




2021 年 7 月 20 日,我们庆祝了MySQL NDB Cluster 8.0.26的发布。MySQL NDB Cluster(或简称 NDB)是 MySQL 开源产品系列的一部分,提供内存中、分布式、无共享、高可用性的存储引擎,可单独使用或与 MySQL 服务器作为前端使用。有关完整的变更集,请参阅发行说明。在这里下载。
选择一个数据库可以是压倒性的牛逼要求,需要考虑性能(吞吐量和延迟),高可用性,数据容量,可扩展性,易用性/操作等,这些因素由数据库运行在那里的影响-无论是在云提供商,例如Oracle 云基础设施,提供范围广泛的基础设施,从小型虚拟机(VM) 到大型裸机(BM) 实例,以及高性能计算 (HPC) 服务器或自己的本地硬件。
以最佳性能为目标时,数据库可能是复杂的野兽,需要理解和试验数百种不同的调整参数。通过更深入一层,进入操作系统,调整内核设置以最好地匹配数据库要求,可以使这项任务变得更加复杂。最后,针对特定工作负载完成数据库调优,在运行不同工作负载时,相同的调优设置可能会导致性能欠佳——这是另一种复杂情况。所有这一切都可以同时带来很多乐趣和痛苦。
我们能否以一种简单的方式实现一个高性能、高可用的集群?
有了全新的高端Dell EMC PowerEdge R7525服务器、带 2 TB RAM 的双插槽AMD EPYC 7742和四个 3TB NVMe SSD,我们开始探索如何轻松设置高性能、高与新发布的 MySQL NDB Cluster 8.0.26 在一个盒子中的可用集群。
提前回答这个问题 - 是的 - 使用 sysbench OLTP 点选择基准测试,我们可以使用两个数据节点集群轻松实现每秒超过 150 万次主键查找的恒定吞吐量,每个数据节点配置有 32 个 CPU,使用总共 16 个 MySQL 服务器和 1024 个客户端(sysbench 线程)。
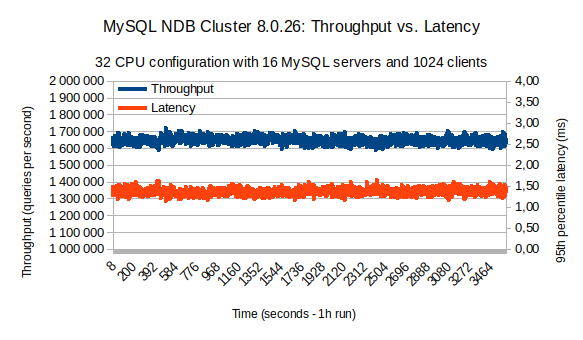
上图显示了 1 小时的长期运行结果。查看蓝线,我们可以看到每秒 1.6-170 万次查询(主键查找)范围内的恒定吞吐量。最大记录吞吐量为每秒 1,716,700 次主键查找。同样重要的是第 95 个百分位数的延迟,即红线,它在 1.1-1.6 毫秒的范围内,平均为 1.35 毫秒。
那么为这些结果配置 MySQL NDB Cluster 有多容易?这很简单!在以下部分中,我们将详细描述硬件、NDB 配置、基准测试设置以及导致这些性能数字的中间结果分析。
硬件设置
我们所有的测试都在配置了以下配置的单个 Dell EMC PowerEdge R7525 服务器上运行:
- 双第二代 AMD EPYC 7742 (Rome) 64 核处理器、128 线程、7nm 设计、最大时钟速度 3900 MHz 和 256 MB 缓存
- 32 x 64 GB DDR4 调光器(SK Hynix),3200 MT/s 速度,总共 2 TB RAM
- 4 个 3.2TB NVMe 驱动器(Dell Express Flash PM1725b)
通过选择Oracle Cloud Infrastructure (OCI) 中当前提供的BM.Standard.E3.128形状,可以使用类似的规范服务器。有关可用形状及其规格的列表,请参见此处。
该服务器安装了使用内核版本 5.4.17 (2021.7.4) 的 Oracle Linux Server 8.3。
基准测试设置
