




前段时间微信支付JDK又出现了XXE漏洞,原因是对前一个XXE漏洞没有修复成功。细思深层原因,是因为对Java JDK提供的API函数理解不正确,导致误用函数进行防御。我不禁思考了以下问题:
1. Java中XXE漏洞的深层原理是什么?
2. 以下代码为何无法防御XXE?
DocumentBuilderFactory.setExpandEntityReferences(false)
3. 以下代码为何能够防御XXE?
DocumentBuilderFactory.setFeature("http://apache.org/xml/features/disallow-doctype-decl",true)
要弄清以上问题,我们必须深入到Java内置解析器中去一探究竟。于是我打算从JDK代码层面去跟踪解析器执行的每一步操作。接下来我会用三周的文章弄清这三个问题,本周先来弄清第一个!
0x01
测试代码
Java常用解析XML的方式有DOM,SAX,JDOM和DOM4j。我编写了4种方式的XXE漏洞测试代码,
运行发现,漏洞触发点都是一样的。说明这4种解析方式底层实现调用的API函数都是一样的。这里我选择DOM这种最常规的方式来举例。
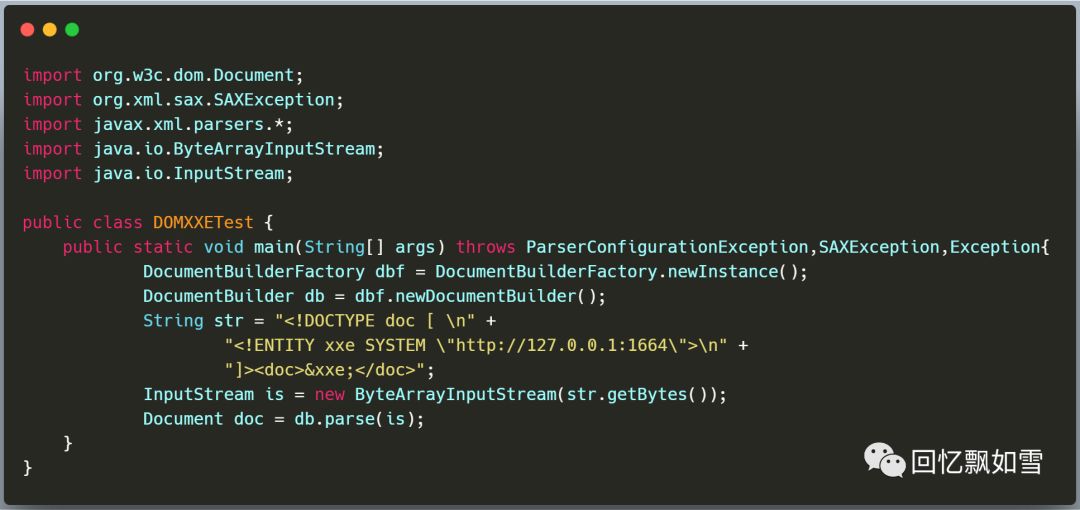
可以在公众号回复"Java XXE漏洞测试代码",获取所有测试代码下载地址。
0x02
漏洞分析
随着Java不断的成熟,它内置的解析器也越来越复杂,这里我们只挑和XXE漏洞相关的核心操作来说明。
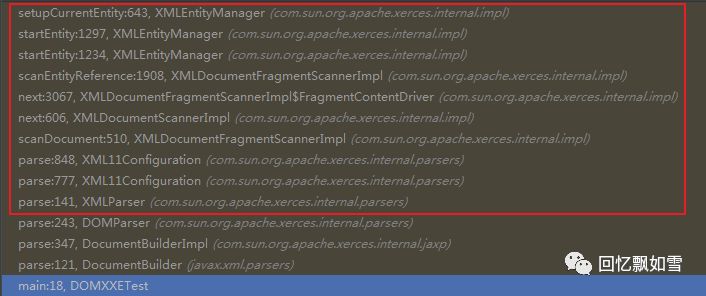
由于所有解析方式都调用了XMLParser类来对XML文档进行解析。故我们从该对象的解析函数Parser开始跟踪。
XMLParser类会调用XML11Configuration类来解析XML文档的配置。
而XML11Cofiguration类又会调用
XMLDocumentFragmentScannerImpl类的scanDocument()对XML文档片段的结构和内容进行扫描。
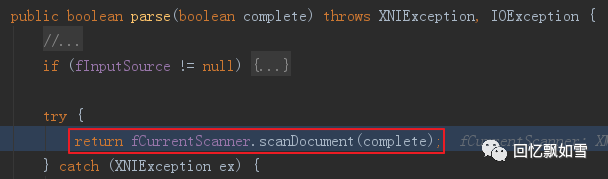
scanDocument方法会先扫描XML的Document部分(START_DOCUMENT阶段),然后在扫描Document中的DTD(DTD阶段),当文档扫描器完成DTD的扫描后,进入START_ELEMENT阶段.
