




“ 我感觉我对待SQL和可视化是一样的态度,怎么说呢?于我而言,它的作用就是取数,而新手与高手的差别就是取数的效率问题。高效率取数固然是好的,但为了效率孜孜不倦花费大量时间去钻研怎么写出更优美的SQL又如何?我保持怀疑。
其实可以在其它更擅长工具上再去优化数据也是可以的,毕竟要学的东西那么多,精力有限,很多东西用着用着就会越来越好的。数据分析的核心在于挖掘和分析,而不是取数有多快。纯粹个人看法,勿喷~”
01
—
SQL
1、SQL(发音为字母S-Q-L或sequel)是结构化查询语言(Structured Query Language)的缩写。SQL是关系数据库标准语言
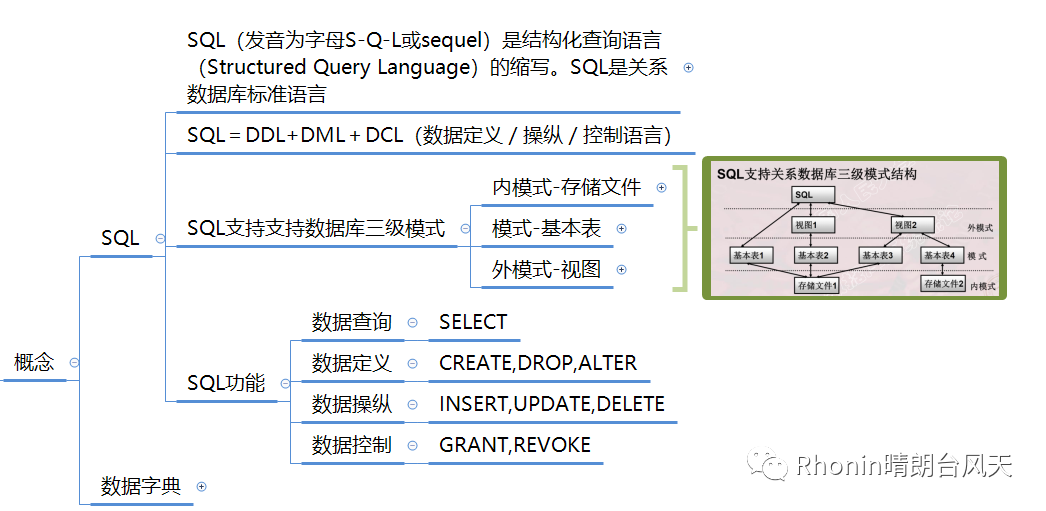
3、SQL支持支持数据库三级模式
在我的理解来看,基本表就好像数据源表,视图有点类似数据透视表。视图有几个作用可以了解一下:简化用户操作,用户可以用不同角度解读数据,而且保持了逻辑独立性,也能保护基本表数据安全。说完这几个作用有没有感觉真的有点像透视表,哈哈。
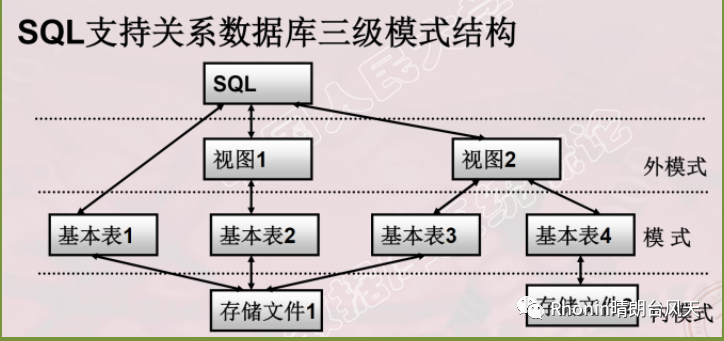
图片引用中国人民大学《数据库系统概论》
4、SQL功能(重点核心)
数据查询:SELECT (重中之重)
数据定义:CREATE,DROP,ALTER
数据操纵(数据更新):INSERT,UPDATE,DELETE
数据控制(数据保护):GRANT,REVOKE
后面3个的权限还是很难讲的,要具体情况具体运用,通常为了保护数据安全,你不一定有权限后面三个有机会能接触到,即使接触也是部分,你是数据库管理员就另当别论了。
