




我们进行数据处理的时候经常会涉及到各种聚合函数的应用,比如计数(count)、求和(sum)这类聚合函数,需要分组统计的时候我们很容易就能想到用group by进行分组。
但是使用聚合函数,会按分组条件将多行记录聚合成一行,每组只返回一个值;并且在使用聚合函数后,如果要显示相关列必须将其加入到group by语句中。这样就会导致有些查询语句只能通过编写复杂的子查询或者存储过程来完成。
于是2003年ISO SQL标准加入了开窗函数(Window Function),与聚合函数一样,开窗函数也是对组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值并在每一行的最后一列添加聚合函数的结果,使用起来非常方便。
开窗函数基本语法:
<开窗函数>
over ([partition by <用于分组的字段>]
order by <用于排序的字段>)
重点注意:
PARTITION BY用于将结果集进行分组,ODER BY 指定按哪个字段进行排序;
在同一个SELECT语句中,可以同时使用多个开窗函数,而且这些开窗函数并不会相互干扰。
聚合开窗函数 排名开窗函数 定位开窗函数 分布开窗函数
CREATE TABLE Temp_Test (UserName VARCHAR(20),City VARCHAR(20),Age INT,Salary INT)INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Tom','BeiJing',20,3000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Tim','ChengDu',21,4000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Jim','BeiJing',22,3500);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Lily','London',21,2000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('John','NewYork',22,1000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('YaoMing','BeiJing',20,3000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Swing','London',22,2000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Guo','NewYork',20,2800);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('YuQian','BeiJing',24,8000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Ketty','London',25,8500);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Kitty','ChengDu',25,3000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Merry','BeiJing',23,3500);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Smith','ChengDu',30,3000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Bill','BeiJing',25,2000);INSERT INTO Temp_Test(UserName,City,Age,Salary) VALUES('Jerry','NewYork',24,3300);
