




不平衡的类使准确性
指标失去了意义,这是机器学习中一个令人惊讶的常见问题(特别是在分类中),发生在每个类中观察值不成比例的数据集中。
不平衡类出现在许多领域,包括:
欺诈识别 垃圾邮件过滤 疾病筛查 SaaS 订阅流失 广告点击率
直觉:疾病筛查示例
假设您的客户是一家领先的研究医院,他们要求您训练一个模型,用于根据从患者那里收集的生物输入来检测疾病。
但问题是……这种疾病相对罕见。它仅发生在接受筛查的患者中的 8%。
现在,在您开始之前,您是否看到问题可能会如何解决?想象一下,如果您根本不费心训练模型。相反,如果您只编写一行始终预测“无疾病”的代码会怎样?
#一个蹩脚但很准确的解决方案
def disease_screen(patient_data):
# Ignore patient_data
return 'No Disease.'
嗯,你猜怎么着?您的“解决方案”将具有 92% 的准确率!
不幸的是,这种准确性具有误导性。
对于没有患病的患者,您将获得 100% 的准确度。 对于 确实患有这种疾病的患者,您的准确度为 0%。 您的整体准确度会很高,因为大多数患者没有患病(而不是因为您的模型很好)。
这显然是一个问题,因为许多机器学习算法旨在最大限度地提高整体准确性。本指南的其余部分将说明处理不平衡类的不同策略。
在我们开始之前的重要注意事项:
首先,请注意,我们不会拆分单独的测试集、调整超参数或实施交叉验证。换句话说,我们不一定要遵循最佳实践。
相反,本教程完全专注于解决不平衡的类。
此外,并非以下每种技术都适用于所有问题。但是,10 次中有 9 次,这些技术中至少有一种应该可以解决问题。
天平数据集
这里,我们将使用一个名为 Balance Scale Data 的合成数据集,您可以在此处[1]从 UCI 机器学习存储库下载 。
这个数据集最初是为了模拟心理实验结果而生成的,但它对我们很有用,因为它的大小是可管理的,并且具有不平衡的类别。
import pandas as pd
import numpy as np
# Read dataset
df = pd.read_csv('balance-scale.data',
names=['balance', 'var1', 'var2', 'var3', 'var4'])
# Display example observations
df.head()
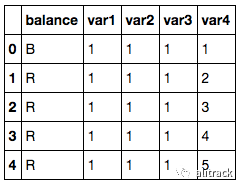
该数据集包含有关秤是否平衡的信息,基于两条手臂的重量和距离。
它有 1 个目标变量,我们将其标记为 balance 。 它有 4 个输入特征,我们将它们标记为 var1 到 var4 。
目标变量有 3 个类。
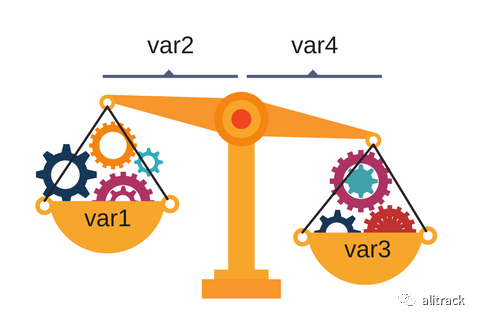
R表示右重,即当 var3 _ var4 > var1 _ var2 L表示左重,即当 var3 _ var4 < var1 _ var2 B表示平衡,即当 var3 _ var4 = var1 _ var2
df['balance'].value_counts()
# R 288
# L 288
# B 49
# Name: balance, dtype: int64
但是,对于本教程,我们将把它变成一个二元分类问题。
如果尺度是平衡的,我们将每个观察标记为1(正类),如果尺度不平衡, 我们将标记为 0(负类):
# Transform into binary classification
df['balance'] = [1 if b=='B' else 0 for b in df.balance]
df['balance'].value_counts()
# 0 576
# 1 49
# Name: balance, dtype: int64
# About 8% were balanced
如您所见,只有大约 8% 的观察结果是平衡的。因此,如果我们总是预测 0,我们将达到 92% 的准确率。
不平衡类的危险
现在我们有了一个数据集,我们可以真正展示不平衡类的危险。
首先,让我们从Scikit-Learn[2]导入逻辑回归算法和准确度度量。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
接下来,我们将使用所有内容的默认设置来拟合一个非常简单的模型。
# Separate input features (X) and target variable (y)
y = df.balance
X = df.drop('balance', axis=1)
# Train model
clf_0 = LogisticRegression().fit(X, y)
# Predict on training set
pred_y_0 = clf_0.predict(X)
如上所述,默认情况下,许多机器学习算法旨在最大限度地提高整体准确性。
我们可以确认这一点:
# How's the accuracy?
print( accuracy_score(pred_y_0, y) )
# 0.9216
所以我们的模型具有 92% 的整体准确率,但是否因为它只预测了 1 个类别?
# Should we be excited?
print( np.unique( pred_y_0 ) )
# [0]
如您所见,此模型仅预测 0,这意味着它完全忽略了少数类而支持多数类。
接下来,我们将研究处理不平衡类的第一种技术:对少数类进行上采样。
1. 上采样少数类
上采样是随机复制少数类的观察结果以加强其信号的过程。
有几种启发式方法可以这样做,但最常见的方法是简单地重新采样并替换。
首先,我们将从 Scikit-Learn 导入重采样模块:
from sklearn.utils import resample
接下来,我们将创建一个具有上采样少数类的新 DataFrame。以下是步骤:
首先,我们将来自每个类的观察分离到不同的 DataFrame 中。 接下来,我们将使用 replacement重新采样少数类,设置样本数以匹配多数类的样本数。 最后,我们将上采样的少数类 DataFrame 与原始多数类 DataFrame 结合起来。
这是代码:
# Separate majority and minority classes
df_majority = df[df.balance==0]
df_minority = df[df.balance==1]
# Upsample minority class
df_minority_upsampled = resample(df_minority,
replace=True, # sample with replacement
n_samples=576, # to match majority class
random_state=123) # reproducible results
# Combine majority class with upsampled minority class
df_upsampled = pd.concat([df_majority, df_minority_upsampled])
# Display new class counts
df_upsampled.balance.value_counts()
# 1 576
# 0 576
# Name: balance, dtype: int64
可以看到,新的 DataFrame 比原来的有更多的观察,现在两个类的比例是 1:1。
让我们使用逻辑回归训练另一个模型,这次是在平衡数据集上:
# Separate input features (X) and target variable (y)
y = df_upsampled.balance
X = df_upsampled.drop('balance', axis=1)
# Train model
clf_1 = LogisticRegression().fit(X, y)
# Predict on training set
pred_y_1 = clf_1.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_1 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_1) )
# 0.513888888889
太好了,现在模型不再只预测一类。虽然准确性也急剧下降,但它现在作为性能指标更有意义。
2. 下样本多数类
下采样涉及从多数类中随机删除观察值,以防止其信号支配学习算法。
这样做的最常见的启发式方法是重采样而不替换。
该过程类似于上采样。以下是步骤:
首先,我们将来自每个类的观察分离到不同的 DataFrame 中。 接下来,我们将在不替换的情况下重新采样多数类,设置样本数量以匹配少数类的数量。 最后,我们将下采样的多数类 DataFrame 与原始少数类 DataFrame 结合起来。
这是代码:
# Separate majority and minority classes
df_majority = df[df.balance==0]
df_minority = df[df.balance==1]
# Downsample majority class
df_majority_downsampled = resample(df_majority,
replace=False, # sample without replacement
n_samples=49, # to match minority class
random_state=123) # reproducible results
# Combine minority class with downsampled majority class
df_downsampled = pd.concat([df_majority_downsampled, df_minority])
# Display new class counts
df_downsampled.balance.value_counts()