我们所有的基准测试都是使用https://github.com/akopytov/sysbench提供的 sysbench 1.1.0 版本运行的。出于透明度和可重复性的目的,没有对基准代码进行任何更改。我们选择使用 sysbench,因为它是众所周知且易于使用的基准,用于评估不同负载场景下的数据库性能。
我们的数据集使用 8 个表和每个表 10M 行,使用大约 60GB 的内存。此配置是 MySQL 团队(对于 InnoDB 和 NDB Cluster 存储引擎)完成的许多基准测试的最常见起点。数据足够大,不仅可以仅在 CPU 缓存上运行,也不能大到涉及过多 IO 活动(例如,长时间节点重新启动或数据集初始化)。
我们使用 OLTP 点选择工作负载,该工作负载由返回常量字符串值的主键查找查询组成。此工作负载测试完整的数据库堆栈(MySQL 服务器和 NDB 存储引擎)以获得整体代码效率和最佳查询执行延迟。密钥生成是使用默认的均匀分布算法完成的。Sysbench 与数据库在同一台机器上运行,通过 Unix 套接字连接到 MySQL 服务器。
MySQL NDB 集群设置
推荐的最小高可用性场景需要 4 台主机:2 台主机运行数据节点,2 台主机运行管理节点和 MySQL 服务器或应用程序(请参阅常见问题解答)。在这种情况下,任何主机都可以不可用而不会影响服务。通过运行两个数据节点和多个 MySQL 服务器或应用程序,可以支持使用单盒设置软件级冗余。在这种场景下,我们可以在不影响服务的情况下进行在线升级等在线操作。
为了利用我们正在使用的服务器,我们可以为每个数据节点和一组 MySQL 服务器平均分配机器资源。
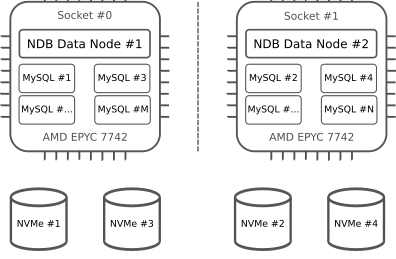
使用双插槽服务器的 MySQL NDB Cluster “Cluster-in-a-box”设置
在此设置中,我们为每个插槽(物理 CPU)使用一个 NUMA 节点。服务器支持为每个插槽配置多达 4 个 NUMA 节点(总共 8 个 NUMA 节点——有关详细信息,请参阅AMD 调优指南)。对于每个 NUMA 节点,我们运行单个数据节点和平衡数量的 MySQL 服务器,访问可用内存的一半。请注意,尽管 MySQL NDB 是内存数据库,但默认情况下启用磁盘检查点(和推荐设置)。在我们的设置中,所有 NVMe 磁盘仅可从单个 NUMA 节点获得(理想情况下,每个 NUMA 节点将拥有一半的磁盘)。
定义集群拓扑后,使用两个数据节点和多个 MySQL 服务器,下一步是定义分配给 NDB 和 MySQL 服务器进程的 CPU 资源数量。我们发现 25/75 的 CPU 分配提供了一个很好的起点。
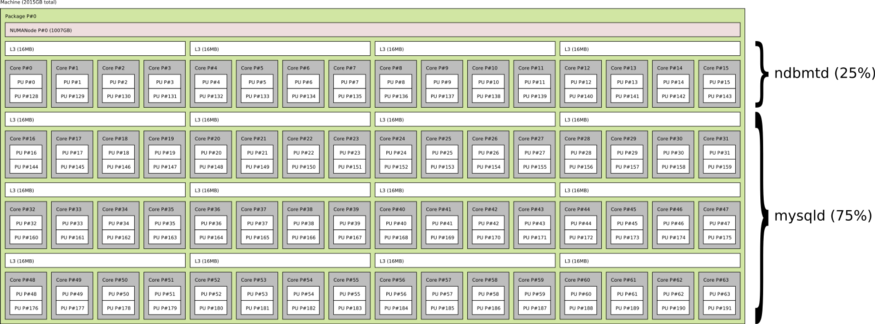
为 NDB (ndbmtd) 分配 25% 的 CPU,为 MySQL 服务器 (mysqld) 进程分配剩余的 75%
MySQL NDB Cluster 被设计为非常高效,并且它需要的资源比 MySQL 服务器少是很自然的。资源的实际分配将取决于工作负载。在查询可以推送到数据节点的情况下,为 NDB 保留更多 CPU 是有意义的。在执行 SQL 级别聚合或函数的情况下,MySQL 服务器需要更多 CPU。
通过上述资源分配,对于每个套接字(物理 CPU),我们将为 NDB 数据节点(ndbmtd)进程保留 16 个内核(32 个线程),为 MySQL 服务器(mysqld)进程保留 48 个内核(96 个线程)。
主要的 NDB Cluster 配置是:
此配置的关键要素是:
- NoOfReplicas:定义集群中存储的每个表的分片副本数。有两个数据节点,这意味着每个节点都将包含所有数据(确保在任何数据节点宕机时的冗余)。
