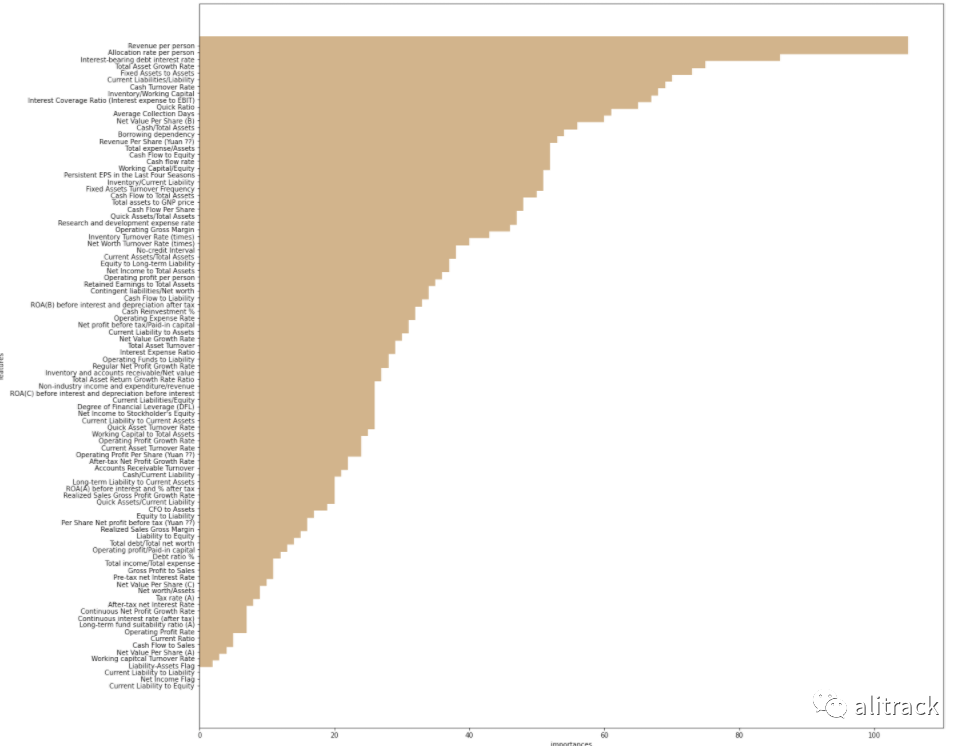
可视化特征重要性
import pandas as pdimport matplotlib.pyplot as pltfeature_importances = model.getFeatureImportances()fi = pd.Series(feature_importances,index = feature_cols)fi = fi.sort_values(ascending = True)f_index = fi.indexf_values = fi.values# print feature importancesprint ('f_index:',f_index)print ('f_values:',f_values)# plotx_index = list(range(len(fi)))x_index = [x/len(fi) for x in x_index]plt.rcParams['figure.figsize'] = (20,20)plt.barh(x_index,f_values,height = 0.028 ,align="center",color = 'tan',tick_label=f_index)plt.xlabel('importances')plt.ylabel('features')plt.show()
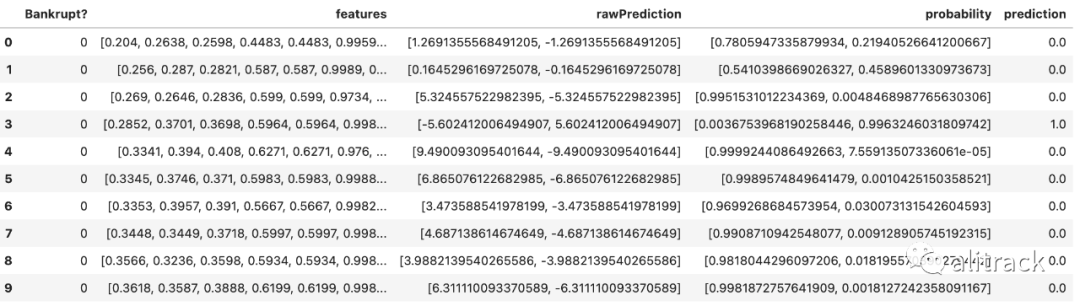
预测模型
predictions = model.transform(test_data)predictions.limit(10).toPandas()
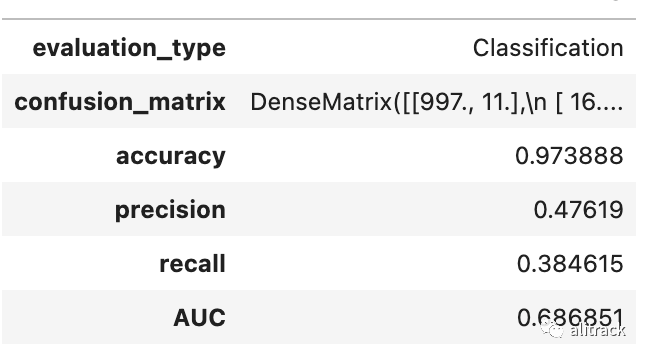
评估模型
LightGBMRegressor 用于药物发现的分位数回归

