




表结构定义中的自增ID
结论
表定义的自增值达到上限后的逻辑是,表的自增id达到上限后,再申请时它的值就不会改变,进而导致继续插入数据时报主键冲突的错误。
验证
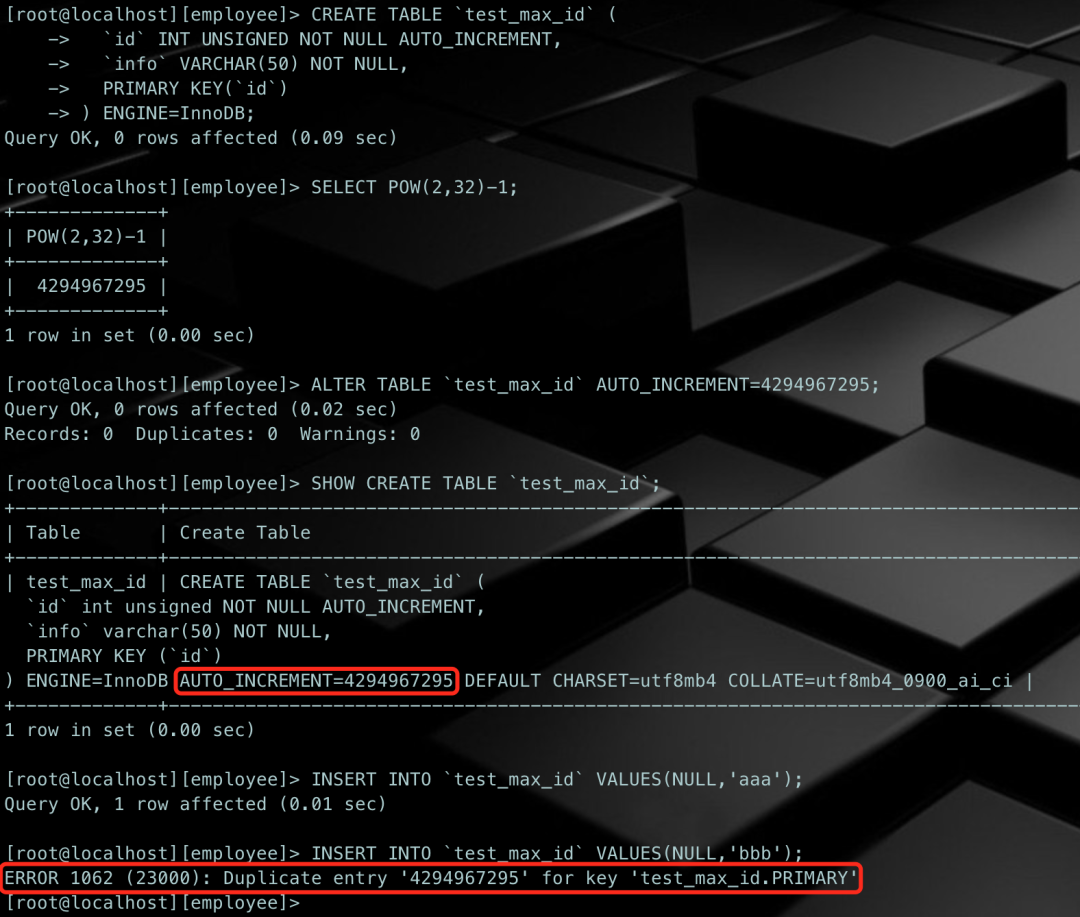
/* 创建一张测试表 */CREATE TABLE `test_max_id` ( `id` INT UNSIGNED NOT NULL AUTO_INCREMENT, `info` VARCHAR(50) NOT NULL, PRIMARY KEY(`id`)) ENGINE=InnoDB;/* 指定表的AUTO_INCREMENT属性值为最大值 */SELECT POW(2,32)-1;ALTER TABLE `test_max_id` AUTO_INCREMENT=4294967295;/* 插入记录 */INSERT INTO `test_max_id` VALUES(NULL,'aaa');INSERT INTO `test_max_id` VALUES(NULL,'bbb');
说明 & 注意
我们首先创建了一张含有无符号自增属性INT类型的主键列`id`,然后通过数学函数得到无符号INT类型的最大值,然后将`test_max_id`表的AUTO_INCREMENT属性设置为服务号INT类型的最大值,然后插入数据,插入'bbb'的时候报错。

InnoDB自增row_id
结论
row_id达到上限后,则会归0再重新递增,如果出现相同的row_id,后写的数据会覆盖之前的数据。
概念
如果你创建的InnoDB表没有指定主键,那么InnoDB会给你创建一个不可见的,长度为6个字节的row_id。InnoDB维护了一个全局的dict_sys.row_id值,所有无主键的InnoDB表,每插入一行数据,都将当前的dict_sys.row_id值作为要插入数据的row_id,然后把dict_sys.row_id的值加1。
实际上,在代码实现时row_id是一个长度为8字节的无符号长整型 (bigint unsigned)。但是,InnoDB在设计时,给row_id留的只是6个字节的长度,这样写到数据表中时只放了最后6个字节,所以row_id能写到数据表中的值,就有两个特征:
1、row_id写入表中的值范围,是从0到2⁴⁸-1;
2、当dict_sys.row_id=2⁴⁸时,如果再有插入数据的行为要来申请row_id,拿到以后再取最后6个字节的话就是0。(写入表的row_id是从0开始到2⁴⁸-1。达到上限后,下一个值就是0,然后继续循环。)
说明
在InnoDB逻辑里,申请到row_id=N后,就将这行数据写入表中;如果表中已经存在row_id=N的行,新写入的行就会覆盖原有的行。
我们还是应该在InnoDB 表中主动创建自增主键。因为,表自增id到达上限后,再插入数据时报主键冲突错误,是更能被接受的。(毕竟覆盖数据,就意味着数据丢失,影响的是数据可靠性;报主键冲突,是插入失败,影响的是可用性。而一般情况下,可靠性优先于可用性。)
补充知识点 & 注意
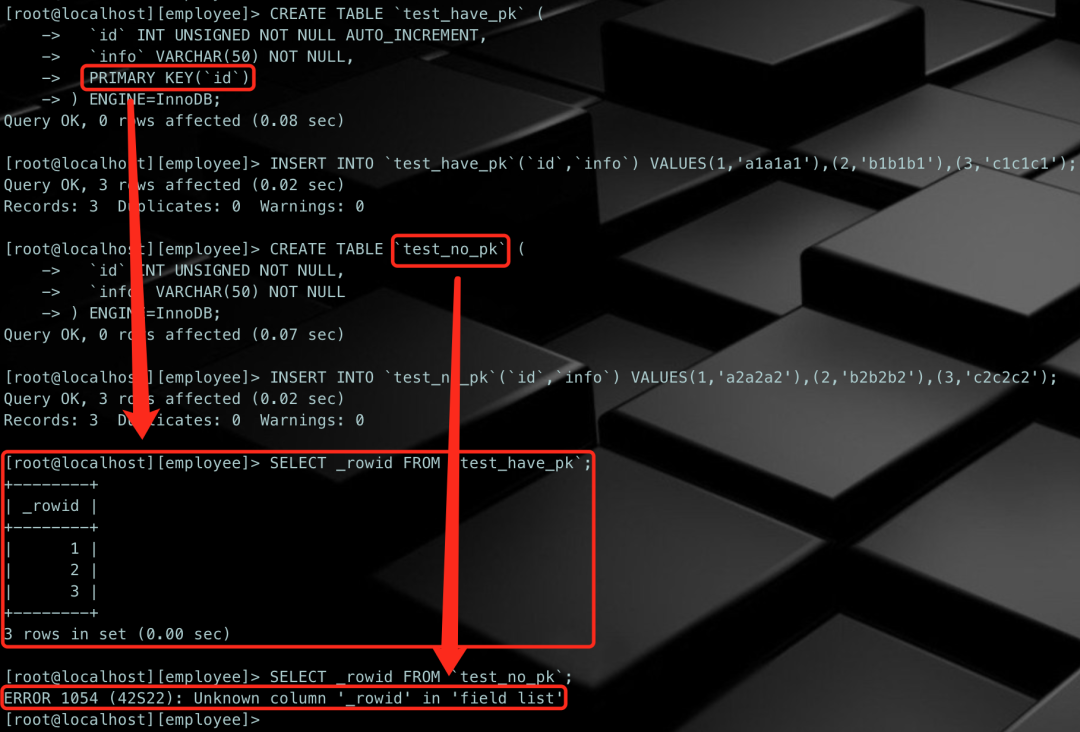
row_id虽然说是不可见,但真的不可见吗?!答案是否定的,有一部分情况是可见的。