- DataMemory:用于存储内存数据的内存量。我们在基准测试中将其设置为 128G,但我们可以将其增加到 768G,因为我们每个数据节点有 1TB 的可用 RAM(仍然为操作系统留有很大的余量)。
- AutomaticThreadConfig:启用后,允许数据节点定义要运行的 NDB 特定线程。
- NumCPUs:限制要使用的逻辑 CPU 的数量。我们已将其设置为 32,这意味着我们希望 NDB 能够利用可用的 16 核/32 线程。
- NoOfFragmentLogParts:可选配置,设置每个节点并行REDO日志的数量。我们将其设置为 8,因为使用 NumCPUs=32 时将有 8 个 LDM 线程。这使得每个 LDM 线程都可以在不使用互斥锁的情况下访问 REDO 日志片段——从而稍微提高性能。
- LockPagesInMainMemory:防止交换到磁盘,确保最佳性能。我们已设置为 1,即在为进程分配内存后锁定内存。
- UseShm:启用数据节点和 MySQL 服务器之间的共享内存连接。当将 MySQL 服务器与数据节点共置时,这是必须的,因为它提供了 20% 的性能改进。
其他配置选项仅在运行用于在数据库中填充数据的 sysbench prepare 命令时才需要。它们在运行 OLTP 点选择工作负载时没有影响,但可能对其他工作负载产生影响。
管理节点和数据节点的特定选项是:
[ndb_mgmd] NodeId = 1 HostName = localhost DataDir = /nvme/1/ndb_mgmd.1 [ndbd] NodeId = 2 HostName = localhost DataDir = /nvme/1/ndbd.1 [ndbd] NodeId = 3 HostName = localhost DataDir = /nvme/2/ndbd.2
这些选项定义了一个管理节点和两个数据节点。对于每个,我们设置唯一标识符 (NodeId)、它们将运行的主机 (HostName)、设置为 localhost,最后设置存储所需文件的路径 (DataDir)。
NDB 进程所需的最终配置是添加允许 MySQL 服务器和 NDB 工具连接到集群所需的 API 节点。这些配置的摘录是:
[mysqld] NodeId = 11 HostName = localhost ... [api] NodeId = 245 ...
有关数据节点配置参数的完整列表,请参见此处。
最后,MySQL服务器配置如下:
[mysqld] ndbcluster ndb-connectstring=localhost max_connections=8200 # Below three options are for testing purposes only user=root default_authentication_plugin=mysql_native_password mysqlx=0 [mysqld.1] ndb-nodeid=11 port=3306 socket=/tmp/mysql.1.sock basedir=/nvme/3/mysqld.1 datadir=/nvme/3/mysqld.1/data [mysqld.2] ndb-nodeid=12 port=3307 socket=/tmp/mysql.2.sock basedir=/nvme/4/mysqld.2 datadir=/nvme/4/mysqld.2/data ...
