




❝论文标题 | Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks
论文来源 | KDD 2020
论文链接 | https://arxiv.org/abs/2005.11650
源码链接 | https://github.com/nnzhan/MTGNN
❞
TL;DR
考虑到多变量间存在的依赖关系,论文中针对多变量时序预测问题提出了一个通用的图神经网络框架 MTGNN。首先可以通过 graph learning 模块学习到变量间的单向关系构图,然后通过 graph convolution 模块和 temporal convolution 模块来捕获时间序列间的时空依赖特征,此外这三个模型可以端到端地进行联合训练。实验部分在 3 个基准数据集和 2 个交通流量数据集中验证了 MTGNN 性能优于当前多个 baselines。
Problem Definition
令向量 表示 维变量在 时刻的值,其中 表示第 个变量在 时刻的值。给定历史 个时间戳的数据 ,目标是预测未来第 步变量对应的值 ,或者序列 。
此外,如果输入中包含其它辅助特征例如时间、日期等,可以和序列值同时作为输入,对应的输入表示为 ,其中 , 表示特征维度,第一列为 , 其它的为辅助特征。目标是构建映射函数 使得最小 损失函数最小。
图 节点数量为 ,节点 的邻居节点为 ,邻接矩阵 如果 ,对应说明图是加权有向图。
Algorithm/Model
论文中提出的 MTGNN 框架如下图所示
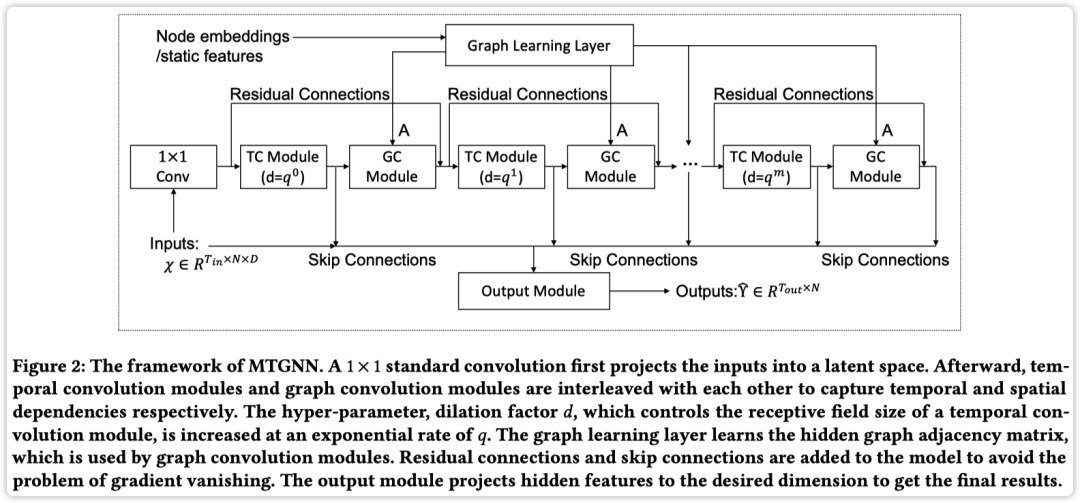
