





编者按:近几年国产数据库市场风生水起,涌现了多款优秀的国产数据库产品,本文选取了三款典型的国产分布式数据库进行全方位对比压测,呈现了国产分布式数据库的发展现状。

 PolarDB-X
PolarDB-X
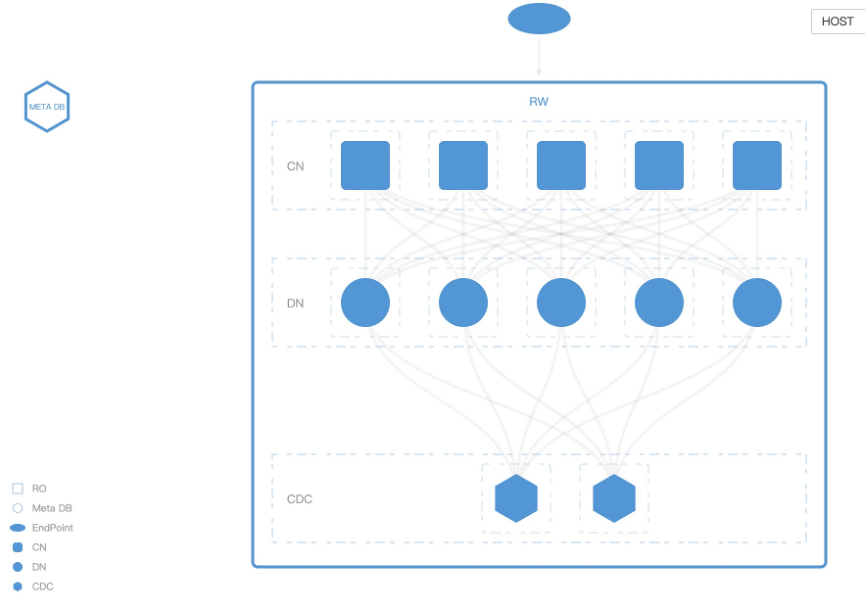
Oceanbase

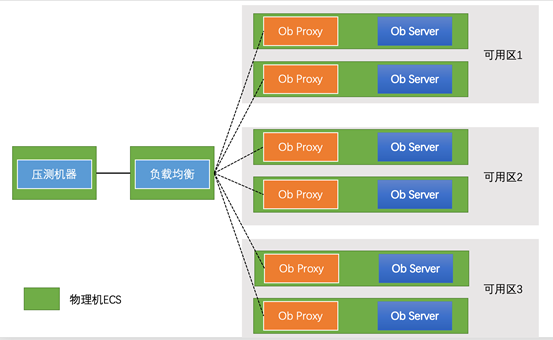
TiDB
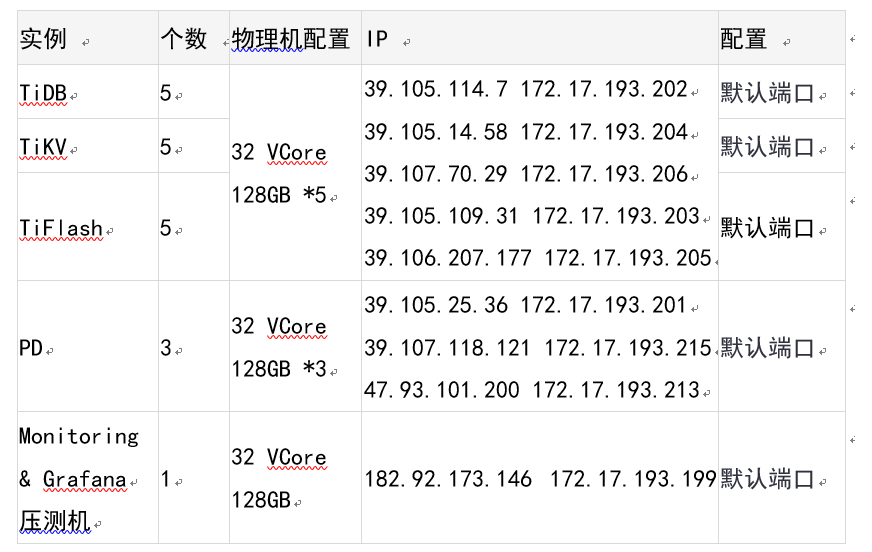
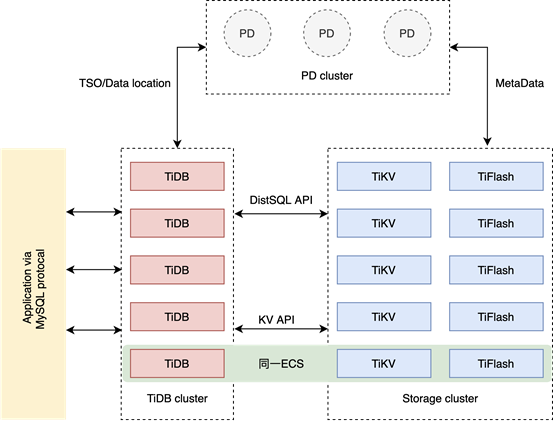