[mysqld] 下指定了三个重要的设置,所有 MySQL 都需要这些设置。那些是:
- ndbcluster:启用 NDB Cluster 存储引擎;
- ndb-connectstring:显式设置用于连接到 NDB Cluster 的所有管理节点的地址和端口。在我们的例子中,管理节点在本地运行,这个设置是可选的;
- max_connections:可选,在大量客户端运行基准测试时需要;
对于每个 MySQL 服务器,我们至少需要为 port、socket、basedir 和 datadir 定义单独的配置。
完整的配置文件和说明可从https://github.com/tiagomlalves/epyc7742-ndbcluster-setup获得
运行 MySQL NDB Cluster、MySQL 服务器和 sysbench
为了运行 MySQL NDB Cluster 和 MySQL Server,我们假设所有包都安装在系统中并且在路径中可用。我们假设系统中已经编译安装了sysbench。
我们使用 numactl 根据上面定义的设置来设置与特定 CPU / NUMA 节点的进程关联,其中我们为 NDB 数据节点保留 25% 的 CPU 容量,为其他进程保留 75% 的 CPU 容量。
运行管理节点:
$ numactl -C 60-63,188-191,124-127,252-255 \
ndb_mgmd \
--ndb-nodeid=1 \
--configdir="/nvme/1/ndb_mgmd.1" \
-f mgmt_config.ini
请注意,管理节点(ndb_mgmd)消耗的资源非常少,可以从任何逻辑 cpu 运行。上述 numactl 设置允许 ndb_mgmd 从任何 NUMA 节点中的任何 CPU 运行,除了为数据节点保留的那些。
运行数据节点:
$ numactl -C 0-15,128-143 \
ndbmtd --ndb-nodeid=2
$ numactl -C 64-79,192-207 \
ndbmtd --ndb-nodeid=3
nodeid 为 2 的第一个数据节点在第一个 NUMA 节点(NUMA #0)的前 16 个内核中运行,因此亲和性设置为 CPU 0-15 和 128-143。
nodeid 为 3 的第二个数据节点在第二个 NUMA 节点(NUMA #1)的前 16 个内核中运行,因此亲和性设置为 CPU 64-79 和 192-207。
运行 MySQL 服务器:
$ numactl -C 16-63,144-191 \
mysqld \
--defaults-file=my.cnf \
--defaults-group-suffix=.1
$ numactl -C 80-127,208-255 \
mysqld \
--defaults-file=my.cnf \
--defaults-group-suffix=.2
每个 NUMA 节点运行多个 MySQL 服务器。我们决定在 NUMA #0(CPU 16-63 和 144-191)中运行所有奇数 MySQL 服务器,在 NUMA #1(CPU 80-127 和 208-255)中运行偶数 MySQL 服务器。同一 NUMA 节点中的多个 MySQL 服务器将共享除为数据节点保留的 CPU 之外的所有 CPU。可以让每个 MySQL 服务器进程在一组专用的 CPU 中运行,以防止进程之间共享 CPU 资源。这种方法需要仔细验证,稍后将讨论。