所以把核心放在查询这块,如果后面3个有机会接触,随时补课都可以,真的不算难。
5、数据字典
系统内部一组系统表,记录信息,我感觉可以当成记录日志这样来理解。包括:
关系模式、表、视图、索引定义
完整性约束的定义
各类用户对数据库的操作权限
统计信息等
02
—
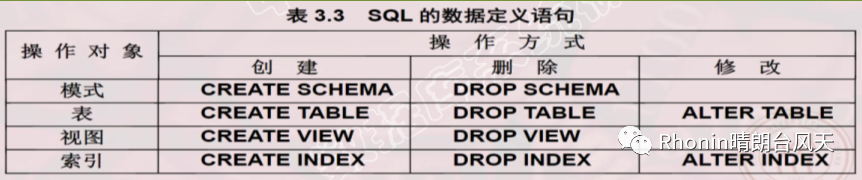
数据定义
1、定义各种数据库的“对象”,层次化数据库对象命名机制,也就是一个数据库可以建立多个模式,一个模式下通常包含多个表、视图和索引等数据的对象。
2、模式定义,命名空间/目录
创建:CREATE SCHEMA 模式名 AUTHORIZATION 用户名[表/视图/授权定义子句]。
#栗子:为用户A创建一个模式B,并在其中定义一个表CCREATE SCHEMA B AUTHORIZATION ACREATE TABLE C
删除:DROP SCHEMA 模式名 CASCADE(级联,全删)|RESTRICT(限制,如有下属对象拒删)
#栗子:删除模式B,同时删除该模式的表CDROP SCHEMA B CASCADE
3、表定义
创建:CREATE TABLE "模式名".表名(列名 数据类型[列级完整性约束条件]…[,表级完整性约束条件])
设置搜索路径:SET search_path TO”S-T“,PUBLIC
其中,数据类型参考如下:
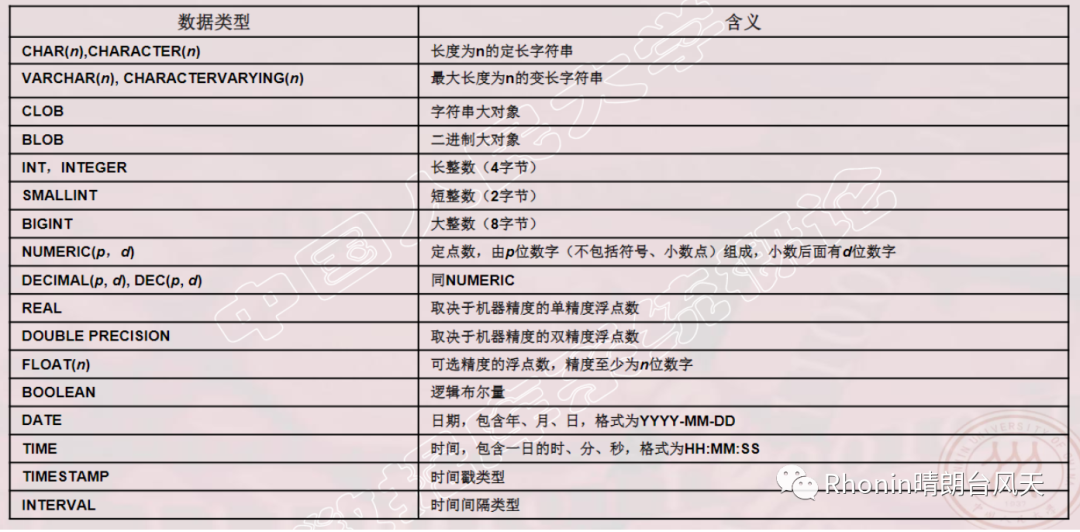
图片引用中国人民大学《数据库系统概论》
