




cmin和cmax介绍
cmin和cmax是PostgreSQL中表的系统字段之一,用来判断同一个事务内的其他命令导致的行版本变更是否可见。即在事务中每个命令都应该能看到其之前执行的命令的变更。
很多人都通过测试都会发现在同一张表中cmin和cmax总是相等的,所以认为这两个是同一个概念,其实准确来说这两者的含义并不相同:
cmin:插入事务中的命令标识符(从0开始)。
cmax:删除事务中的命令标识符(从0开始)。
简单来说,cmin和cmax都是表示tuple的command id,即cmin是产生该条tuple的command id,cmax是删除该tuple的command id。
那么为什么表中cmin和cmax总是相等的呢?因为在每个tuple的头部,这两个字段都是存放在t_cid中,其长度为4bytes。但是按理来说,cmin和cmax两个字段应该是要用两个4bytes类型的字段来存储啊,为什么都是存放在t_cid中呢?
combo cid
在PG8.3版本前,cmin和cmax确实是分别存放在不同字段中的,但是从8.3版本开始,为了减少cmin和cmax对heap page空间的占用,将这两个字段都存放在t_cid中了,即combo cid。
正如我们前面所说,cmin表示插入数据的command id,cmax表示删除数据的。那怎么通过一个字段就能识别是插入还是删除呢?想要解决这个问题,我们需要了解下combo cid。
什么时候使用combo cid?
一般来说,当我们的事务中只是插入数据时,t_cid存储的就是cmin,因为此时也只有cmin是有效的。而当进行了update或者delete操作时,才会产生cmax。当这种既有cmin又有 cmax的情况,即在同一个事务中既有插入又有更新的时候,t_cid存储的就是combo cid。
如何判断是否是combo cid?
虽然我们知道了当事务中既有插入又有更新的时候,t_cid存储的便是combo cid。但是对于数据库而言,不过都是unit32类型的数据罢了,那要如何判断呢?
这里便需要用到tuple中的标志位infomask了。
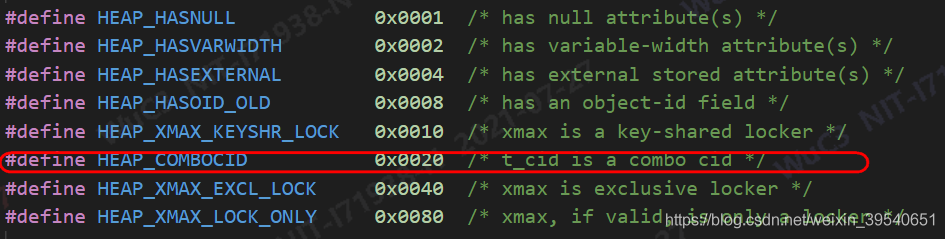
可以看到通过infomask字段可以知道是否是combo cid,如果是,那么就需要通过combo cid再去获取相关的cmin和cmax,而如果不是,则表示这个字段必定是cmin或者cmax(要么就是在本事务内刚插入的,但没有被update/delete,此时的值是cmin;要么就是在其它事务中被insert/update/delete,这种情况不会用到cid来判断可见性)。
如何通过combo cid获取cmin和cmax?
cmin和cmax存储在ComboCidKeyData结构中。
typedef struct{CommandId cmin;CommandId cmax;} ComboCidKeyData;
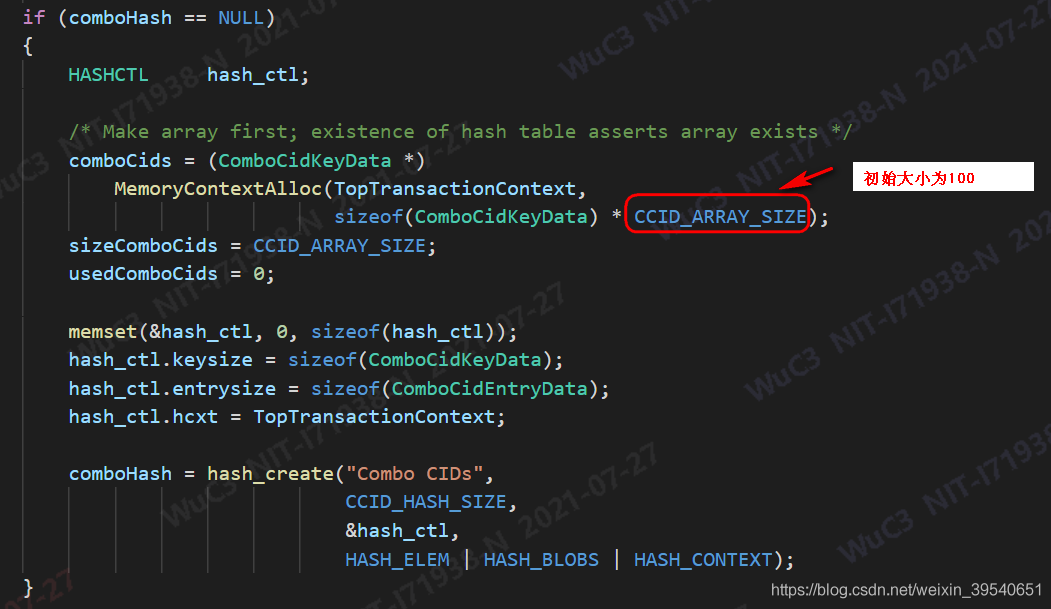
事务在第一次更新本事务插入的tuple时,会新开辟一个数组ComboCidKey comboCids;其大小初始的时候为100(每次空间不够的时候,会将数组的大小的扩大2倍)。同时还会使用一个hashmap,用来根据ComboCidKeyData查找combo cid。