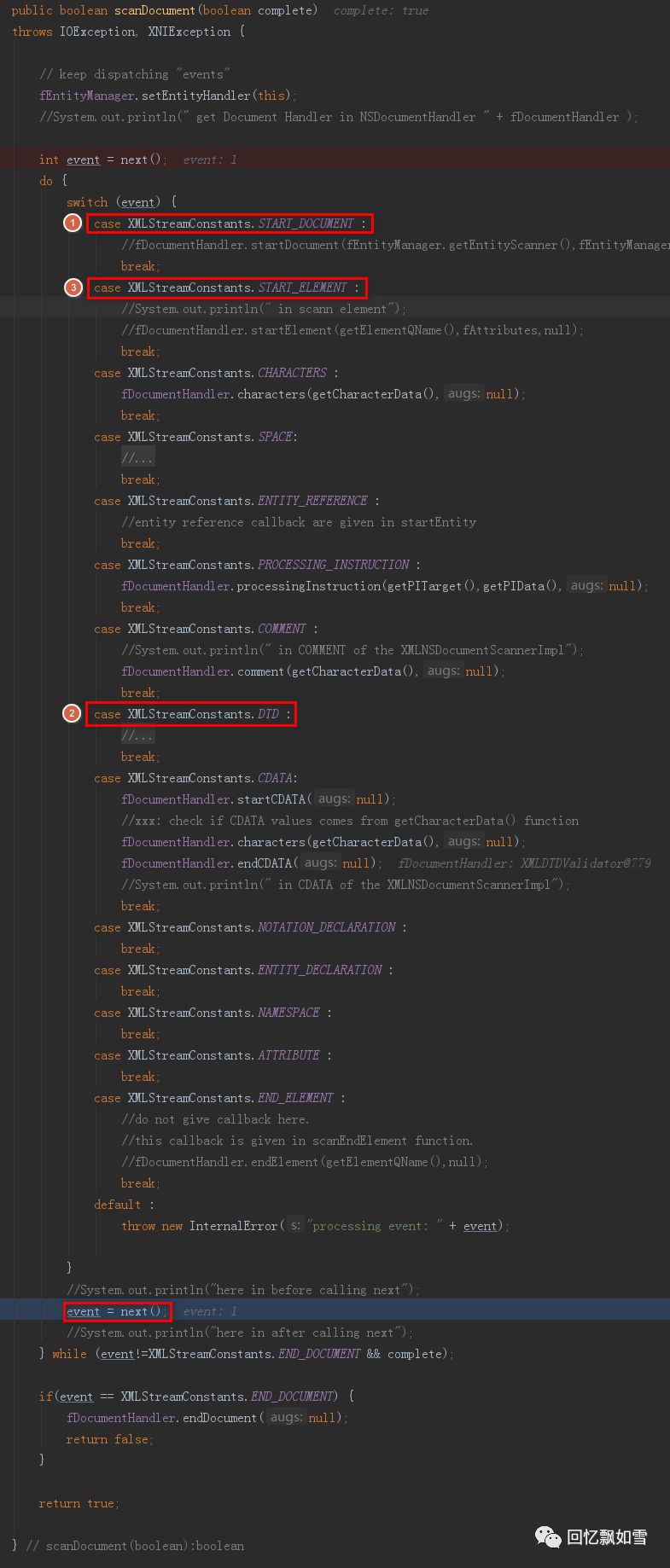
这时next()方法会对XML中的元素进行扫描。当扫描到文本中的&字符时(识别一般实体),将状态置为SCANNER_STATE_REFERENCE。
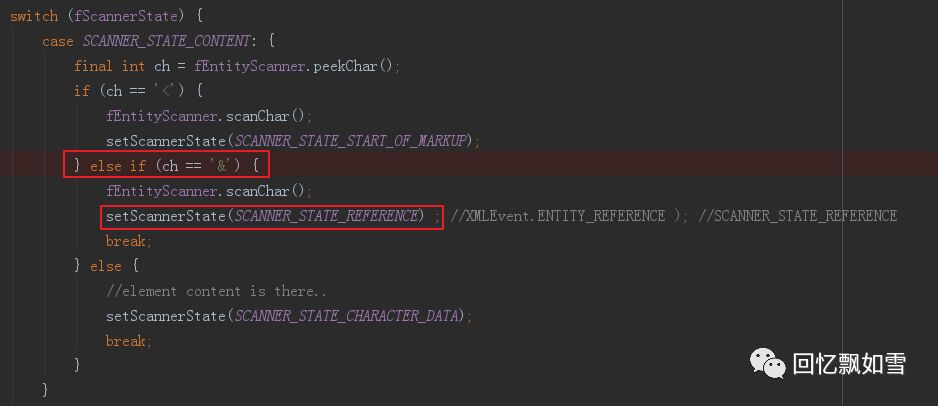
在引用扫描状态下,解析器会调用scanEntityReference() 扫描实体引用。
