




❝论文标题丨HALO: Hierarchy-aware Fault Localization for Cloud Systems
论文来源丨KDD 2021
论文链接丨https://dl.acm.org/doi/abs/10.1145/3447548.3467190
源码链接丨RE: https://github.com/lotcher/HALO
❞
TL;DR
一个典型的云系统有大量遥测数据,这些数据由无处不在的软件监控器收集,这些监控器不断跟踪系统的健康状态。遥测数据本质上是多维数据,其中包含被监控系统的属性和失败/成功状态。通过识别故障最集中的属性值组合(我们称之为故障指示组合),我们可以将系统故障的原因定位到更小的范围内,从而便于故障诊断。然而,由于云遥测数据中的组合爆炸问题和潜在的层次结构,以有效的方式将故障定位到适当的粒度仍然是困难的。在本文中作者提出了 HALO,一种层次感知故障定位方法,用于从遥测数据中定位故障指示组合。我们的方法自动学习属性之间的层次关系,并利用层次结构进行精确有效的故障定位。我们在工业和合成数据集上对 HALO 进行了评估,结果证实 HALO 优于现有方法。此外,我们已成功将 HALO 部署到 Microsoft Azure 和 Microsoft 365 中的不同服务中,见证了其在实际实践中的影响。
Algorithm/Model
HALO 主要利用维度之间的嵌套关系生成AHG(属性层次图)来减少搜索空间和定位到适当的粒度(”根因判断标准“)。场景和之前的多维定位相似,数据是遥感数据,数据示例如下表。
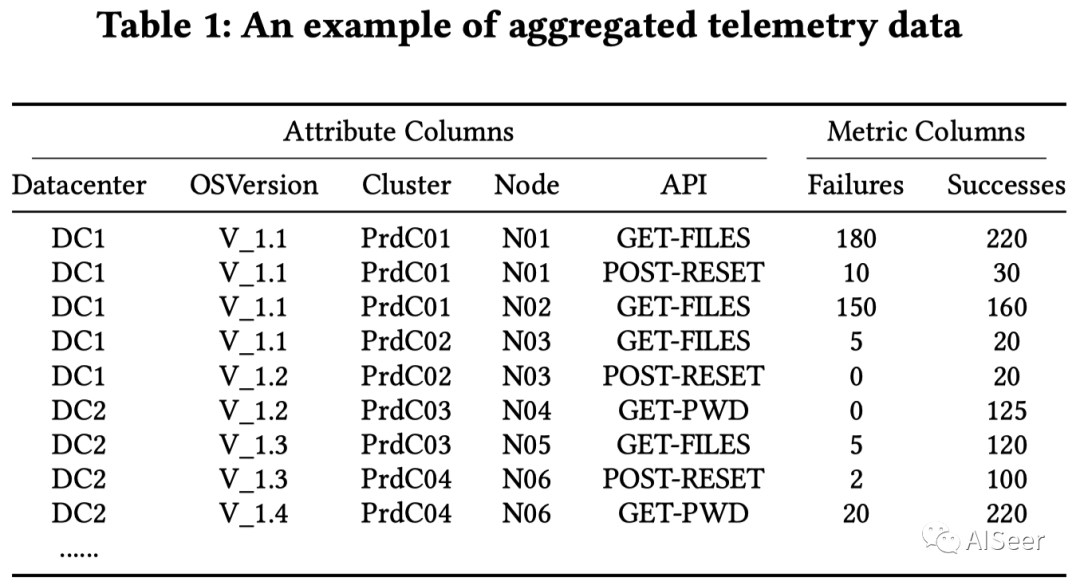
对于上述示例数据,本文认为应该定位到 {"Cluster": "PrdC01", "API": "GET-FILES"} , 定位到 Datacenter 粒度较大,Node 太具体。不满足Ripple Effect,HotSpot 和 Squeeze 可能受影响。