#栗子:建立人员表,编号是主码,姓名取值唯一,被参照表A,外码PnoCREATE TABLE PEOPLE(Pno CHAR(6) PRIMARY KEY, #列级完整性约束条件Pname CHAR(4) UNIQUE) #列级完整性约束条件FOREIGN KEY(Pno)REFERENCES A(Pno)
修改:ALTER TABLE 表名
1、列:[ADD/DROP/ALTER[COLUMN]列名 数据类型[完整性约束][CASCADE(级联)|RESTRICT(限制)]/
2、完整性约束:[ADD表级完整性约束]/[DROP CONSTRAINT完整性约束名[CASCADE(级联)|RESTRICT(限制)]]
#栗子:向A表增加B列,数据类型为整数ALTER TABLE A ADD B INT#栗子:将B列数据类型整数改为长为5的字符串ALTER TABLE A ALTER COLUMN B CHAR(5)#栗子:增加B列必须取唯一值的约束条件ALTER TABLE A ADD UNIQUE(B)
删除:DROP TABLE 表名[CASCADE(级联)|RESTRICT(限制)](不同数据库可能略有不同)
#删除A表ALTER TABLE A CASCADE
4、视图定义
虚表,从基本表(视图)导出来的表;基表数变,视图数变
创建:CREATE VIEW <视图名>[(<列名>[,<列名>…)]
AS <子查询>
[WITH CHECK OPTION]保证后期修改仍满足条件