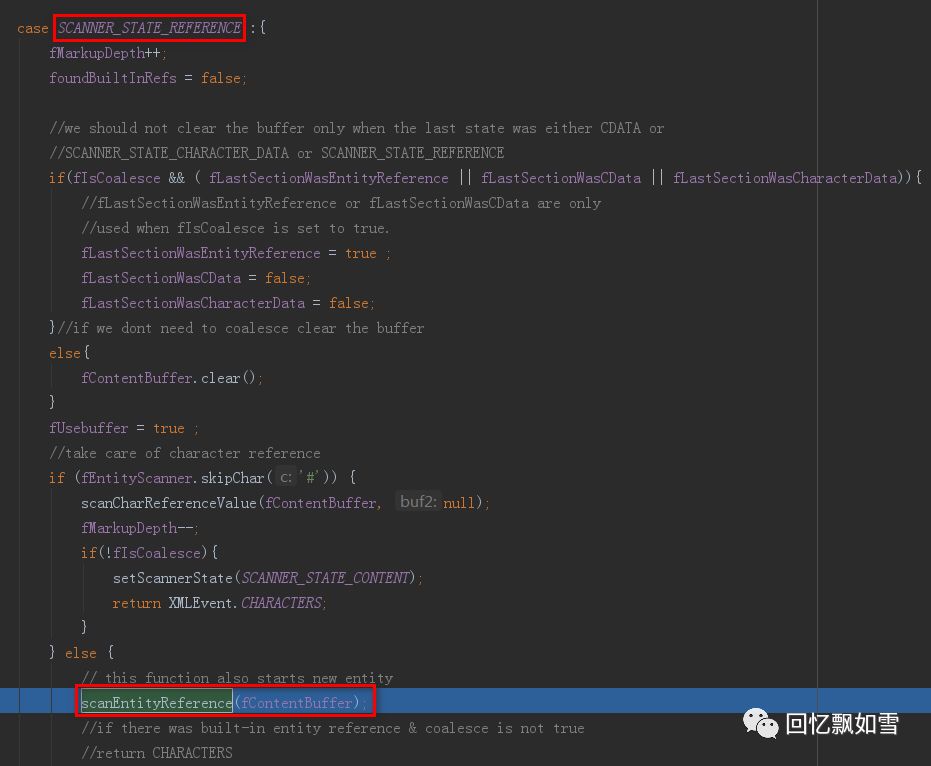
其中将调用XMLEntityManager的startEntity()将应用程序定义的XML实体流插入解析流。
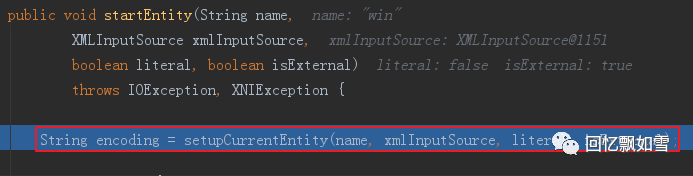
最后会调用setupCurrentEntity()创建连接并发起请求,以获取外部实体的内容,这时XXE漏洞将会触发!