Sysbench压测情况:
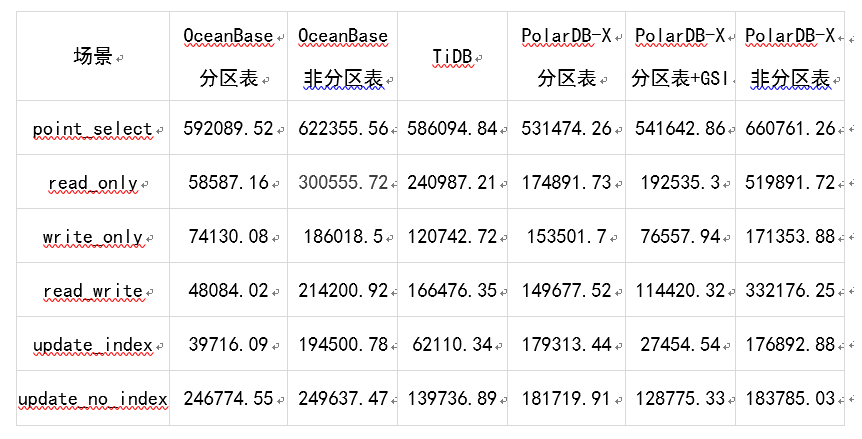
测试表结构:CREATE TABLE `sbtest1` (`id` int(11) NOT NULL,`k` int(11) NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',`pad` char(60) NOT NULL DEFAULT'',PRIMARY KEY (`id`),KEY `k_1` (`k`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
总计16 张表,每张表 1000 万行数据,数据分布uniform。 TiDB场景:基于range水平拆分模式的分布式(TiDB默认会把所有表的数据按照range做自动均衡,某一张测试表的数据会均匀分布到多个机器上)。 OB模式:单表即官网默认推荐模式,sysbench脚本不作修改时自动建立的表,这里简称非分区表;基于hash水平拆分模式的分布式,简称分区表。 PolarDB-X场景:单表,sysbench脚本不作修改时自动建立的表,这里简称非分区表;基于hash水平拆分模式的分布式,简称分区表,索引采用本地索引;基于hash水平拆分模式的分布式,简称分区表,索引采用GSI全局索引。
TPCC (5000仓)
// 数据导入 5000仓tiup bench tpcc --warehouses 5000 -D tpcc -H xxx -P xxx -T threads_num prepare// 运行tiup bench tpcc run -U root --db tpcc2 --host xxx --port xxx --time xxx --warehouses 5000 --threads

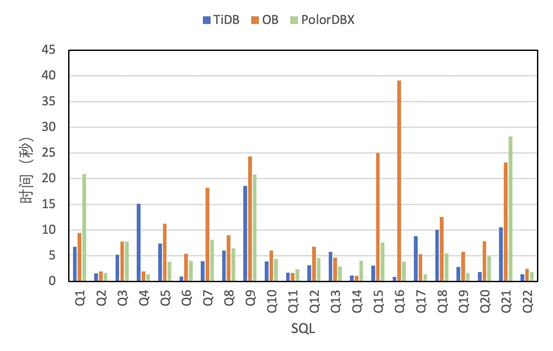
TPCH (100G)
// 导入数据 100Gtiup bench tpch prepare --host xxx --port xxx --db tpch_100 --sf 100 --analyze --threads xxx// runtiup bench tpch run --host xxx --port xxx --db tpch_100 --sf 100 --check=true
DDL 能力


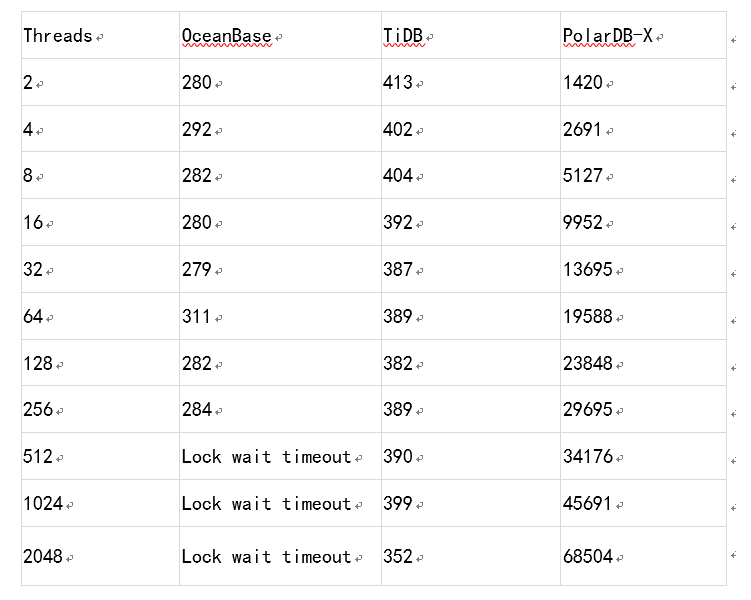
热点行更新
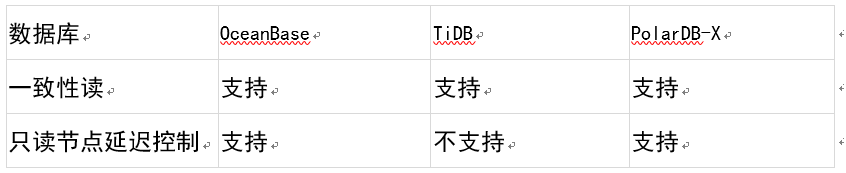
读写分离
分区变更特性

特殊场景
测试数据为tpch100g 生成的lineitem表,单表6亿行数据select * from lineitem;update lineitem set L_PARTKEY=L_PARTKEY+1;






TiDB:
OceanBase:
PolarDB-X:


点击“阅读原文”了解PolarDB-X更多信息
最后修改时间:2021-09-15 11:06:02
文章转载自阿里云数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
