




介绍
雪花算法用于分布式服务生成唯一序列ID。最早是twitter内部使用的生成分布式id的算法。
优点:
全局唯一性:可以在几十年内不会重复,具体根据时间戳的位数而定
趋势递增:可以保证有序
信息安全:ID不连续保证无法根据id推断其他id
原理

第1位:数字符号位。这个大家应该都理解
第2~42位:时间戳位数。41位可以用69年。
第43~52位:机器编号。10位可供1024台机器服务。
第53~64位:可供一台机器每毫秒产生4096个序列号。
当然了,除第一位外的分布可以根据业务自行增减占用位数。
Java实现
twitter是由scala实现的,下面是根据此改写的java实现:
public class SnowFlake { //机器id位数 private final long workerIdBits = 5L; //数据中心位数 private final long datacenterIdBits = 5L; //最大机器id private final long maxWorkerId = ~(-1L << workerIdBits); //最大数据中心id private final long maxDatacenterId = ~(-1L << datacenterIdBits); //序列号位数 private final long sequenceBits = 12L; //机器id左移位数 private final long workIdShift = sequenceBits; //数据中心id左移位数 private final long datacenterShift = workIdShift + workerIdBits; //时间戳左移位数 private final long timestampLeftShift = datacenterShift + datacenterIdBits; //序列号最大值,用来判断序列号是否达到最大值 private final long sequenceMask = ~(-1L << sequenceBits); //上一次生成id的时间戳 private long lastTimestamp = -1L; //机器id private long workerId; //数据中心id private long datacenterId; //序列号 private long sequence; //开始时间的时间戳,id多少年内不重复以此时间戳开始计算 private long beginTimestamp = 1631265010361L; /** * 构造函数 * @param datacenterId * @param workerId * @return null * @author Wang Qingcheng * @since 2021/9/13 */ public SnowFlake(long datacenterId, long workerId) { //判断机器id的有效性 if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } //判断数据中心id的有效性 if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId)); } this.workerId = workerId; this.datacenterId = datacenterId; } /** * 获取id * @return long * @author Wang Qingcheng * @since 2021/9/13 */ public synchronized long nextId() { long genTimestamp = System.currentTimeMillis(); //判断当前时间的有效性,不能小于上次生成id的时间 if (genTimestamp < lastTimestamp) { throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - genTimestamp)); } if (lastTimestamp == genTimestamp) { //当前时间戳和上次生成id一样 //如果序列号+1大于序列号最大值,则归0 sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { //序列号归0的话等下一毫秒 genTimestamp = tilNextMillis(lastTimestamp); } } else { //当前时间戳和上次生成id不一样,序列号归0 sequence = 0; } lastTimestamp = genTimestamp; //时间戳左移|数据中心id左移|机器id左移|序列号 return ((genTimestamp - beginTimestamp) << timestampLeftShift) | (datacenterId << datacenterShift) | (workerId << workIdShift) | sequence; } /** * 下一毫秒获取 * @param lastTimestamp * @return long * @author Wang Qingcheng * @since 2021/9/13 */ private long tilNextMillis(long lastTimestamp) { long timestamp = System.currentTimeMillis(); while (timestamp <= lastTimestamp) { timestamp = System.currentTimeMillis(); } return timestamp; }}
关于workId的分配
如果集群机器数比较少,可以手动设置。
使用Zookeeper持久顺序节点(美团的Leaf-snowflake方案)
启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
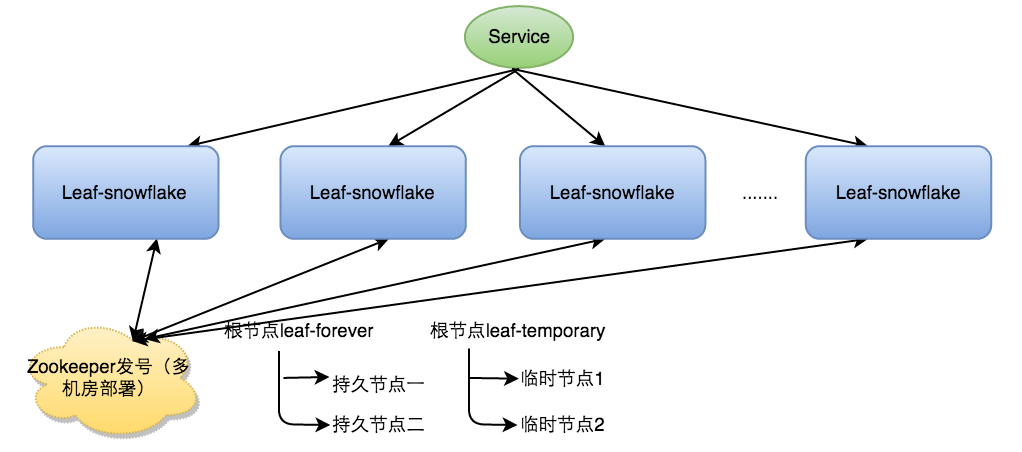
除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。这样做到了对三方组件的弱依赖。一定程度上提高了SLA
3. 使用redis记录已使用的机器id
没实现过提供下思路。value为机器id的编号列表。每次有新的机器启动生成列表里不存在的id。
解决时钟回拨问题
美团的leaf-snowflake解决了回拨问题并在2017年出现闰秒时避免了对业务的影响。
public synchronized Result get(String key) { long timestamp = timeGen(); if (timestamp < lastTimestamp) { long offset = lastTimestamp - timestamp; if (offset <= 5) { //如果回拨时间小于等于5ms try { //等待回拨时间2倍的时间 wait(offset << 1); timestamp = timeGen(); if (timestamp < lastTimestamp) { return new Result(-1, Status.EXCEPTION); } } catch (InterruptedException e) { LOGGER.error("wait interrupted"); return new Result(-2, Status.EXCEPTION); } } else { //回拨时间大于5ms,抛出异常 return new Result(-3, Status.EXCEPTION); } } if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { //seq 为0的时候表示是下一毫秒时间开始对seq做随机 sequence = RANDOM.nextInt(100); timestamp = tilNextMillis(lastTimestamp); } } else { //如果是新的ms开始 sequence = RANDOM.nextInt(100); } lastTimestamp = timestamp; long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence; return new Result(id, Status.SUCCESS); }
文章转载自SH的全栈笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