主要包含 1 Graph learning layer,m Graph convolution modules 和 m Temporal convolution modules,以下介绍每个模块的设计;
Graph Learning Layer
非常多的工作使用欧式距离或者 kNN 进行构图,缺点就是计算复杂度达到 ,所以论文中采用了节点子集来计算节点对间的关系。
此外,还有个问题是基于距离度量的方法一般都是对称的,但是对于多变量时间序列而言往往是一个变量值改变导致其它变量随之改变,因此变量间的关系应该是单向的。
论文中设计的 graph learning layer 就是为了捕获单向的关系,其数学计算公式如下
其中 表示初始化 node embeddings, 表示模型训练参数, 为超参数来控制激活函数的 saturation rate。
📢 选择 topk 最大向量值是为了保证图的稀疏性,其它值置为 0;
Graph Convolution Module
为了融合节点信息,图卷积模块使用了两个 「mixhop propagation layers」 来处理每个节点的信息流入和流出,计算方式如下图所示
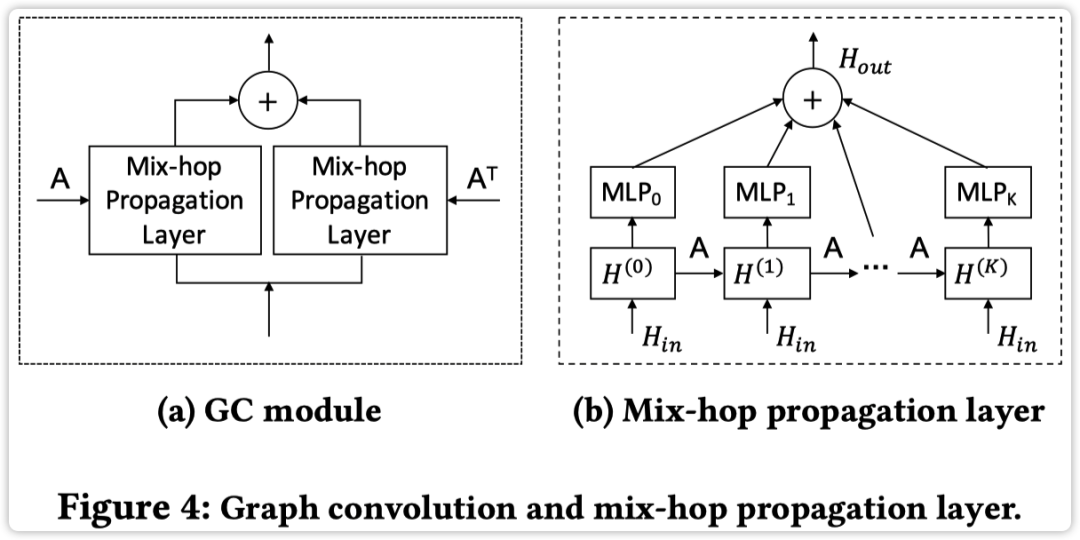
「Mix-hop Propagation Layer」
这层网络主要包含两步:
信息传播,其计算公式如下
其中 为超参数控制源节点的状态保留程度。
信息选择,其计算公式如下
其中 表示传播深度,。
从以上计算可以看出,信息传播层首先横向传播信息然后纵向来选择信息。以上这两步主要是为了防止过平滑但同时保留初始节点特征设计的。
Temporal Convolution Module
这个模块主要是用了两个 1D Dilated Inception Layer 来提取时序特征,其组成如下图所示