# 1 49
# 0 49
# Name: balance, dtype: int64
这一次,新的 DataFrame 的观察值比原来的少,现在两个类的比例是 1:1。
同样,让我们使用 Logistic 回归训练模型:
# Separate input features (X) and target variable (y)
y = df_downsampled.balance
X = df_downsampled.drop('balance', axis=1)
# Train model
clf_2 = LogisticRegression().fit(X, y)
# Predict on training set
pred_y_2 = clf_2.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_2 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_2) )
# 0.581632653061
该模型不仅仅预测一类,而且准确度似乎更高。
我们仍然希望在一个看不见的测试数据集上验证模型,但结果更令人鼓舞。
3. 改变你的绩效指标
到目前为止,我们已经研究了通过重新采样数据集来解决不平衡类的两种方法。接下来,我们将研究使用其他性能指标来评估模型。
阿尔伯特·爱因斯坦曾经说过:“如果你用爬树的能力来判断一条鱼,它终其一生都认为自己是愚蠢的。” 这句话真正强调了选择正确评估指标的重要性。
对于分类的通用指标,我们建议使用 ROC 曲线下面积(AUROC)。
我们不会在本指南中深入探讨其详细信息,但您可以在此处[3]阅读更多相关信息。 直观地说,AUROC 表示您的模型将观测值从两个类别中区分出来的可能性。 换句话说,如果您从每个类别中随机选择一个观察值,您的模型能够正确 排序
它们的概率是多少?
我们可以从 Scikit-Learn 导入这个指标:
from sklearn.metrics import roc_auc_score
要计算 AUROC,您需要预测类别概率,而不仅仅是预测类别。您可以使用.predict_proba()
函数如下:
# Predict class probabilities
prob_y_2 = clf_2.predict_proba(X)
# Keep only the positive class
prob_y_2 = [p[1] for p in prob_y_2]
prob_y_2[:5] # Example
# [0.45419197226479618,
# 0.48205962213283882,
# 0.46862327066392456,
# 0.47868378832689096,
# 0.58143856820159667]
那么这个模型(在下采样数据集上训练)在 AUROC 方面表现如何?
print( roc_auc_score(y, prob_y_2) )
# 0.568096626406
好的……这与在不平衡数据集上训练的原始模型相比如何?
prob_y_0 = clf_0.predict_proba(X)
prob_y_0 = [p[1] for p in prob_y_0]
print( roc_auc_score(y, prob_y_0) )
# 0.530718537415
请记住,我们在不平衡数据集上训练的原始模型的准确率为 92%,远高于在下采样数据集上训练的模型的 58% 准确率。
但是,后一个模型的 AUROC 为 57%,高于原始模型的 53%(但相差不大)。
**注意:**如果您的 AUROC 为 0.47,则仅意味着您需要反转预测,因为 Scikit-Learn 误解了正类。AUROC 应 >= 0.5。
4.惩罚算法(成本敏感训练)
下一个策略是使用惩罚学习算法,增加少数类分类错误的成本。
这种技术的流行算法是 Penalized-SVM:
from sklearn.svm import SVC
在训练期间,我们可以使用参数 class_weight = 'balanced' 来惩罚少数类的错误,数量与它的代表性不足成正比。
如果我们想为 SVM 算法启用概率估计,我们还想包括参数 probability=True
。
让我们在原始不平衡数据集上使用 Penalized-SVM 训练模型:
# Separate input features (X) and target variable (y)
y = df.balance
X = df.drop('balance', axis=1)
# Train model
clf_3 = SVC(kernel='linear',
class_weight='balanced', # penalize
probability=True)
clf_3.fit(X, y)
# Predict on training set
pred_y_3 = clf_3.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_3 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_3) )
