




最近经常有人问我一些场景下的缓存/持久化的NoSQL数据库选型,今天就来跟大家介绍下这款基于混合SSD架构、提供微毫秒、PB级别、分布式的实时数据库。
关于Aerospike

公司
建立:2009年的美国硅谷
客户:200+企业用户
优势
数据混合存储架构(key存储时:key是以索引的方式存内存,value存SSD硬盘)
作为分布式数据库,大规模数据下的扩展性和稳定性
高性能+强一致
相比于纯内存的Redis方案,显著降低成本
运维成本的降低:易维护+自动rebalance数据
Aerospike架构
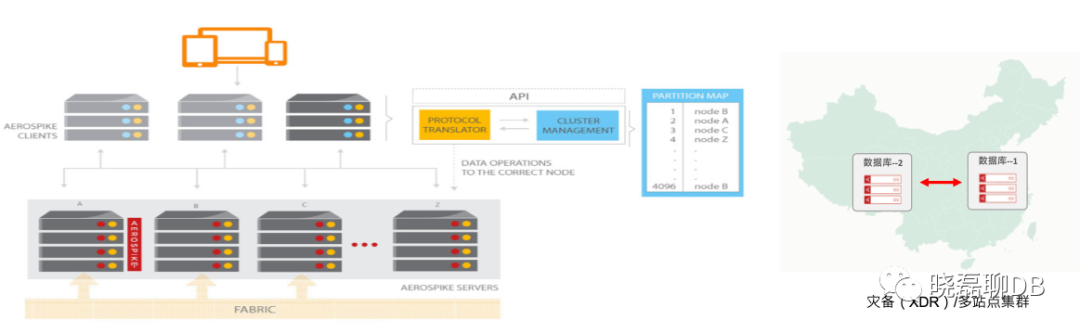
1) Shared Nothing架构
Aerospike分布式集群节点没有Master/Slave这种主从节点之分
每个节点都是相互独立,各自处理自己的数据。
通过组播 or TCP/IP模式进行心跳探测和新节点加入的探测
2) 混合模式存储
数据的索引放内存,真正的数据存在SSD
并且针对SSD进行优化,绕过操作系统的文件系统,直接将SSD作为块设备读写,避免额外的IO损耗
分布式哈希数据分区,采用RIPEMD 160来确保每个节点和闪存设备上存储均衡的数据
丰富的数据类型,支持Integer/Double/String/Boolean/Blob/List/Map等
3) 智能客户端
支持多种Client语言(Java/C/Go/C#/Python/Rust/Ruby/PHP...)
数据访问只需要一次跳转
拥有自己的TCP/IP连接池,并且在检测到节点异常时,透明的将请求转发
4) 支持跨机房和多数据中心部署
部署环境:物理机 or 公有云/私有云平台
同步集群部署:可以使用Aerospike 5版本提供的多站点集群实现统一套集群的2地3中心的部署
异步集群部署:使用集群的XDR配置实现同城双机房的主备部署,比如北京有2个机房,一个机房主要读写,另外一个机房通过XDR复制技术作为备用集群随时提供主集群不可用时的业务接管。
Aerospike设计优化
大家都有类似的疑问,Aerospike为啥能有媲美Redis这种内存数据库的性能?