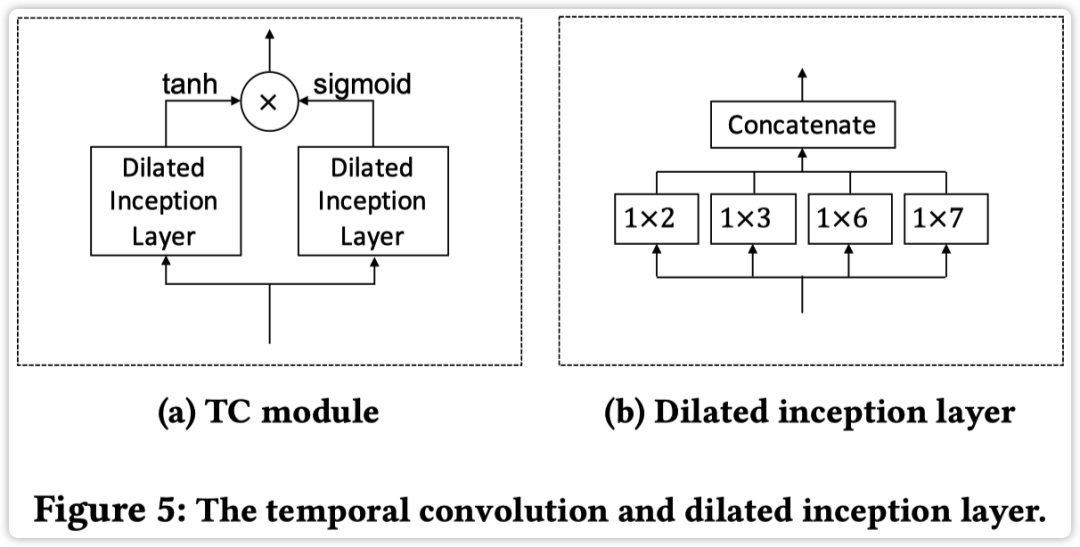
两个 layer 区别在于:tanh 函数分支为滤波器,sigmoid 分支为门电路控制信息权重。
「Dilated Inception Layer」
这计算层纯属作者经验+实验设计,给定 1D 输入序列 和不同大小的卷积核,其计算方式如下
每个卷积层的输出进行拼接,然后与滤波器输出进行卷积得到最后 TC module 的输出
其中 表示 dilation factor。
为了训练更深的模型作者还添加了残差连接,如 Fig.2 中的框架图所示,此处不再细述。
整体 MTGNN 的训练过程如下算法所示:

值得注意的是,论文中并不是将所有节点同时训练因为这样内存太爆炸了,所以 MTGNN 算法首先将节点分为多个组,然后每个组中训练得到节点间的关系,最后综合考虑空间关系。
此外,为了提高 步预测的准确率,论文中还提到了使用 「curriculum learning」 对模型进行优化,主要思想就是先预测简单 1 步的值,等待模型效果稳定后再预测多步的值,课程式学习这个领域涉及较少所以不明所以然,后续有需求再深入学习吧 🥲
Experiments
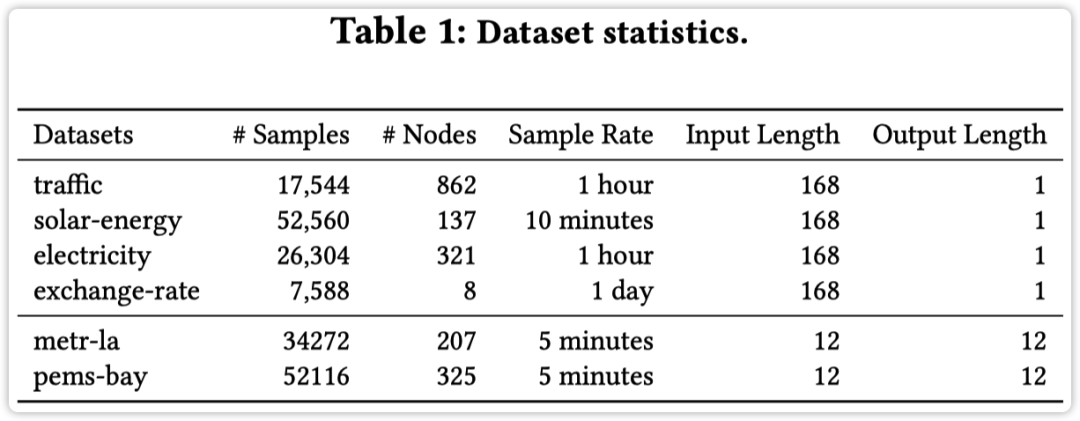
实验部分采用了多个基准数据集,如下图所示
对比 baselines 包含多种:
单步预测 AR:自回归模型 VAR-MLP:自回归 + MLP GP:基于高斯过程 RNN + GRU LSTNet:CNN + RNN TPA-LSTM:Attention + RNN 多步预测 DCRNN:diffusion GCN + GCN