同时为了保证数据结构的大小合理,允许重用现有的combo cid。这里的重用并不是值整个库中重用,因为当事务结束时,combo cid和hashmap都会释放,而是指的是同一个事务中批量执行sql的情况,例如:
bill@bill=>insert into t1 values(1),(2),(3);INSERT 0 3bill@bill=>select cmin,cmax,* from t1;cmin | cmax | id------+------+----0 | 0 | 10 | 0 | 20 | 0 | 3(3 rows)bill@bill=>update t1 set id = 100 where id in (1,2,3);UPDATE 3bill@bill=>select cmin,cmax,* from t1;cmin | cmax | id------+------+-----1 | 1 | 1001 | 1 | 1001 | 1 | 100(3 rows)
在同一个sql里插入多条数据后,然后又进行update,而这些记录的combo cid都是相同的,说明共用了现有的combo cid。
因为combo cid是unit32类型,因此理论上最多可以保存2^32 个不同的 cmin,cmax组合。即使在最极端的情况下,每个命令都会删除每个先前命令生成的元组,那么N 个命令所需组合的combo cid数量是 N*(N+1)/2,即N=92682。当达到这个上限时,会报错“cannot have more than 2^32-1 commands in a transaction”。但是我们大可不必担心,在达到这个限制前,内存或者磁盘估计也已经被耗光了。
根据combo cid获取cmin/cmax的大致流程为:
先根据(cmin, cmax)查找comboHash。
如果找到返回ComboCidEntryData中的combocid(reuse机制, 这个hashmap的作用);
如果没找到,往comboCids数组中添加一个ComboCidKeyData元组,同时往hashmap插入一个entry。返回的combo
cid为usedComboCids(comboCids数组当前的大小),然后usedComboCids++。
初始化hashmap:
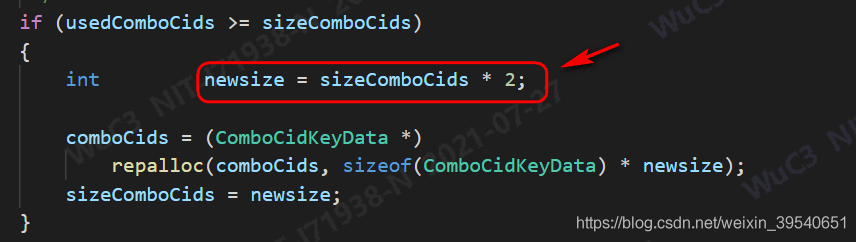
hashmap扩容:
每次增大一倍。
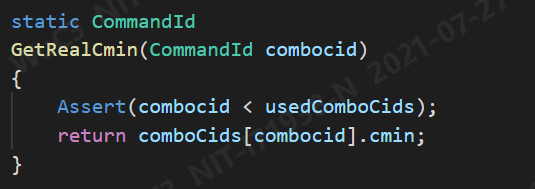
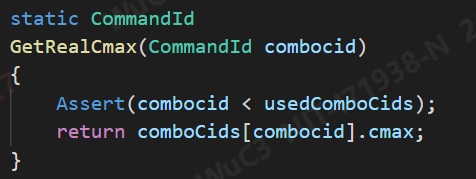
获取实际cmin:
获取实际cmax:
总结
cmin和cmax分别表示产生和删除某条tuple的command id。
对于只有插入或者只有更新/删除的情况,该字段存储的就仅仅是cmin或者cmax。
如果既有插入又有更新/删除的情况,那么该字段存储的就是combo cid,需要通过combo cid去获取实际的cmin和cmax。
参考链接:
src/include/access/htup_details.h
src/backend/utils/time/combocid.c
http://www.postgres.cn/docs/13/ddl-system-columns.html
https://zhuanlan.zhihu.com/p/67725967
我知道你
哦