得到的数据如下:
SQL标准允许将所有聚合函数用作开窗函数,使用 OVER 关键字来区分这两种用法。OVER关键字表示把函数当成开窗函数而不是聚合函数。
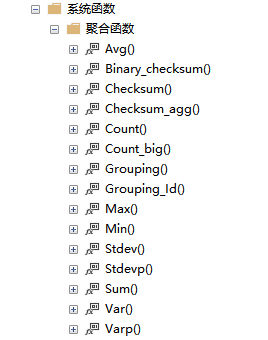
select UserName,City,Age,Salary,sum(Salary) over(order by Salary desc) '工资'from Temp_Test
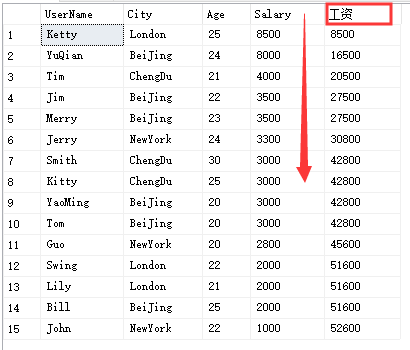
select UserName,City,Age,Salary,sum(Salary) over(partition by City order by Salary desc) '工资'from Temp_Test
ROW_NUMBER(唯一行号)
select UserName,City,Age,Salary,ROW_NUMBER() over(order by Salary desc) '工资排名'from Temp_Test
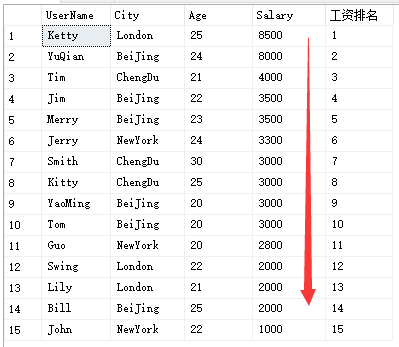
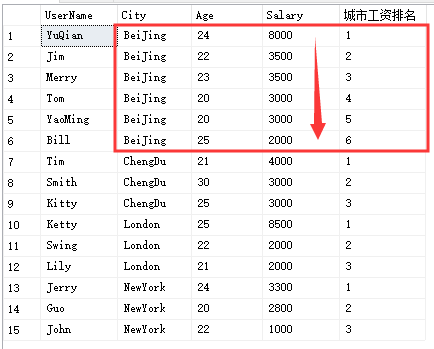
select UserName,City,Age,Salary,ROW_NUMBER() over(partition by City order by Salary desc) '城市工资排名'from Temp_Test
RANK(排名)
RANK()按照ORDER BY的排序,如果有相同的值,会生成不同的序号并且接下来的序号是不连续的。
例如两个相同的行生成序号2,那么接下来会生成序号4。
DENSE_RANK(密集排名)
和RANK类似,不同的是如果有相同的序号,那么接下来的序号不会间断。例如两个相同的行生成序号2,那么接下来生成的序号还是3。
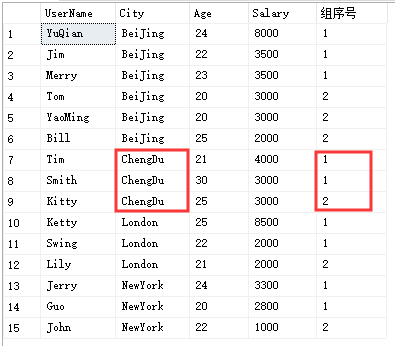
NTILE (分组排名)
select UserName,City,Age,Salary,NTILE(2) over(partition by City order by Salary desc) '组序号'from Temp_Test
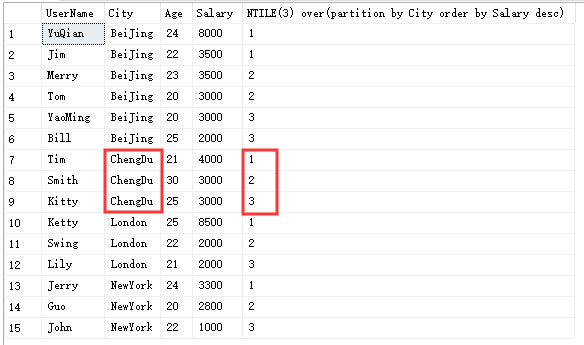
那我们来看一下若是分成3组是如何分的:
再来看一下若是分成4组是如何分的:
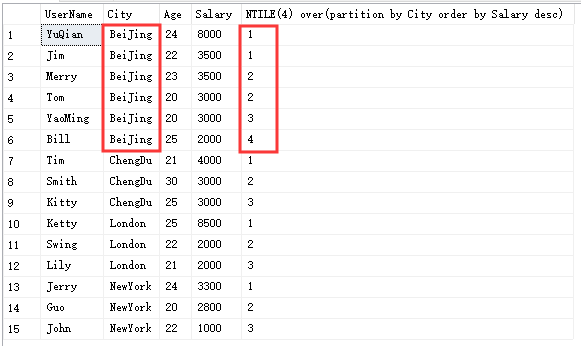
再来看一下若是分成5组是如何分的:
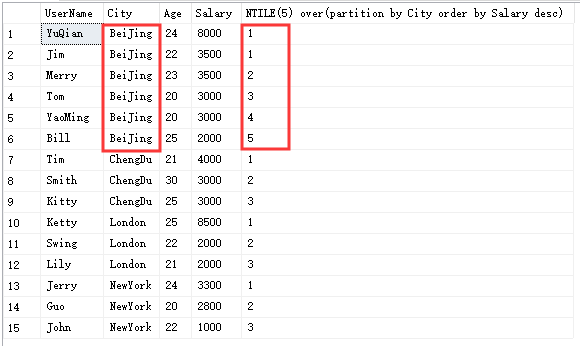
▍定位开窗函数
LAG()
LAG(COL,N,DEFAULT_VALUE) 用于统计窗口内往上第N行的值,第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(即往上第N行是NULL的时候,显示默认值,如不指定,则显示NULL)。
select UserName,City,Age,Salary,LAG(Salary,2) over(partition by City order by Age) '未指定默认值',LAG(Salary,2,999) over(partition by City order by Age) '指定默认值为999'from Temp_Test