STGCN:spatial-temporal GCN Graph WaveNet:spatial-temporal GCN + diffusion GCN ST-MetaNet:meta networks GMAN:graph multi-attention network MRA-BGCN:bicomponent GCN
↑ 列出来只是想说明实验真 solid,绝对不是想说:大佬只要挖个坑,后续绝对有人持续地灌水...怕的是想灌但没坑。
单步预测结果如下所示
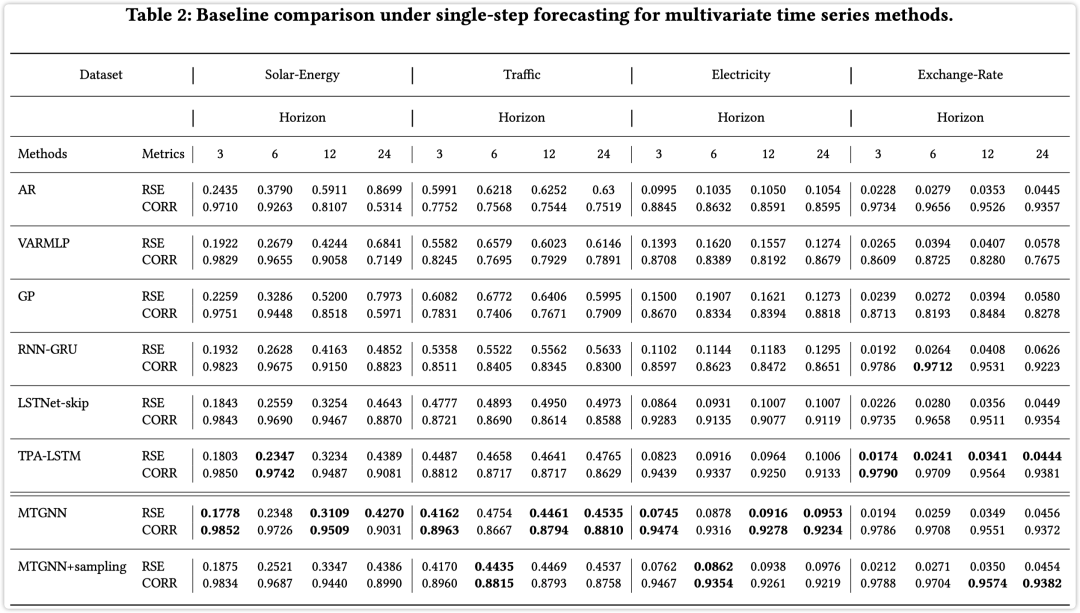
多步预测结果如下所示
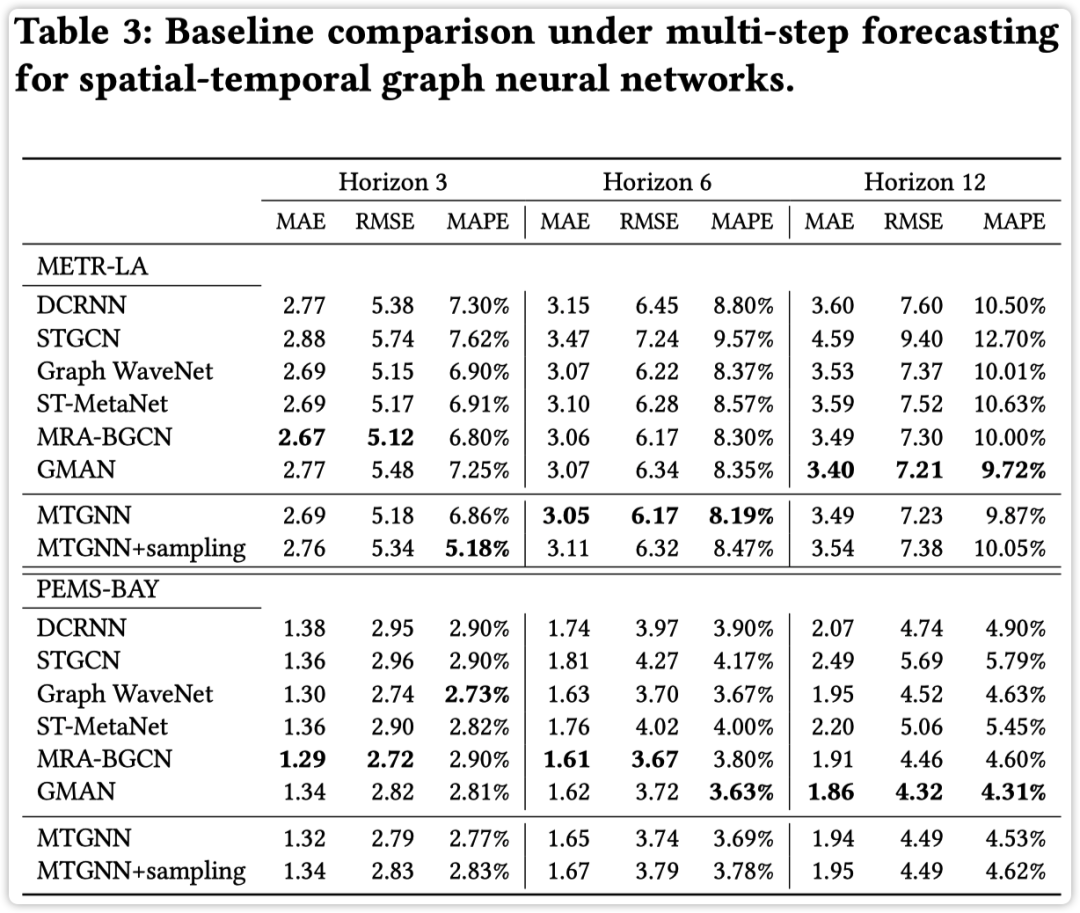
📢 发现:单步预测 TPA-LSTM + 多步预测 GMAN 效果在几个数据集上还超过了 MTGNN,果然是得琢磨下是数据呢还是模型呢 🤔
论文中的消融实验不再细述,感兴趣再去读原文哦 👆🏻
Thoughts
论文中整体想法非常完善而且想法阐述的非常清楚,尤其是实验太 solid 所以就算效果不太好也没啥问题 🤙🏻 比较关注 graph learning 模块,整体而且优于之前介绍的两篇多变量时序异常检测的文章 👍 论文说的节点单向应该并不是学习到一种影响关系,而是取 topK 从而决定每条边的权重不同。
❝推荐阅读
❞
AAAI 2021 | 基于图神经网络的多变量时间序列异常检测 MTAD-GAT:基于图注意力网络的多变量时间序列异常检测模型 时间序列丨周期性检测算法及其 Python 实践 KDD 2019 | 基于谱残差和 CNN 的时间序列异常检测模型

 点击「阅读原文」留言评论哦❣️
点击「阅读原文」留言评论哦❣️