/* 创建1张测试表,有主键 */CREATE TABLE `test_have_pk` ( `id` INT UNSIGNED NOT NULL AUTO_INCREMENT, `info` VARCHAR(50) NOT NULL, PRIMARY KEY(`id`)) ENGINE=InnoDB;/* 插入3行测试数据 */INSERT INTO `test_have_pk`(`id`,`info`) VALUES(1,'a1a1a1'),(2,'b1b1b1'),(3,'c1c1c1');/* 创建另1张测试表,无主键 */CREATE TABLE `test_no_pk` ( `id` INT UNSIGNED NOT NULL, `info` VARCHAR(50) NOT NULL) ENGINE=InnoDB;/* 插入3行测试数据 */INSERT INTO `test_no_pk`(`id`,`info`) VALUES(1,'a2a2a2'),(2,'b2b2b2'),(3,'c2c2c2');/* 查询两张表中的row_id */SELECT _rowid FROM `test_have_pk`;SELECT _rowid FROM `test_no_pk`;

MySQL Server Xid
结论
Xid只需要不在同一个binlog文件中出现重复值即可。虽然理论上会出现重复值,但是概率极小,可以忽略不计。
概念
MySQL内部维护了一个全局变量global_query_id,每次执行语句的时候将它赋值给Query_id,然后给这个变量加1。如果当前语句是这个事务执行的第一条语句,那么MySQL还会同时把Query_id赋值给这个事务的Xid。
而global_query_id是一个纯内存变量,重启之后就清零了。在同一个数据库实例中,不同事务的Xid也是有可能相同的。但是MySQL重启之后会重新生成新的binlog文件,这就保证了,同一个binlog文件里,Xid一定是唯一的。
说明
如果global_query_id达到上限后,就会继续从0开始计数。从理论上讲,还是就会出现同一个binlog里面出现相同Xid的场景。
因为global_query_id定义的长度是8个字节,这个自增值的上限是 2⁶⁴-1。要出现这种情况,必须是下面这样的过程:
1、执行一个事务,假设Xid是A;
2、接下来执行2⁶⁴次查询语句,让global_query_id回到 A;
3、再启动一个事务,这个事务的Xid也是A。
注意
不过,2⁶⁴这个值太大了,大到你可以认为这个可能性只会存在于理论上。
MySQL thread_id
结论
thread_id是我们使用中最常见而且也是处理得最好的一个自增id逻辑了。
概念
线程id是MySQL中最常见的一种自增id。平时我们在查各种现场的时候,show processlist里面的第一列,就是thread_id。
说明
thread_id的逻辑很好理解:系统保存了一个全局变量thread_id_counter,每新建一个连接,就将thread_id_counter赋值给这个新连接的线程变量。
thread_id_counter定义的大小是4个字节,因此达到2³²-1后,它就会重置为0,然后继续增加。但是,你不会在show processlist里看到两个相同的thread_id。
因为MySQL设计了一个唯一数组的逻辑,给新线程分配thread_id的时候,逻辑代码是这样的:
注意
因为MySQL设计了一个唯一数组的逻辑,所以,不会在show processlist里看到两个相同的 thread_id。
InnoDB trx_id
结论
InnoDB的max_trx_id递增值每次MySQL重启都会被保存起来,脏读就是一个必现的BUG,好在留给我们的时间还很充裕。
概念
MySQL Server Xid和InnoDB的trx_id是两个容易混淆的概念。Xid是由Server层维护的。InnoDB内部使用Xid,就是为了能够在InnoDB事务和Server之间做关联。但是,InnoDB自己的trx_id,是另外维护的。
说明
InnoDB内部维护了一个max_trx_id全局变量,每次需要申请一个新的trx_id时,就获得max_trx_id的当前值,然后并将max_trx_id加1。
InnoDB数据可见性的核心思想是:每一行数据都记录了更新它的trx_id,当一个事务读到一行数据的时候,判断这个数据是否可见的方法,就是通过事务的一致性视图与这行数据的trx_id做对比。
trx_id不止加 1。这是因为:
1、update和delete语句除了事务本身,还涉及到标记删除旧数据,也就是要把数据放到purge队列里等待后续物理删除,这个操作也会把max_trx_id+1, 因此在一个事务中至少加2;
2、InnoDB的后台操作,比如表的索引信息统计这类操作,也是会启动内部事务的,因此你可能看到,trx_id值并不是按照加1递增的。
补充
只读事务不分配 trx_id,有什么好处呢?
一个好处是,这样做可以减小事务视图里面活跃事务数组的大小。因为当前正在运行的只读事务,是不影响数据的可见性判断的。所以,在创建事务的一致性视图时,InnoDB就只需要拷贝读写事务的trx_id。
另一个好处是,可以减少trx_id的申请次数。在InnoDB里,即使你只是执行一个普通的select语句,在执行过程中,也是要对应一个只读事务的。所以只读事务优化后,普通的查询语句不需要申请trx_id,就大大减少了并发事务申请trx_id的锁冲突。
(由于只读事务不分配 trx_id,一个自然而然的结果就是 trx_id 的增加速度变慢了。)
注意
max_trx_id会持久化存储,重启也不会重置为0,那么从理论上讲,只要一个MySQL服务跑得足够久,就可能出现max_trx_id达到 2⁴⁸-1 的上限,然后从0开始的情况。当达到这个状态后,MySQL就会持续出现一个脏读的bug:
首先我们需要把当前的max_trx_id先修改成 2⁴⁸-1。
已经把系统的max_trx_id设置成了2⁴⁸-1,所以在session A启动的事务TA的低水位就是2⁴⁸-1。
在T2时刻,session B执行第一条update语句的事务id就是2⁴⁸-1,而第二条update语句的事务id就是0了,这条update语句执行后生成的数据版本上的trx_id就是 0。
在T3时刻,session A执行select语句的时候,判断可见性发现,c=3这个数据版本的trx_id,小于事务TA的低水位,因此认为这个数据可见。但,这个是脏读。由于低水位值会持续增加,而事务id从0开始计数,就导致了系统在这个时刻之后,所有的查询都会出现脏读的。并且,MySQL重启时max_trx_id也不会清 0,也就是说重启MySQL,这个BUG 仍然存在。

这个BUG也是只存在于理论上吗?