#建立女性成员视图CREATE VIEW FEMALE_MEMBERASSELECT Mno,Mname,MageFrom MEMBERWHERE Msex='FEMALE'WITH CHECK OPTION #后期修改插入时仍保留女性成员
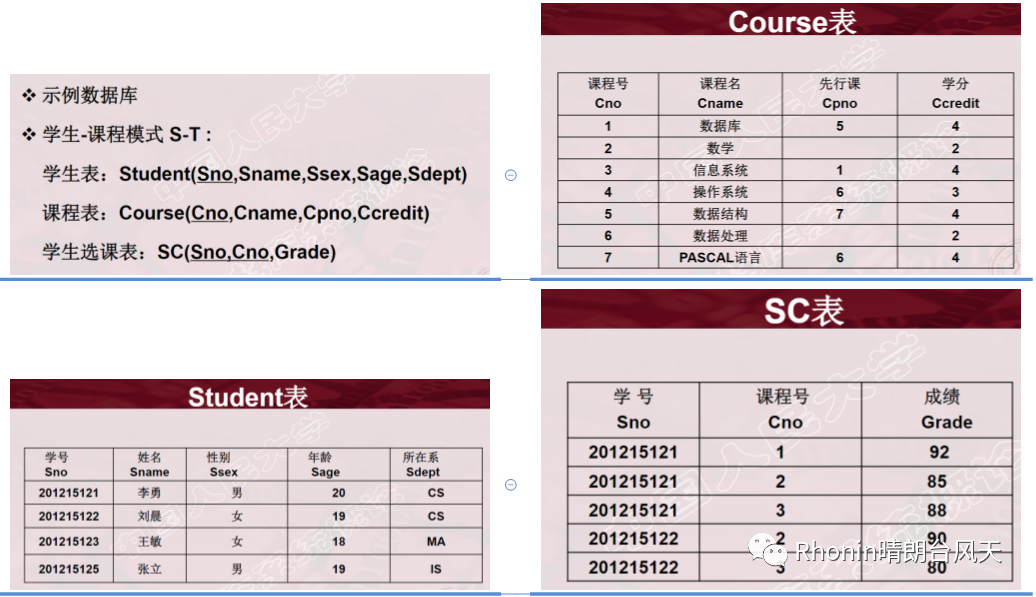
图片及栗子引用中国人民大学《数据库系统概论》
#建立信息系统选修了1号课程的学生的视图(包括学号,姓名,成绩)CREATE VIEW 1_IS(Sno,Sname,Grade)ASSELECT Student.Sno,Sname,GradeFROM Student,SCWHERE Sdept ='IS' ANDStudent.Sno =SC.Sno ANDSC.Cno='1'
栗子先举到这里,后面单独一篇来练习好了,不然会让这文好长。
删除:DROP VIEW <视图名>[CASCADE]
5、索引定义,加快查询速度
数据库管理员或表主创建,常见索引有:
顺序文件索引
B+树索引,动态平衡
散列(hash)索引,查询速度快
位图索引
创建:CREATE[UNIQUE唯一][CLUSTER聚簇索引]INDEX 索引名 ON 表名(列名[次序ASC默认升序DESC降序]…)
修改:ALTER INDEX 旧索引名 RENAME TO 新索引名
删除:DROP INDEX 索引名

03
—
数据查询
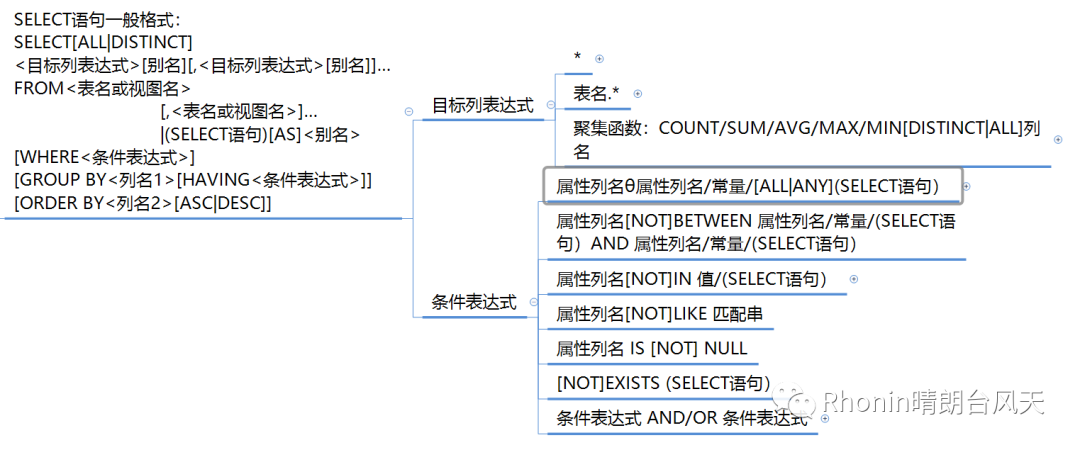
我们真正要掌握的SELECT语句一般格式如下,是的,很简单,比Python简单多了,真正难在嵌套情况下的逻辑理解。其实就和概率计算差不多的道理。
统计-3 统计描述:你又被平均了吗?