HALO 模型的主要框架如下所示:
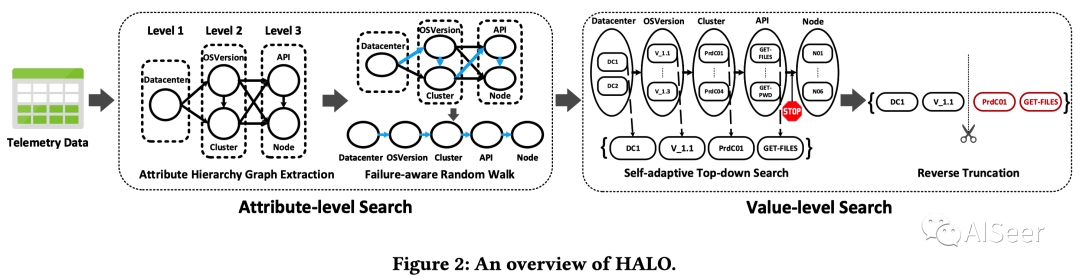
主要包含「属性层次图提取」 和 「维度搜索」 两个过程。
属性层次图提取
主要目的是确定有限搜索路径集,减少搜索空间。主要过程如下所示:
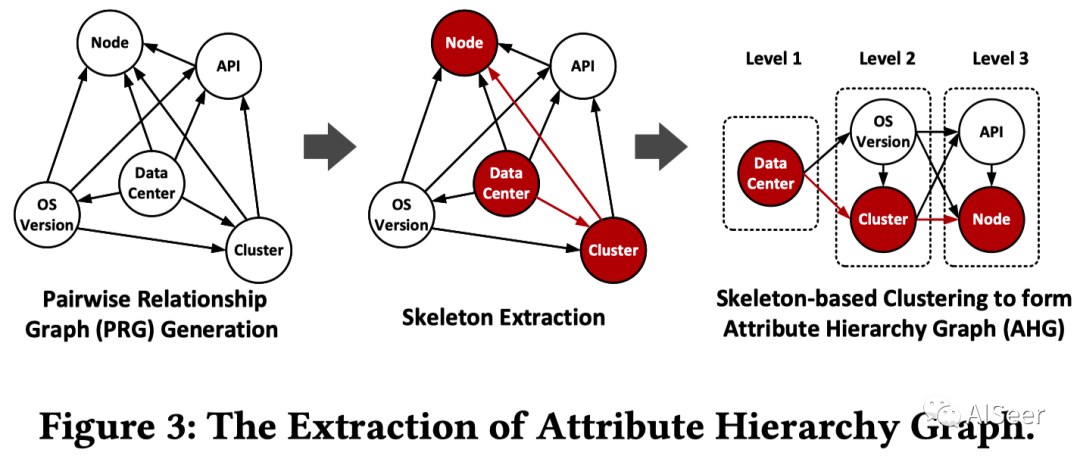
对应的每步过程如下:
用条件熵来表示两个维度间的包含关系大小,如果是确定的包含关系(Cluster和Node),条件熵为0
用条件维度的熵来归一化条件熵,定义为UR,范围为0-1。越大表明包含关系越强(只考虑m包含n)
低熵的维度指向高熵的维度(e.g. Cluster->Node),构建有向图。如果UR > 0.9,认为是强相关的(红边标注)
转化为树形图
先利用强相关边构建骨架:倾向于构建更长的强相关链路,即 Datacenter->Cluster->Node(先后关系由UR大小决定), 而不是将Node和Cluster放在同层 填充其余维度,目标是同层维度熵相似,不同层维度差异尽可能大。定义一个优化问题来表达这个关系(类似于xgboost分裂节点计算基尼指数来表示分裂增益) 利用随机游走,按层遍历,从Level1开始,采样每个节点计算失败占比,生成多条路径(e.g. DataCenter->OsVersion-> Cluster-> API->Node)
维度搜索
AHG 中的多条路径并行搜索,满足根因判断则停止。
如果cuboid异常但是不是根因则继续搜索。最后再通过 Reverse Truncation 给出最终的维度组合。主要过程如下所示

Election Scoring和Damping scoring 可以根据自己需求和数据特点定义
本文认为 If more failures concentrate on a certain combination, we are more inclined to choose it as the faultindicating one,定义异常分数如下(概念类似于F1_Score):