运行 sysbench:
$ THREADS=1024 ; \
MYSQL_SOCKET=/tmp/mysql.1.sock,/tmp/mysql.2.sock,... ; \
numactl -C 16-63,144-191,80-127,208-255 \
sysbench \
--db-driver=mysql \
--mysql-storage-engine=ndbcluster \
--mysql-socket="${MYSQL_SOCKET}" \
--mysql-user=root \
--tables=8 \
--table-size=10000000 \
--threads="${THREADS}" \
--time=300 \
--warmup-time=120 \
--report-interval=1 \
oltp_point_select run
我们使用 Unix 套接字在与 MySQL NDB Cluster 和 MySQL 服务器相同的机器上运行 Sysbench。然而,在典型的场景中,应用程序和数据库从不同的地方运行,因此需要改用 TCP/IP 网络堆栈。在这种情况下,预计性能会低于我们在此处报告的性能。
我们所有的跑步持续时间为 300 秒(5 分钟),热身时间为 120 秒(2 分钟)。在实践中,我们已经看到,预热时间为 2 分钟,运行基准测试 1-2 分钟就足够了。我们已经验证运行基准测试超过 1 小时,记录的平均吞吐量没有显着变化。
扩展单个 MySQL 服务器
对 MySQL NDB Cluster 进行基准测试时,我们的第一步是从单个 MySQL 服务器开始。这让我们对我们正在测试的特定工作负载有一个基本的了解,帮助我们了解如何分配资源和微调进一步的参数。
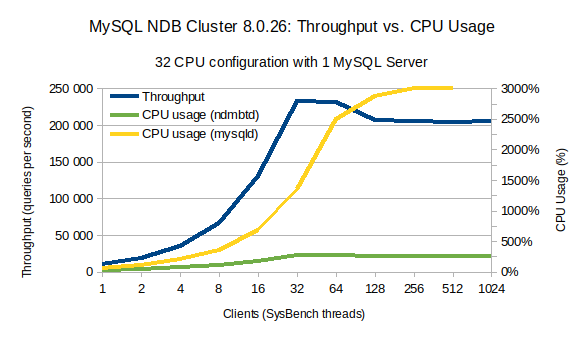
使用单个 MySQL 服务器运行 MySQL NDB Cluster。使用 32 个客户端(sysbench 线程)可实现最大吞吐量。超过 32 个客户端 MySQL 瓶颈导致性能下降。
在上图中,我们显示了吞吐量(以每秒查询次数为单位),以蓝色表示,NDB 数据节点 (ndbmtd) 的 CPU 利用率以绿色表示,MySQL 服务器 (mysqld) 以黄色表示。吞吐量比例显示在左侧 y 轴中。CPU 利用率显示在右侧的 y 轴中。在 x 轴上,我们显示了每次运行使用的客户端(sysbench 线程)数量。
该图表显示,当客户端从 1 增加到 32 时,吞吐量和 mysqld CPU 利用率相应增加。在相同范围内,ndbmtd CPU 利用率仅略有增加。
在 32 个客户端时,我们达到了每秒约 23 万次查询的最大吞吐量。MySQL 服务器 (mysqld) CPU 利用率约为 1400%,这意味着总共使用了 14 个逻辑 CPU。
从 32 到 64 个客户端,我们看到 mysqld CPU 利用率几乎翻了一番(2500% — 25 个逻辑 CPU),导致吞吐量略有下降。从 64 个客户端到 128 个,我们看到吞吐量进一步下降,mysqld 的 CPU 利用率曲线变平,这意味着 MySQL 服务器已饱和。在此阶段,mysqld 使用了可用的 96 个逻辑 CPU(48 个内核/96 个线程)中大约 3000% 的 CPU(30 个逻辑 CPU)。从 128 个客户端开始,吞吐量或 CPU 利用率不再增加。