# 0.688
# What about AUROC?
prob_y_3 = clf_3.predict_proba(X)
prob_y_3 = [p[1] for p in prob_y_3]
print( roc_auc_score(y, prob_y_3) )
# 0.5305236678
同样,我们在这里的目的只是为了说明这种技术。要真正确定哪种策略最适合此问题,您需要在保留测试集上评估模型。
5. 使用基于树的算法
我们将考虑的最后一种策略是使用基于树的算法。决策树通常在不平衡数据集上表现良好,因为它们的层次结构允许它们从两个类别中学习信号。
在现代应用机器学习中,集成树(随机森林、梯度提升树等)几乎总是优于单一决策树,因此我们将直接进入这些:
from sklearn.ensemble import RandomForestClassifier
现在,让我们在原始不平衡数据集上使用随机森林训练模型。
# Separate input features (X) and target variable (y)
y = df.balance
X = df.drop('balance', axis=1)
# Train model
clf_4 = RandomForestClassifier()
clf_4.fit(X, y)
# Predict on training set
pred_y_4 = clf_4.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_4 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_4) )
# 0.9744
# What about AUROC?
prob_y_4 = clf_4.predict_proba(X)
prob_y_4 = [p[1] for p in prob_y_4]
print( roc_auc_score(y, prob_y_4) )
# 0.999078798186
哇!97% 的准确率和接近 100% 的 AUROC?这是魔法吗?花招?作弊?难以置信?
嗯,树集成已经变得非常流行,因为它们在许多现实世界的问题上表现得非常好。我们当然全心全意地推荐他们。
然而:
虽然这些结果令人鼓舞,但模型可能会过度拟合,因此在做出最终决定之前,您仍应在未见过的测试集上评估您的模型。
注意:由于算法的随机性,您的数字可能略有不同。您可以设置随机种子以获得可重复的结果。
友情提醒
有一些策略没有包含在本教程中:
创建合成样本(数据增强)
创建合成样本是上采样的近亲,有些人可能会将它们归类在一起。例如,SMOTE 算法[4]是一种从少数类中重新采样同时稍微扰乱特征值的方法,从而创建“新”样本。
您可以在imblearn 库中[5]找到SMOTE[6]的实现。
结合少数类
组合目标变量的少数类可能适用于一些多类问题。
例如,假设您希望预测信用卡欺诈。在您的数据集中,可能会单独标记每种欺诈方法,但您可能并不关心区分它们。您可以将它们全部组合成一个欺诈
类,并将问题视为二元分类。
重构为异常检测
异常检测,又名异常值检测,用于 检测异常值和罕见事件[7]。您将拥有一个正常观察的轮廓
,而不是构建分类模型。如果新观察结果偏离正常轮廓
太远,它将被标记为异常。
结论和后续步骤
在本指南中,我们介绍了在机器学习中处理不平衡类的 5 种策略:
对少数类进行上采样(过采样) 对多数类进行下采样(欠采样) 更改您的绩效指标 惩罚算法(成本敏感训练) 使用基于树的算法
这些策略受No Free Lunch
定理的约束,您应该尝试其中的几种策略,并使用测试集的结果来决定解决问题的最佳解决方案。
参考资料
在此处: http://archive.ics.uci.edu/ml/datasets/balance+scale
[2]Scikit-Learn: http://scikit-learn.org/stable/
[3]在此处: https://stats.stackexchange.com/questions/132777/what-does-auc-stand-for-and-what-is-it
[4]SMOTE 算法: https://www.jair.org/media/953/live-953-2037-jair.pdf
[5]imblearn 库中: http://contrib.scikit-learn.org/imbalanced-learn/generated/imblearn.over_sampling.SMOTE.html
[6]SMOTE: http://contrib.scikit-learn.org/imbalanced-learn/generated/imblearn.over_sampling.SMOTE.html
[7]检测异常值和罕见事件: https://en.wikipedia.org/wiki/Anomaly_detection
原文:How to Handle Imbalanced Classes in Machine Learning
欢迎关注公众号

有兴趣加群讨论数据挖掘和分析的朋友可以加我微信(witwall),暗号:入群

也欢迎投稿!