高并发,支持NUMA
CPU执行和存储引擎都是高度并发。线程根据CPU插槽分组,而不是每个内核,从而与NUMA节点对齐。
事务线程与特定的IO设备关联。客户端网络通信和磁盘端的I/O中断 处理也绑定到运行这些线程的内核,减少跨多个NUMA区域访问的共享数 据量,并降低延迟成本。
减少线程间上下文切换
某些操作在网络监听线程本身中运行, 系统创建的网络监听线程与内核一样多。在不放弃CPU的情况下,接收,处理和响应客户端请求。无阻塞,简短且可预测的实时响应。
内存分配优化
不依赖于编程语言或运行时系统,针对不同对象类型,有独特的内存分配算法。有效的分配索引内存。
扩展标准C库中的jemalloc,根据存储数据对象的类别针对性分配内存。
通过按名称空间将数据对象分组到同一区域中,优化长期对象的创建,访问,修改和删除模式,并最大程度地减少碎片。
精心设计的数据结构
分区的单线程数据结构,对所有关键数据结构进行了分区,但具有细粒度的单个锁,减少跨分区的内存争用,提高CPU上 原子操作的高性能。
访问诸如索引树之类的嵌套数据结构并不涉及在每个级别上获取多个锁。相反,每个树元素都具有引用计数和自己的锁, 这允许对树的安全和并发读取,写入和删除访问,而无需持有多个锁。
频繁访问和经常访问的数据具有局部性,并落在单个缓存行中,以减少缓存未命中和数据停顿。例如,Aerospike中的索引条目正好是64个字节,与X86 64位高速缓存行的大小相同。
调度和优先级的优化
根据作业的类型分配线程池和优先级。作业细化成基于工作量的工作单元。每个线程池由它的负载生成器控制工作的生成 速率。
使用协作调度算法控制X个工作单元执行后的CPU资源释放,保障线程具有CPU核心和分区关联性,以避免在并行线程访问 某些数据时发生数据争用。
并发工作负载通常以先到先得(first-come,first-served)的方式运行,以使每个请求的等待时间都很短。对长期运行 的工作,比如scan,系统会动态适应和转移到轮流调度任务(round robin),对其中并发运行的许多任务进行动态重新调度。
优化的无共享集群管理
基于量子的网络事件检测,将多个复杂的网络更改合并为一个事件,以较少的状态转换有效地处理快速的网络更改
仅传输与驻留在特定节点中的分区有关的数据
客户端优化
服务器与客户端共享分区图,使客户请求可以单跳访问到服务器存储的相应的数据
动态发现集群的当前分区状态,即使加入新节点后,并将事务路由到集群中的正确节点
高并发线程,匹配执行引擎并发数
支持同步和异步执行
应用场景
广告业务场景:广告主实时竞价,广告个性化推荐需求等,下面以个推需求为例:
基于网民当前搜索的浏览和点击行为,系统会分析网民个性化需求,在合适的位置、合适的时间,以合适的形式向消费者呈现与其需求高度吻合的广告,以此来促进用户的消费行为,例如用户标签数据就是存在Aerospike分布式数据库中。
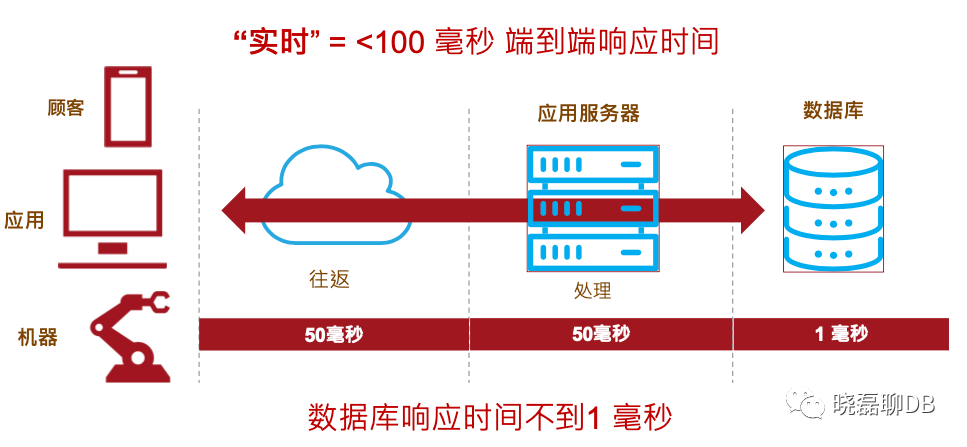
目前kv数据量在50亿+,平均单记录1k size,DB事务请求要求在1毫秒完成,整个业务处理流程在50ms内完毕,大数据量(几十、几百TB),满足低延迟和高吞吐需求。
总结
整体来说:在百T的内存数据库成本巨高不下的时候,可以考虑使用Aerospike这款NoSQL分布式数据库来解决问题。如果有想试用或者继续了解的朋友可以公众号跟我留言。