假设一个MySQL实例的TPS是每秒50万,持续这个压力的话,在17.8年后,就会出现这个情况。如果TPS更高,这个年限自然也就更短了。但是,从MySQL的真正开始流行到现在,恐怕都还没有实例跑到过这个上限。不过,这个BUG是只要MySQL实例服务时间够长,就会必然出现的。好在留给我们的时间还很充裕。
MySQL binlog文件编号
结论
概念
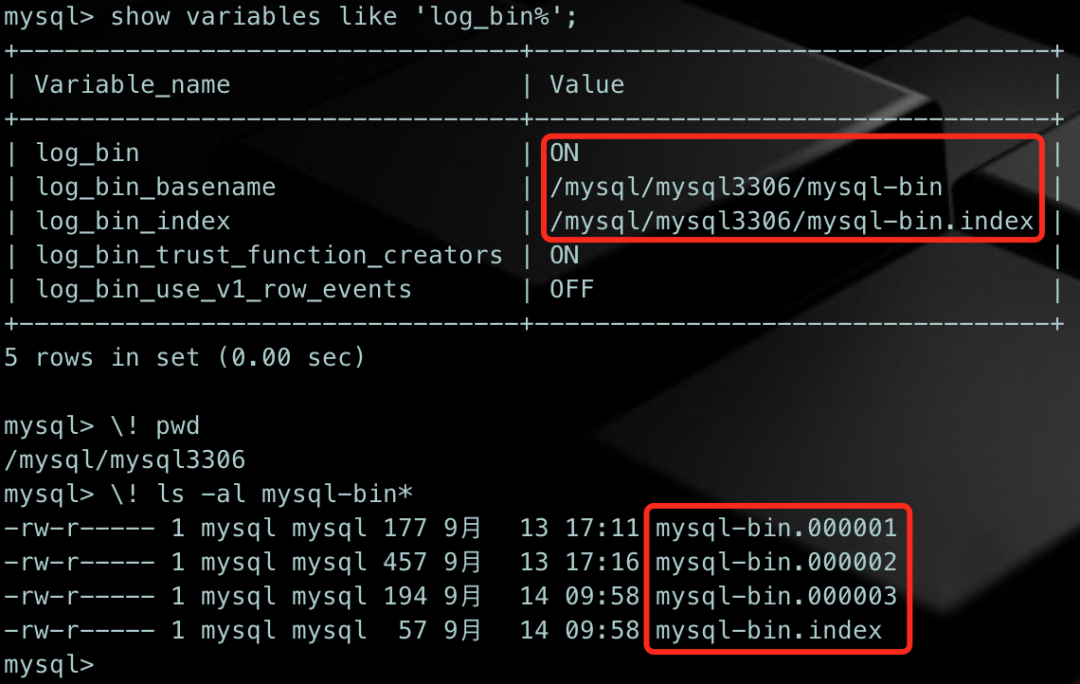
每个binlog文件都有编号,从最早的3位数(没错,很老的版本只有3位数~),到现在扩展到6位数,从000001开始计数。
疑问 & 验证
从文件编号可以看出,最大是6位,如果序号达到999999后,会怎么样?
MySQL在启动时会扫一下binlog文件,找到最大的序号,然后产生下个序号文件。根据这个规则,我们可以自行测试一下,若当前最大的binlog序号是999999时,下一个文件序号是重新从000001开始,抑或是1000000呢?
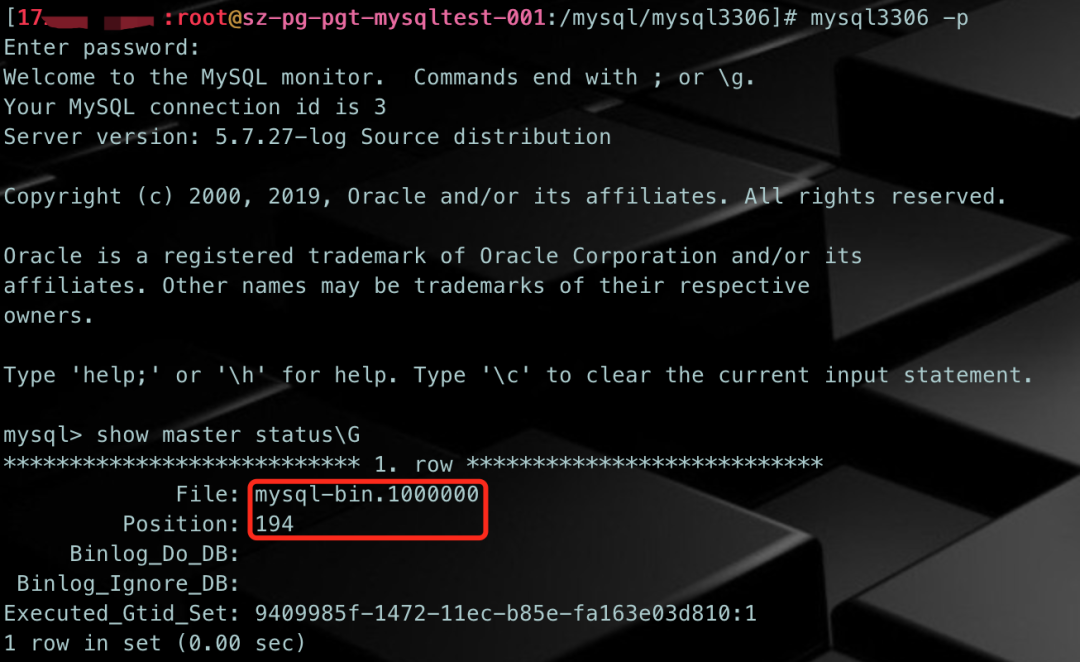
※ 测试场景1:当文件序号达到999999后,是否会生成下一个新文件?序号是多少?