 1、单表查询
1、单表查询
SELECT[ALL|DISTINCT]<目标列表达式>[,<目标列表达式>]… #指定要显示的属性列
SELECT *(查询所有列)/SELECT 旧列名 新列名,……/SELECT DISTINCT 列名(删除重复行)
SELECT COUNT(*)计算元组个数/SELECT COUNT/SUM/AVG/MAX/MIN([DISTINCT|ALL]<列名>)统计一列值的个数/总和(列为数值)/平均值(列为数值)/最大/最小值
FROM<表名或视图名>[,<表名或视图名>]…|(SELECT语句)[AS]<别名> #指定查询对象(基本表或视图)
[WHERE<条件表达式>] #指定查询条件
比较:WHERE 列名 =/!=/>/>=/!>/</<=/!</<>/NOT+
确定范围:WHERE 列名 BETWEEN 数值 AND 数值/NOT BETWEEN 数值 AND 数值
确定集合:WHERE 列名 IN/NOT IN('字符串',……)
字符匹配:WHERE 列名 LIKE/NOT LIKE '字符串'(通配符%任意长度_单字符)[ESCAPE'换码字符串'将通配符转义为普通字符]
空值:WHERE 列名 IS NULL/IS NOT NULL
多重条件(逻辑运算):WHERE 列名 条件 AND优先/OR/NOT 列名 条件(可用括号改变优先级)
[GROUP BY<列名1>[HAVING<条件表达式>]] #GROEP BY子句对查询结果按指定列的值分组,HAVING短语只有满足指定条件的组才能输出
GROUP BY 列名 HAVING COUNT(*)计算元组个数
[ORDER BY<列名2>[ASC|DESC]] #对查询结果按指定列值升序或降序
默认升序ASC, DESC降序
2、连接查询
SQL连接,连接条件或连接谓词:用来连接两个表的条件一般格式如下:
[<表名1>.]<列名1><比较运算符>[<表名2>.]<列名2>
连接字段:连接谓词中列名称
等值与非等值连接查询,等值,连接运算符=,可在WHERE 或 SELECT连接
自身连接,表与自身连接,取表别名和列别名
外连接,指定表为连接主体,普通连接只输出元组
多表连接,两个以上表连接
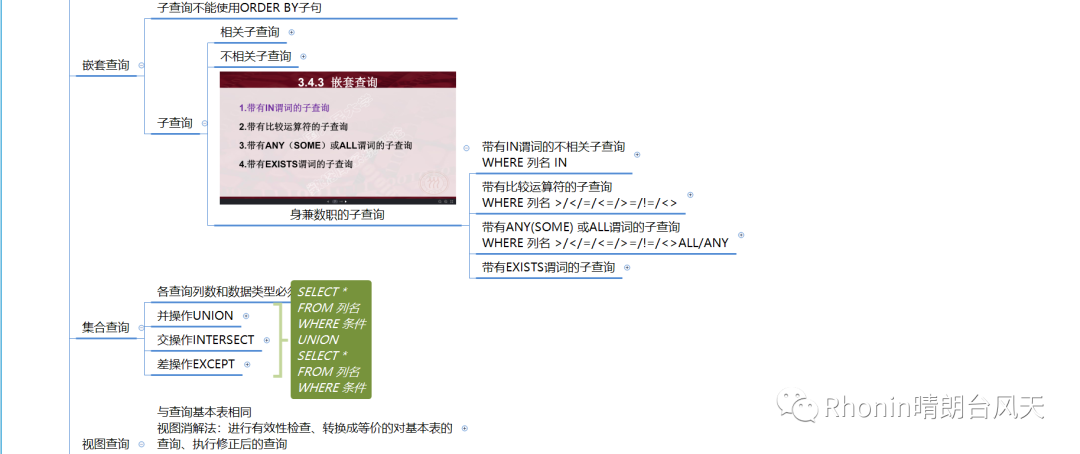
3、嵌套查询
一个SELECT-FROM-WHERE语句组合称为查询块,将一个查询块嵌套在另一个查询块的WHERE或HAVING条件中称为嵌套查询