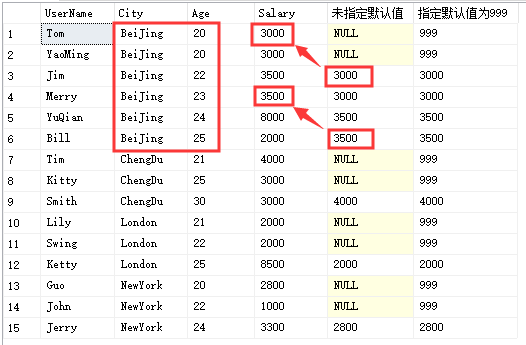
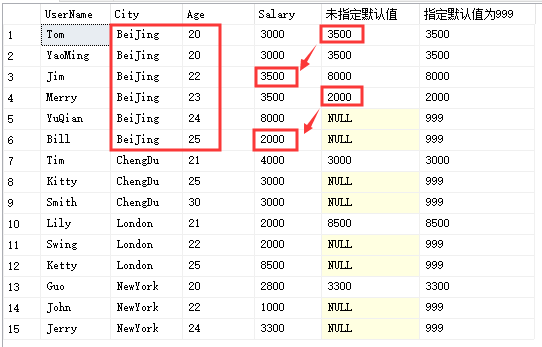
LEAD()
select UserName,City,Age,Salary,LEAD(Salary,2) over(partition by City order by Age) '未指定默认值',LEAD(Salary,2,999) over(partition by City order by Age) '指定默认值为999'from Temp_Test
FIRST_VALUE
select UserName,City,Age,Salary,FIRST_VALUE(Salary) over(partition by City order by Age) '组内排序后第一个值'from Temp_Test
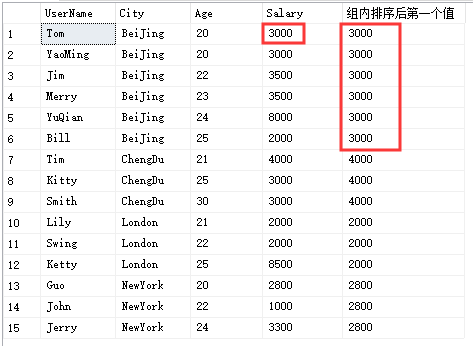
LAST_VALUE
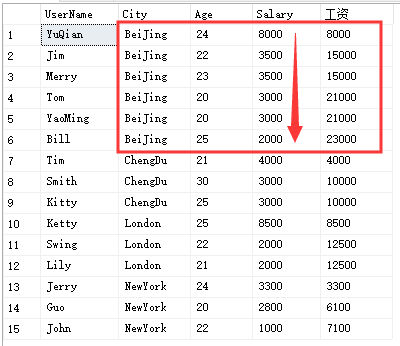
select UserName,City,Age,Salary,LAST_VALUE(Salary) over(partition by City order by Age) '组内排序后的最后一个值'from Temp_Test
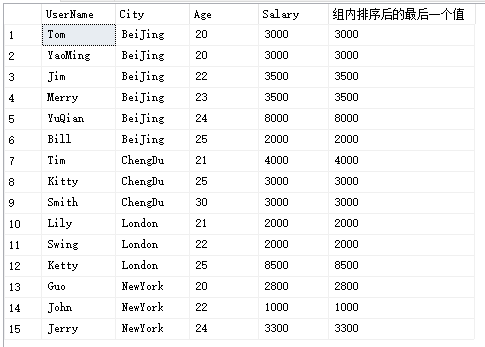
解析:我们可能会有疑问,跟我们想象中的“组内排序后的最后一个值”似乎不太一样,我们想象中的BeiJing这个组内排序后的最后一个值应该是2000。
但是,其实上图中得出的结果确定是符合LAST_VALUE的逻辑的。
我们从第1行看起,第1行的Salary为3000,截止到当前行的最后一个值也为3000,第2行的Salary为3000,截止到当前行的最后一个值其实变成了第2行的Salary值3000,第3行的Salary值为3500,截止到当前行的最后一个值随着变成了第3行的值3500......。
我们再来看组间的过度,比如第六行的最后一个值为2000,第七行是ChengDu组内的第1行,截止到当前行的最后一个值也正是第一行的4000......。
这里我们要特别注意的是截止到当前行这个条件。
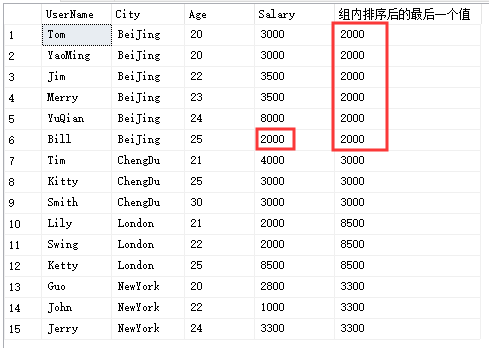
如果想取得分组内排序后的最后一个值,则需要变通一下:
select UserName,City,Age,Salary,FIRST_VALUE(Salary) over(partition by City order by Age DESC) '组内排序后的最后一个值'from Temp_TestORDER BY City,Age
▍分布开窗函数
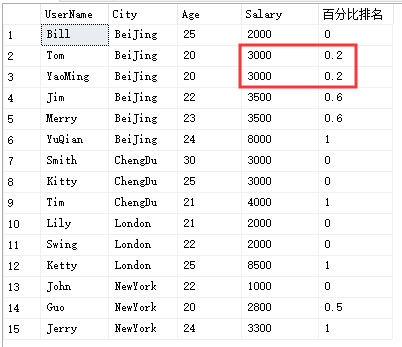
PERCENT_RANK()
计算一个值在查询结果集或分区中的百分比排名。
select UserName,City,Age,Salary,PERCENT_RANK() over(partition by City order by Salary) '百分比排名'from Temp_Test
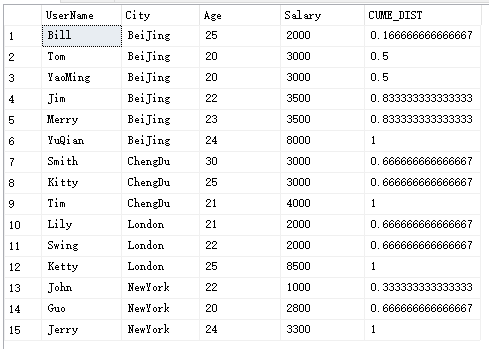
CUME_DIST
计算某个值在一组值内的累积分布。
返回值范围为(0,1]。
select UserName,City,Age,Salary,CUME_DIST() over(partition by City order by Salary) 'CUME_DIST'from Temp_Test
----------------------