在本例中,我们将展示如何使用 LightGBM 来构建一个简单的回归模型。
读取数据
triazines = spark.read.format("libsvm")\ .load("wasbs://publicwasb@mmlspark.blob.core.windows.net/triazines.scale.svmlight")
打印基本信息
# print some basic infoprint("records read: " + str(triazines.count()))print("Schema: ")triazines.printSchema()display(triazines.limit(10))
拆分训练集与测试集
train, test = triazines.randomSplit([0.85, 0.15], seed=1)
训练模型
rom mmlspark.lightgbm import LightGBMRegressormodel = LightGBMRegressor(objective='quantile', alpha=0.2, learningRate=0.3, numLeaves=31).fit(train)
打印特征重要性信息
print(model.getFeatureImportances())
模型预测
scoredData = model.transform(test)scoredData.toPandas()
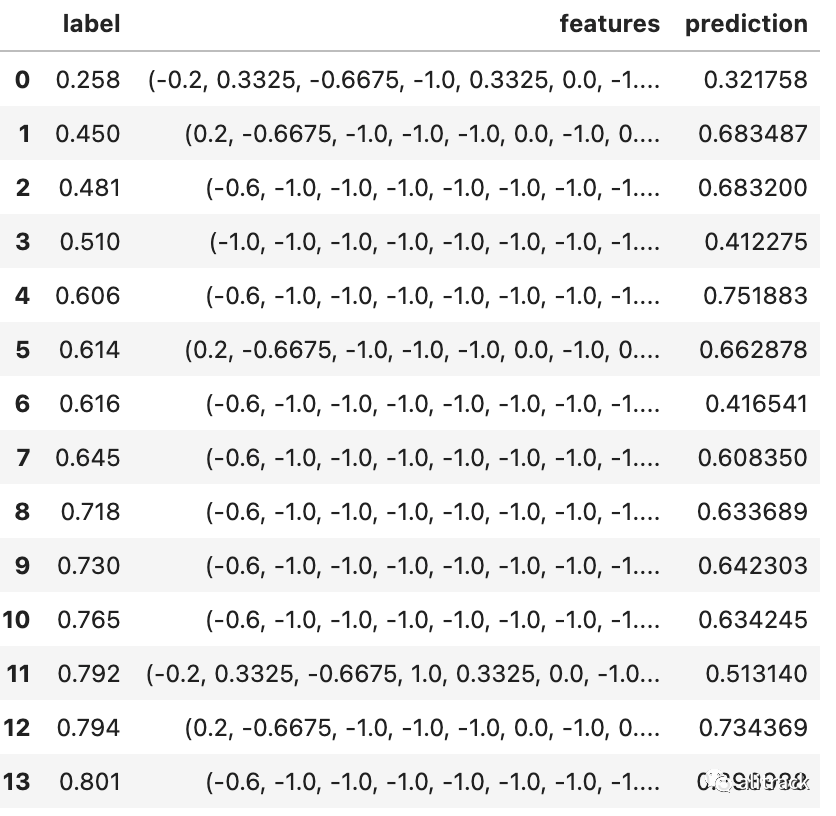
from mmlspark.train import ComputeModelStatisticsmetrics = ComputeModelStatistics(evaluationMetric='regression', labelCol='label', scoresCol='prediction') \ .transform(scoredData)metrics.toPandas()
| mean_squared_error | root_mean_squared_error | R^2 | mean_absolute_error | |
|---|---|---|---|---|
| 0 | 0.032046 | 0.179014 | -0.372525 | 0.14795 |
LightGBM 排序
读取数据
df = spark.read.format("parquet").load("wasbs://publicwasb@mmlspark.blob.core.windows.net/lightGBMRanker_train.parquet")# print some basic infoprint("records read: " + str(df.count()))print("Schema: ")df.printSchema()display(df.limit(10))
训练模型
from mmlspark.lightgbm import LightGBMRankerfeatures_col = 'features'query_col = 'query'label_col = 'labels'lgbm_ranker = LightGBMRanker(labelCol=label_col, featuresCol=features_col, groupCol=query_col, predictionCol='preds', leafPredictionCol='leafPreds', featuresShapCol='importances',
repartitionByGroupingColumn=True,
numLeaves=32,
numIterations=200,
evalAt=[1,3,5],
metric='ndcg')
lgbm_ranker_model = lgbm_ranker.fit(df)
预测模型
dt = spark.read.format("parquet").load("wasbs://publicwasb@mmlspark.blob.core.windows.net/lightGBMRanker_test.parquet")
predictions = lgbm_ranker_model.transform(dt)
predictions.limit(10).toPandas()
写在最后
wasbs
wasbs 是 Windows Azure Storage Blob 的缩写, Azure Blob 存储是 Microsoft 提供的适用于云的对象存储解决方案。Blob 存储最适合存储巨量的非结构化数据。非结构化数据是不遵循特定数据模型或定义的数据(如文本或二进制数据),类似于亚马逊的 S3。
如果访问 wasbs 有问题,可以从别处寻找数据集替代。
为了便于重复测试,建议把数据集保存在本地
company_bankruptcy_prediction_data
# 因为变量名有特殊字符,不能保存为parquet(需要先改名字), 暂时保存到本地为csv
# 并注册为表名company_bankruptcy_prediction_data
df.write.format("csv").mode("overwrite").saveAsTable("company_bankruptcy_prediction_data")
triazines
triazines.write.format("parquet").mode("overwrite").saveAsTable("triazines")
排序数据所用的训练集与测试集
df.write.format("parquet").mode("overwrite").saveAsTable("lightGBMRanker_train")
df.write.format("parquet").mode("overwrite").saveAsTable("lightGBMRanker_test")
本例子最大的难点在于使用正确的 mmlspark 包
本文改自mmlspark的LightGBM示例:
https://github.com/microsoft/SynapseML/blob/master/notebooks/LightGBM%20-%20Overview.ipynb
LightGBM: https://github.com/Microsoft/LightGBM
[2]DMTK: http://github.com/microsoft/dmtk
[3]平行实验: https://github.com/Microsoft/LightGBM/blob/master/docs/Experiments.rst#parallel-experiment
[4]可调参数: https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters.rst
欢迎关注公众号

有兴趣加群讨论数据挖掘和分析的朋友可以加我微信(witwall),暗号:入群

也欢迎投稿!