SELECT 列名 #外层查询或父查询
FROM 表名
WHERE 列名 IN
(SELECT 列名
FROM 表名
WHERE 列名) #内层查询或子查询
子查询不能使用ORDER BY子句
子查询分为相关和不相关子查询
子查询“身兼数职”:
a、带有IN谓词的不相关子查询
WHERE 列名 IN
b、带有比较运算符的子查询
WHERE 列名 >/</=/<=/>=/!=/<>
c、带有ANY(SOME) 或ALL谓词的子查询
WHERE 列名 >/</=/<=/>=/!=/<>ALL/ANY
d、带有EXISTS谓词的子查询
4、集合查询
各查询列数和数据类型必须相同,分别有并操作UNION、交操作INTERSECT、差操作EXCEPT。
SELECT *
FROM 列名
WHERE 条件
UNION
SELECT *
FROM 列名
WHERE 条件
5、视图查询
与查询基本表相同
视图消解法:进行有效性检查、转换成等价的对基本表的查询、执行修正后的查询


04
—
数据更新
1、插入数据
插入元组
INSERT
INTO<表名>[(<列1>[,<列2>…)] #没指定列则插入一条元组
VALUES(<常量1>[,<常量2>…) #值个数与类型
插入子查询结果
INSERT INTO<表名>[(<列1>[,<列2>…)]
2、修改数据
UPDATE<表名>
SET<列名>=<表达式>[,<列名>=<表达式>]…
[WHERE<条件>] #省略则修改所有元组
3、删除数据
DELETE FROM<表名>
[WHERE<条件>] #省略则删除所有元组
4、更新视图的限制
一些视图不可更新,因为视图更新不能唯一有意义地转换成对基本表的更新
5、空值处理
空值是不知道、不存在、无意义的值
判断:IS NULL 或 IS NOT NULL
不能取空值情况:NOT NULL约束/UNIQUE限制属性/码属性
算术、比较、逻辑运算
a、空与任何值算术运算为空
b、空与任何值比较运算为UNKNOWN

05
—
数据安全
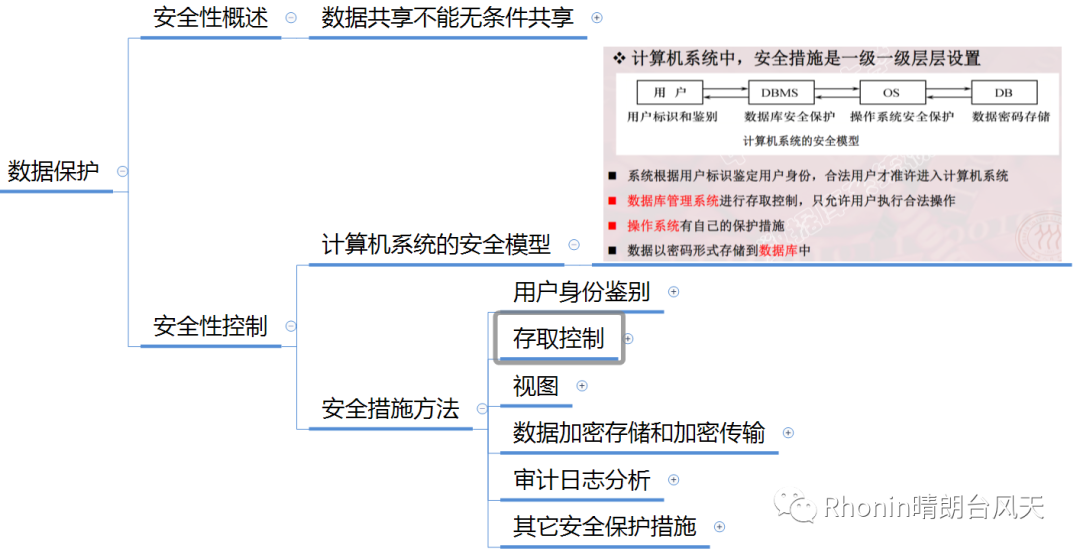
数据不能无条件共享,计算机系统会有安全模型

数据库的安全措施方法:
用户身份鉴别、存取控制(这部分相对来说比较复杂,主要是GRANT和REVOKE的使用,如果是数据库管理员可是深入学习,这里就不去详细解释了)、视图、数据加密存储和加密传输、审计日志分析、其它安全保护措施等等。
说明:(以上部分概念及图片引用中国人民大学《数据库系统概论》)