该图表意味着使用单个 MySQL 服务器进行 OLTP 点选择工作负载的最佳吞吐量条件发生在 32 个客户端,而我们达到了 MySQL 服务器的最大值的大约 64 个客户端。
我们知道瓶颈在 MySQL 服务器而不是在 NDB Cluster 中,因为 NDB 利用率相当低。这可以使用 ndb_top 工具看到:
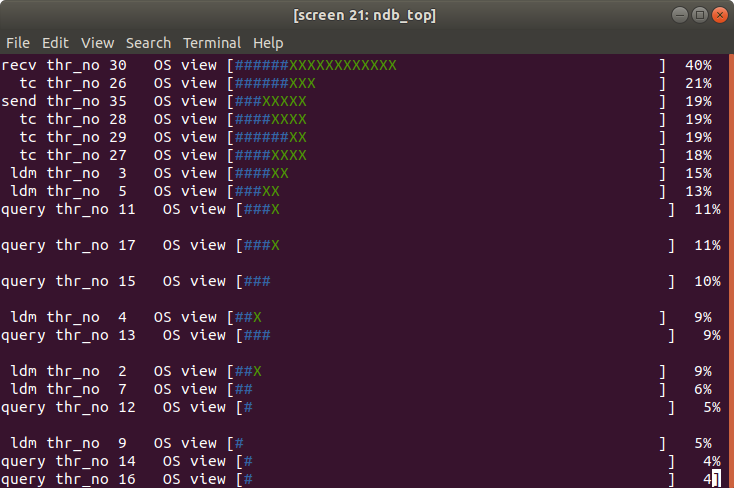
ndb_top 工具显示 MySQL NDB Cluster 线程 cpu 利用率,同时针对单个 MySQL 服务器运行具有 1024 个客户端(SysBench 线程)的 SysBench。图像显示“recv”线程的 CPU 利用率为 40%,所有其他线程都处于空闲状态。
上面的屏幕截图显示了不同 NDB 线程(ldm、query、tc、send、recv 和 main)的 CPU 利用率。有关 NDB 内部结构的更多信息,请参见此处。从我们的配置中,我们知道我们有 3 个 recv 线程,但我们只有 40% 的一个线程,其余的空闲。我们还看到,大多数其他线程的利用率都低于 80%。这证实了瓶颈在 MySQL 服务器端,而不是在 NDB。
为了解决 MySQL 的瓶颈,我们可以简单地增加 MySQL 服务器的数量。如上所示,当 MySQL 服务器使用 14 个逻辑 CPU 的 32 个客户端时,吞吐量的最佳条件发生。考虑到我们每个套接字有 48 个内核/98 个线程,我们每个套接字可以有 ~98/14 = 7 个 MySQL 服务器。总结起来,每个套接字大约有 8 个 MySQL 服务器。
扩展多个 MySQL 服务器
当单个 MySQL 服务器饱和时,我们可以通过添加更多 MySQL 服务器来继续扩展。之前我们估计每个套接字最多可以使用 8 个 MySQL 服务器,或者总共 16 个 MySQL 服务器。
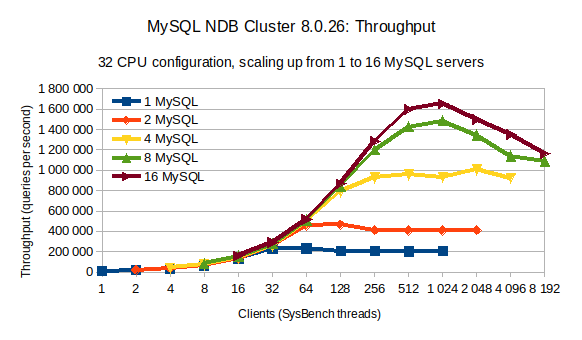
显示使用不同数量的 MySQL 服务器和客户端(sysbench 线程)实现的吞吐量。当使用 1024 个客户端和总共 16 个 MySQL 服务器时,我们达到了最大吞吐量。
上图显示了对 1 到 16 个 MySQL 服务器使用越来越多的客户端(sysbench 线程)进行的一系列测试。在此图表中,我们记录了 300 秒内每秒的平均查询次数。该图表显示,在 32 个客户端之后,我们需要将 MySQL 服务器的数量增加一倍,以通过更多客户端(sysbench 线程)来维持不断增加的吞吐量。这是我们所期望的。另请注意,当 MySQL 服务器从 8 台增加到 16 台时,我们不再能够将吞吐量翻倍。
使用 1024 个客户端(sysbench 线程)的 16 个 MySQL 服务器达到最大吞吐量。当添加额外的客户端时,吞吐量开始下降,这意味着系统变得饱和。
同样有趣的是查看为不同数量的 MySQL 服务器运行越来越多的客户端时的延迟。
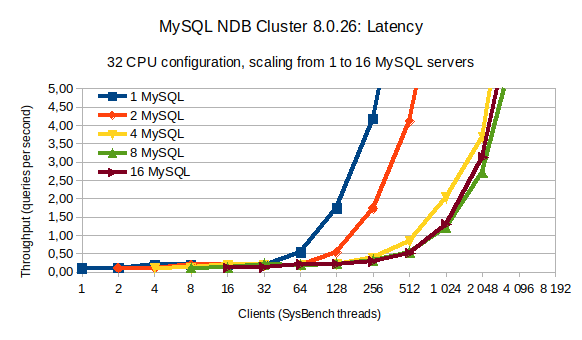
显示使用不同数量的 MySQL 服务器和客户端(sysbench 线程)记录的第 95 个百分位延迟。我们看到的吞吐量与吞吐量相同,添加更多 MySQL 服务器可确保越来越多的客户端(sysbench 线程)的低延迟,直到系统开始变得饱和。