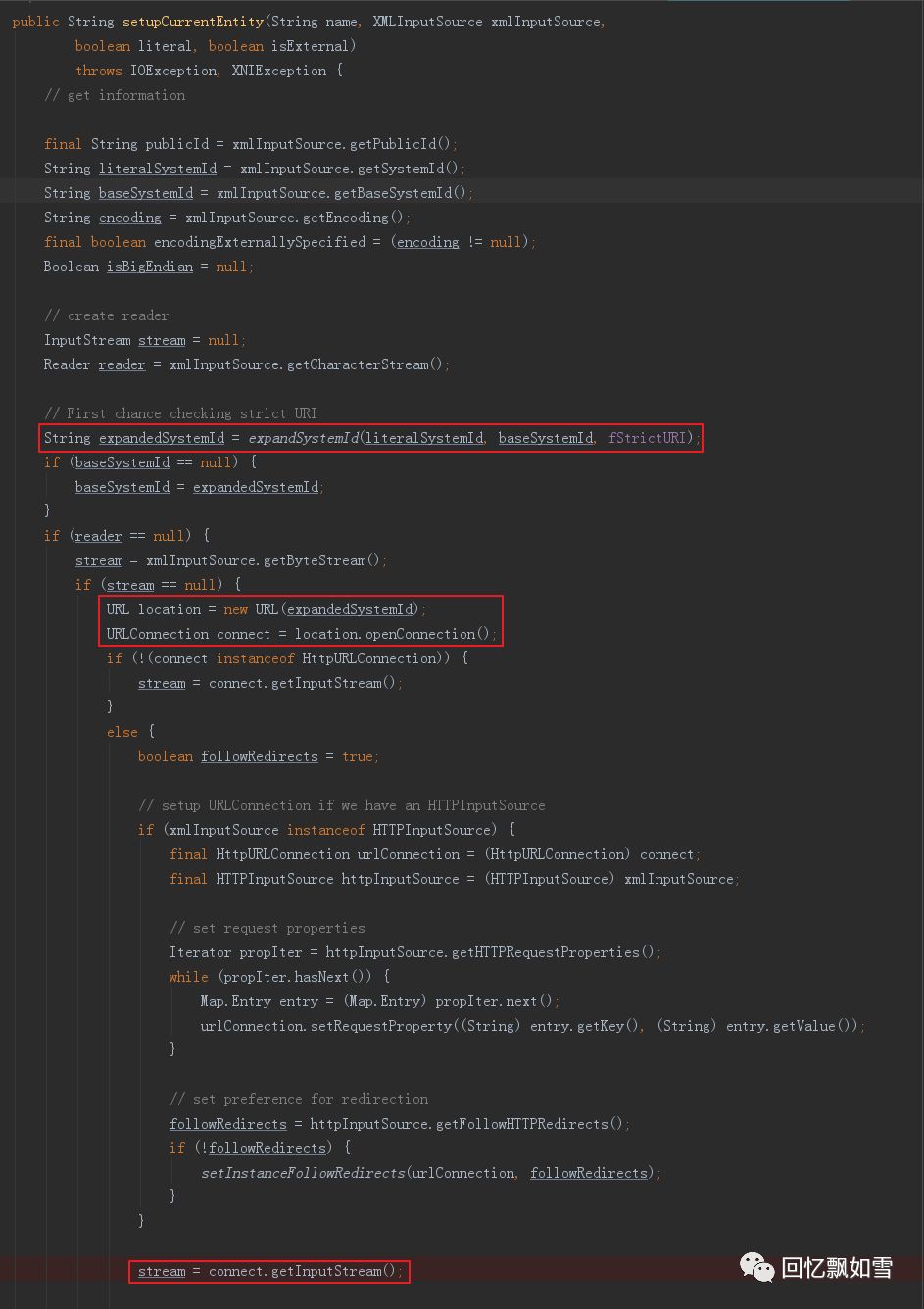
最终调用链如下图所示
0x03
参考文章
《XXE注入漏洞概述》
https://github.com/gyyyy/footprint/blob/master/articles/2018/xxe-injection-overview.md
《XML External Entity (XXE) Prevention Cheat Sheet》
https://www.owasp.org/index.php/XML_External_Entity_(XXE)_Prevention_Cheat_Sheet