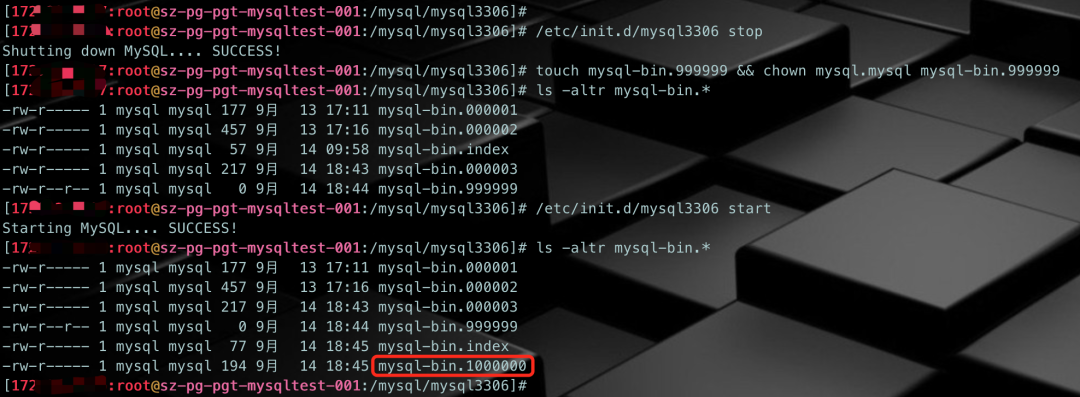
把mysqld关掉,人为造出序号为999999的binlog,并直接启动mysqld,看看会怎样呢?
# 1、停掉mysqld/etc/init.d/mysql3306 stop# 2、手动生成mysql-bin.999999并赋予mysql:mysql属主和属组touch mysql-bin.999999 && chown mysql.mysql mysql-bin.999999# 3、确认文件是否生成成功ls -altr mysql-bin.*# 4、启动mysqld/etc/init.d/mysql3306 start# 5、查看是否生成新的binlogls -altr mysql-bin.*# 6、登录mysql确认mysql> show master status;
static int find_uniq_filename(char *name){ (...代码省略...) file_info= dir_info->dir_entry; for (i= dir_info->number_off_files ; i-- ; file_info++) { if (strncmp(file_info->name, start, length) == 0 && is_number(file_info->name+length, &number,0)) { set_if_bigger(max_found, number); } } my_dirend(dir_info); /* check if reached the maximum possible extension number */ if (max_found == MAX_LOG_UNIQUE_FN_EXT) { sql_print_error("Log filename extension number exhausted: %06lu. \Please fix this by archiving old logs and \updating the index files.", max_found); error= 1; goto end; } (...代码省略...)}
if (max_found == MAX_LOG_UNIQUE_FN_EXT)
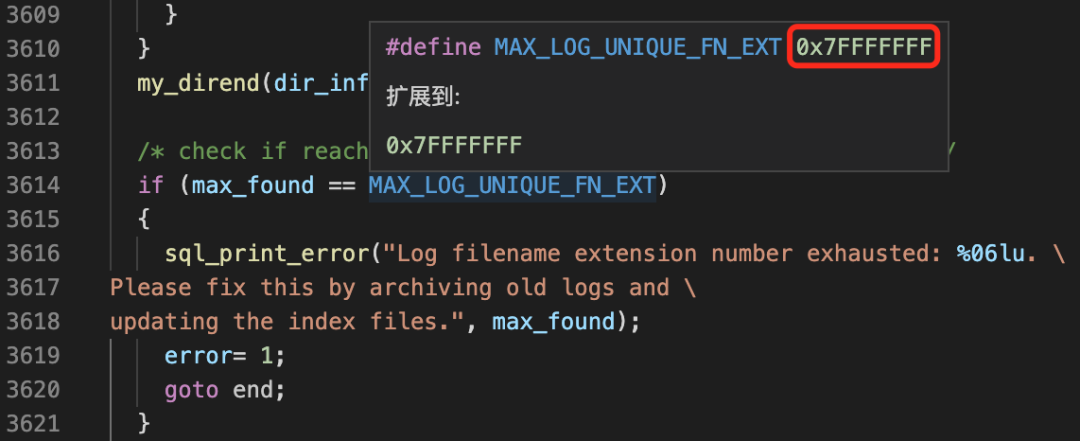
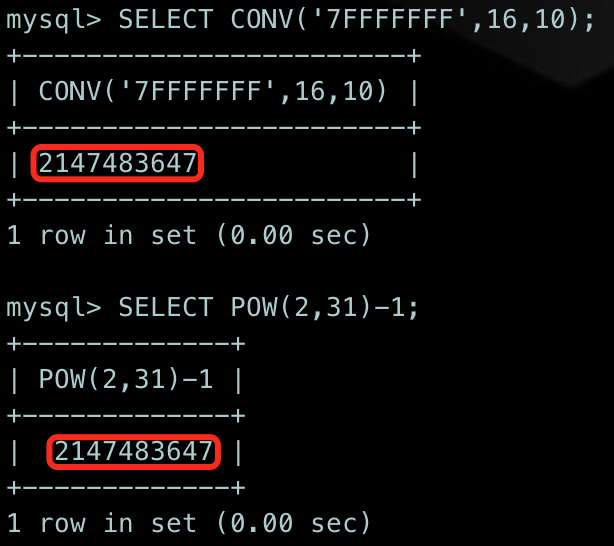
/* Maximum unique log filename extension. Note: setting to 0x7FFFFFFF due to atol windows overflow/truncate. */#define MAX_LOG_UNIQUE_FN_EXT 0x7FFFFFFF