使用单个 MySQL 服务器时,第 95 个百分位延迟低于 0.5ms,最多 32 个客户端(sysbench 线程),然后在使用更多客户端时呈指数增长。将 MySQL 服务器的数量加倍允许将客户端(sysbench 线程)的数量加倍,同时保持低于 0.5 毫秒的相同低延迟。然而,当使用 8 个或更多 MySQL 服务器时,我们不能再使用 512 个或更多客户端将延迟保持在 0.5 毫秒以下——这意味着系统开始饱和。还要注意,使用总共 8 台或 16 台 MySQL 服务器之间的延迟没有显着差异(16 台服务器比 2048 台或更高版本的客户端稍差)。
上图显示了完整运行的平均吞吐量和第 95 个百分位数的延迟。这些聚合值提供的关于运行期间吞吐量和延迟稳定性的信息很少。这显示如下:
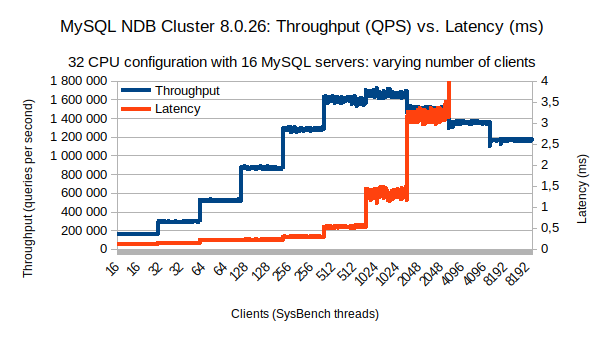
比较不同数量的客户端(SysBench 线程)的吞吐量(以每秒查询数衡量)和延迟(以毫秒为单位),使用 2 个数据节点集群和 16 个 MySQL 服务器在高端 Dell EMC PowerEdge R7525 服务器上运行,具有双-socket AMD EPYC 7742、2TB 内存和 NVMe 磁盘。最高吞吐量略高于 1.6M QPS。延迟低于 1 毫秒,最多 512 个客户端。
上图显示了使用 16 个 MySQL 服务器为越来越多的客户端(sysbench 线程)每秒采样的平均吞吐量(蓝色)和 95% 延迟(红色)。对于吞吐量和延迟,除非我们达到系统饱和,否则两者都非常稳定。在吞吐量的情况下,即使延迟超过 0.5 毫秒,我们也可以观察到稳定的吞吐量,这是内存数据库所预期的。
超过 170 万 QPS
使用此集群配置和工作负载,每秒可以处理超过 170 万次查询。还可以通过微调操作系统设置来进一步减少测量值的变化。然而,这不再是一项需要试验其他配置参数的简单任务,超出了本博客的范围。
无论如何,为了给您有关可能的后续步骤的提示,我们可以从查看 ndb_top 的输出开始:

这证实了现在整个系统的瓶颈是 NDB 集群。更准确地说,tc 线程的 CPU 利用率达到了 80%。尽管如此,其他线程离饱和还很远,这为进一步优化留下了空间。
当启用 AutomaticThreadConfig 并配置 NumCPUs=32 时,NDB 将使用 8 个 ldm、8 个查询、4 个 tc、3 个发送、3 个接收和 1 个主线程。从上面可以看出,tc线程已经饱和,但是ldm+query线程仍然没有被充分利用。为了进一步尝试改进查询执行,我们可以手动设置要使用的线程数,减少 ldm+query 线程的数量并添加更多 tc 线程。但是,我们将把它留给另一篇博文!
结论
MySQL NDB Cluster 的开发目标是实现水平扩展。然而,随着高端硬件的不断改进,有一个简单的方法来扩展数据库是很重要的。此博客提供了有关如何以简单的方式扩展 MySQL NDB Cluster 8.0.26 的介绍性演练,报告每秒超过 1.7M 的主键查找。
MySQL NDB Cluster 是一个开源分布式内存数据库。它结合了线性可扩展性和高可用性,提供内存实时访问以及跨分区和分布式数据集的事务一致性。它旨在支持需要高可用性(99.999% 或更高)和可预测查询时间的场景。