根因判断和Ripple Effect思想类似:Failures in cloud environment tend to spread evenly over the records on the true fault-indicating combination 。通过计算每个维度组合和标准均匀分布的JS散度来衡量,越小越有可能是根因
Reverse Truncation :如果一个维度组合的子节点能基本表达全部的异常(Election分数判断),则用子节点作为新的根因(类似于多维的一对一和兄弟剪枝策略)
例如判断出根因是 {transtype=转账},其中包含渠道微信和支付宝,其中微信异常远远大于支付宝,则最终结果为 {transtype=转账 && channel=微信}
Experiments
实验部分在人工数据集和真实数据集中验证了 HALO 模型的性能。
度量指标为 SDC(Sørensen–Dice coefficient),计算公式如下
其中 和 分别表示模型定位的维度组合和真实的维度组合。
在人工数据集中效果如下
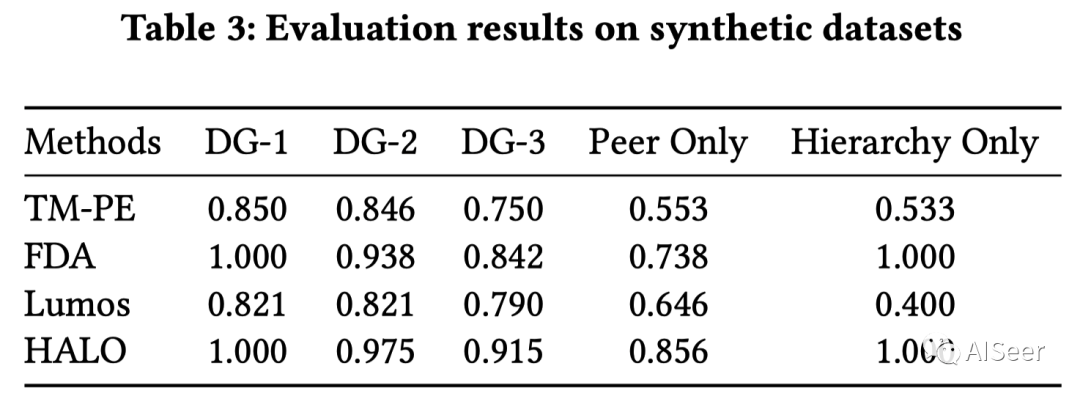
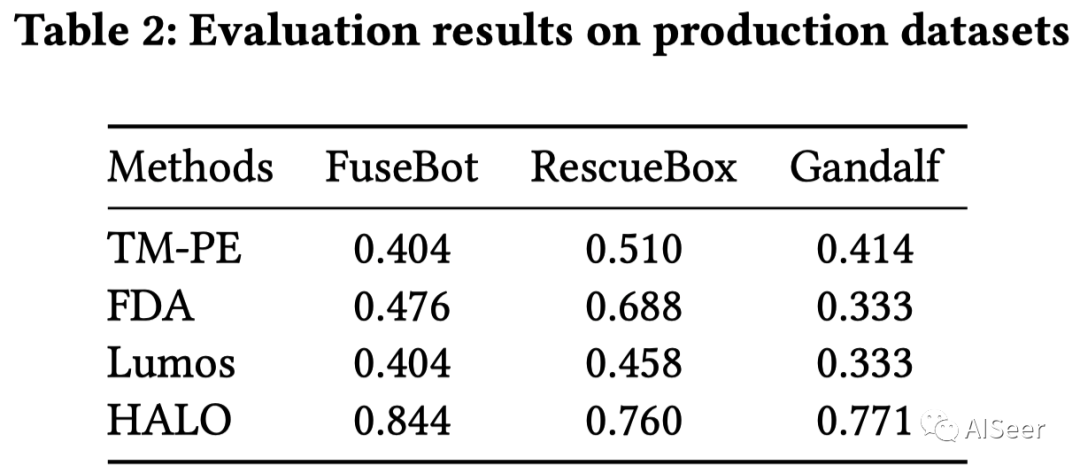
在真实数据集中效果如下
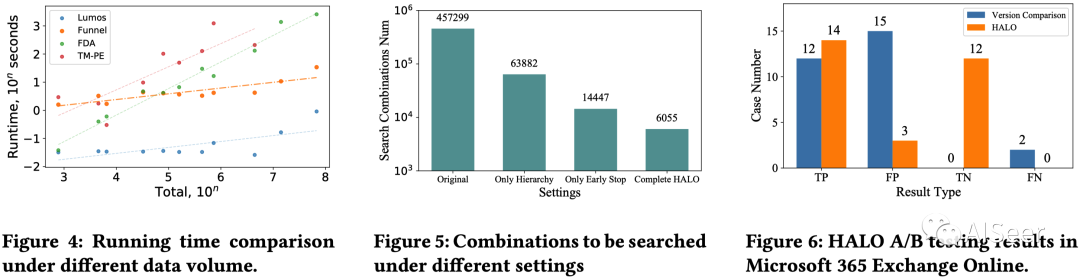
还比较了模型性能和消融实验,结果如下所示
❝推荐阅读
❞
智能运维系列 | 多维指标根因定位算法综述 MTAD-GAT:基于图注意力网络的多变量时间序列异常检测模型 KDD 2020 | MTGNN: 基于图神经网络的多变量时间序列预测模型 KDD 2019 | 基于谱残差和 CNN 的时间序列异常检测模型

 「阅读原文」留言~勿忘「在看」哦
「阅读原文」留言~勿忘「在看」哦