SELECT CONV('7FFFFFFF',16,10);
※ 测试场景2:测试当binlog序号达到最大值后会怎么样
手动创建一个序号较大的binlog,比如mysql-bin.2147483640。把所有日志文件名都写入到mysql-bin.index中,并确认mysql-bin.000001文件存在(看会不会被覆盖或者其他的)。然后启动mysqld,再执行FLUSH LOGS,看看会怎样。
# 1、停掉mysqld/etc/init.d/mysql3306 stop# 2、手动生成mysql-bin.2147483640并赋予mysql:mysql属主和属组touch mysql-bin.2147483640 && chown mysql.mysql mysql-bin.2147483640# 3、确认文件是否生成成功ls -altr mysql-bin.*# 4、启动mysqld/etc/init.d/mysql3306 start# 5、执行FLUSH LOGSmysql> FLUSH LOGS;# 6、查看错误日志tail -f mysql/mysql3306/sz-pg-pgt-mysqltest-001.tendcloud.com.err# 7、查看MASTER状态mysql> show master status;# 8、多执行几次FLUSH LOGS(切换日志),直到序号达到最大值mysql> FLUSH LOGS;
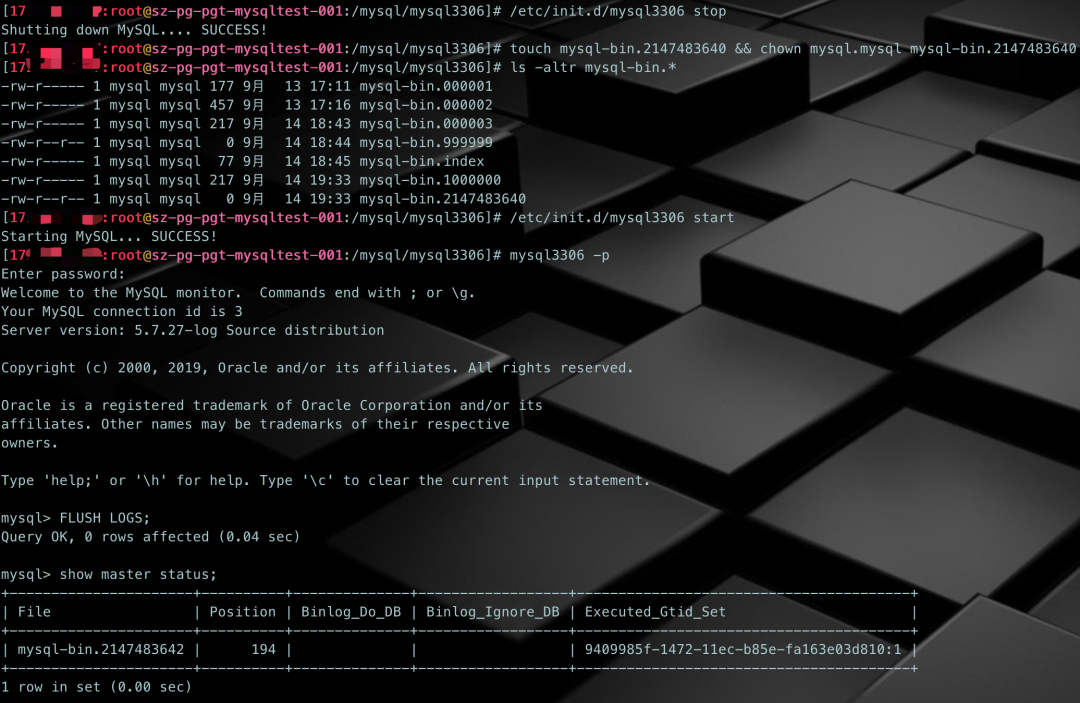

步骤8多执行几次FLUSH LOGS,切换日志,直到序号达到最大值:
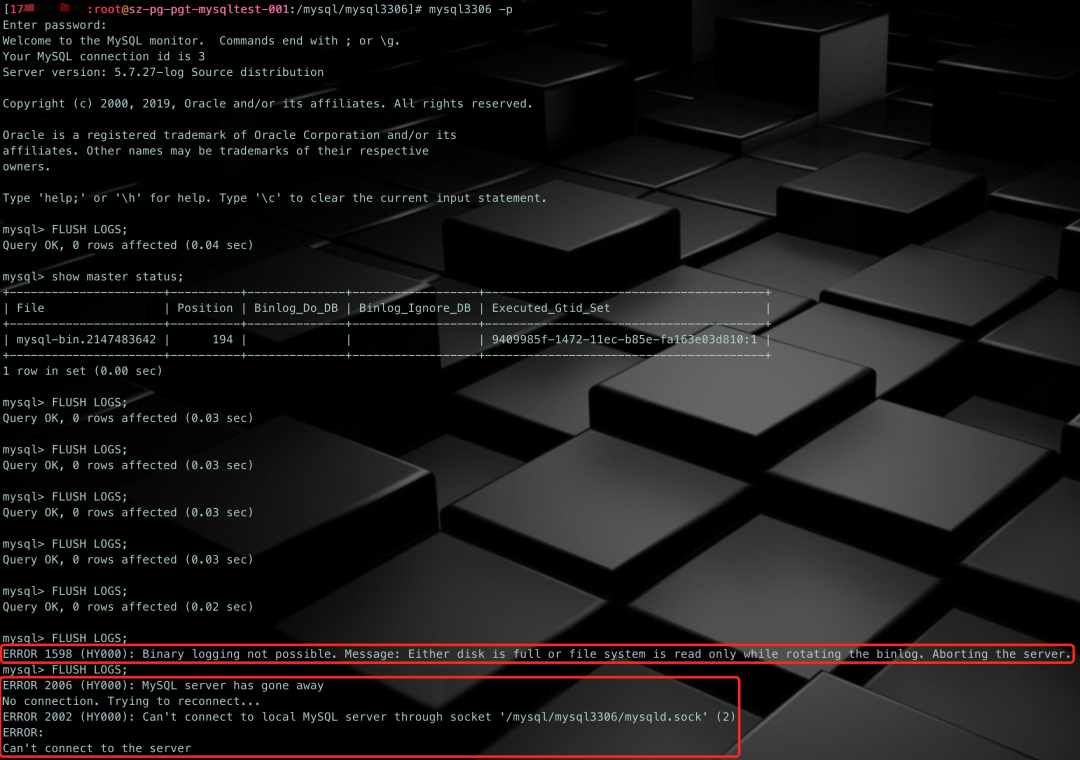
第一次切换会发出一个 ERROR 级别错误日志,第二次再切换,直接导致 mysqld 进程退出了。看看错误日志:

看这架势,是想生成 mysql-bin.(1-999) 这样的文件而未果。于是我们再进行下面的测试。
※ 测试场景3:测试binlog序号能不能循环重来
还是touch一个较大序号的binlog,比如mysql-bin.2147483645。把所有日志文名都写入到mysql-bin.index中,并确认mysql-bin.000001文件到mysql-bin.000999这些文件都不存在(和测试场景2不同,这次是要确保这些文件不存在,看能不能重复利用)。然后启动mysqld,再执行 FLUSH LOGS,看看会怎样。
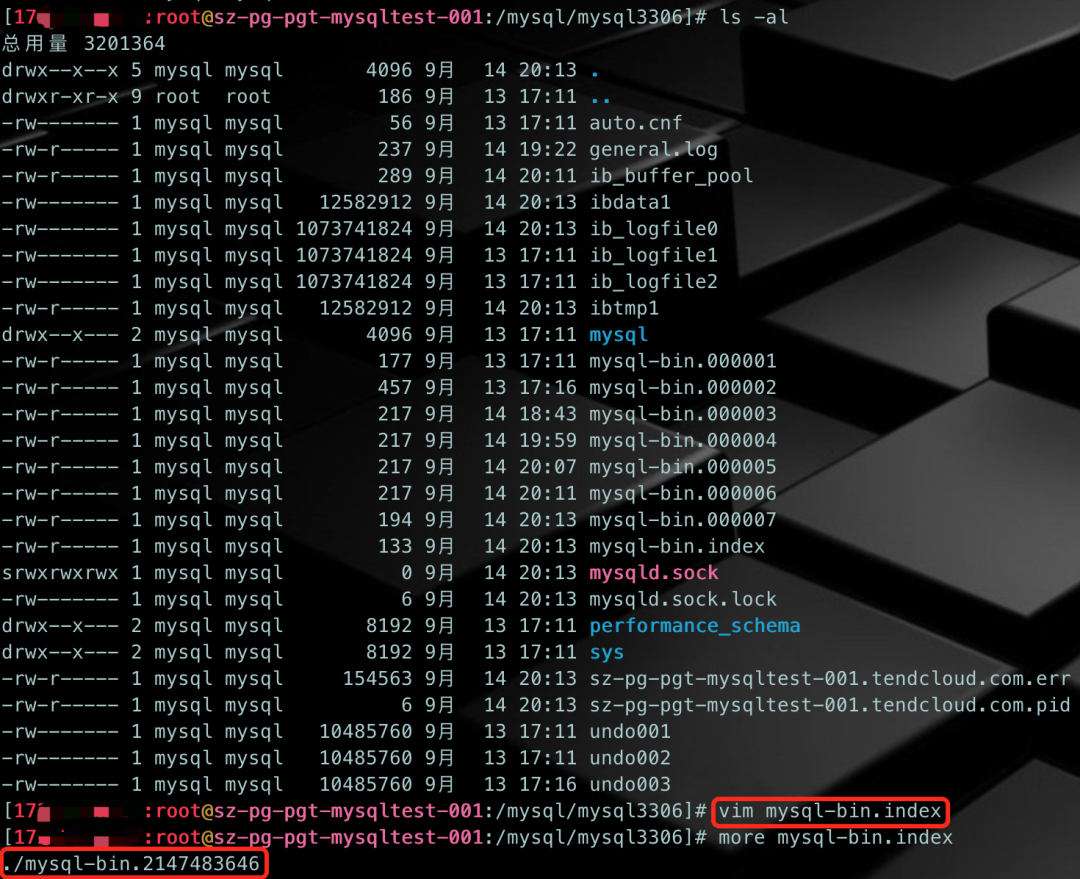
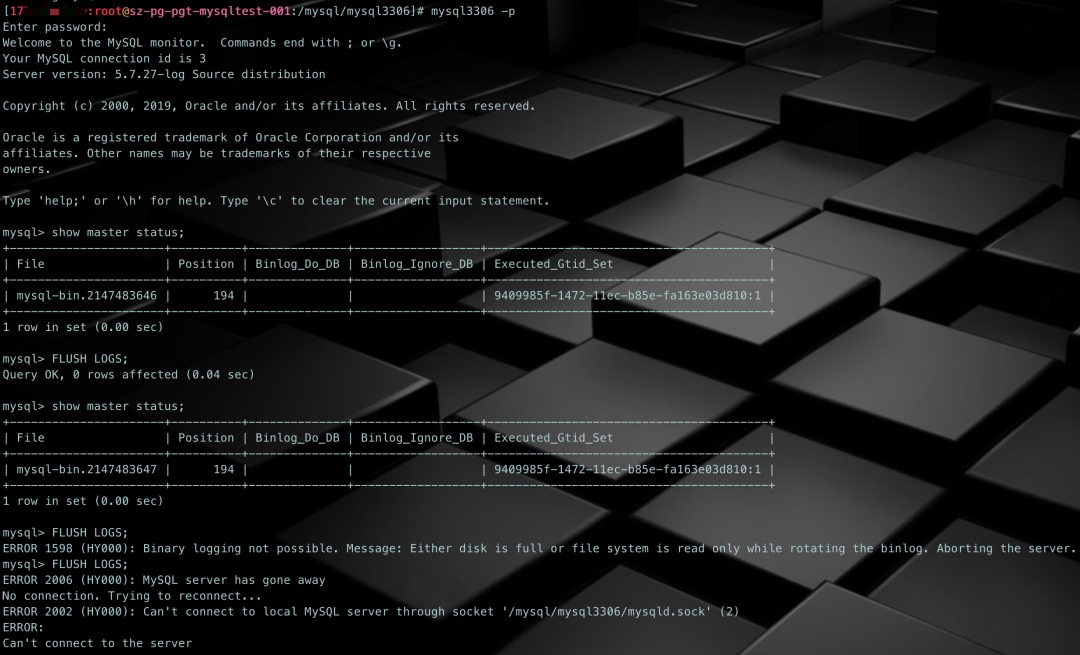
可以看到,还是会退出,并没有进行日志的轮转再次重复利用。
小结


end
