




MySQL 8.0.18刚刚发布,它包含一个全新的功能来分析和理解如何执行查询:EXPLAIN ANALYZE。
它是什么?
EXPLAIN ANALYZE是一个用于查询的分析工具,它将向您显示MySQL在查询上花费的时间以及原因。它将计划查询,对其进行检测并执行它,同时对行进行计数并计算在执行计划中各个点所花费的时间。执行完成后,EXPLAIN ANALYZE将打印计划和度量,而不是查询结果。
这项新功能建立在常规EXPLAIN查询计划检查工具的基础之上,可以看作是MySQL 8.0之前添加的EXPLAIN FORMAT = TREE的扩展。除了正常EXPLAIN将打印的查询计划和估计成本之外,EXPLAIN ANALYZE还打印执行计划中各个迭代器的实际成本。
如何使用?
例如,我们将使用Sakila样本数据库中的数据和一个查询,该查询列出了每个工作人员在2005年8月累积的总金额。查询非常简单:
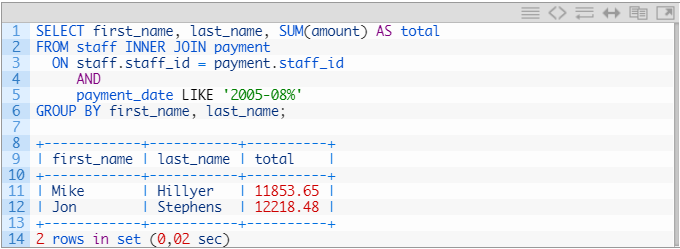
只有两个人,Mike和Jon,我们在2005年8月获得了他们的总数。
EXPLAIN FORMAT = TREE将向我们显示查询计划和成本估算:
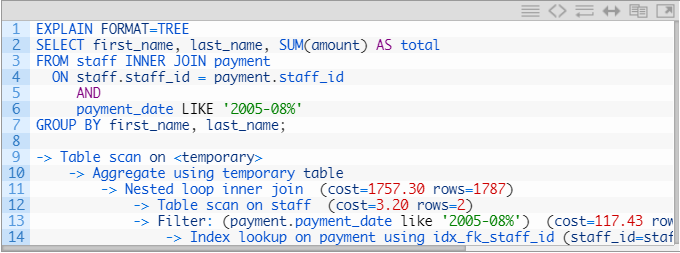
但这并不能告诉我们这些估计是否正确,或者查询计划实际上是在哪些时间上花费的时间。EXPLAIN ANALYZE将执行以下操作:
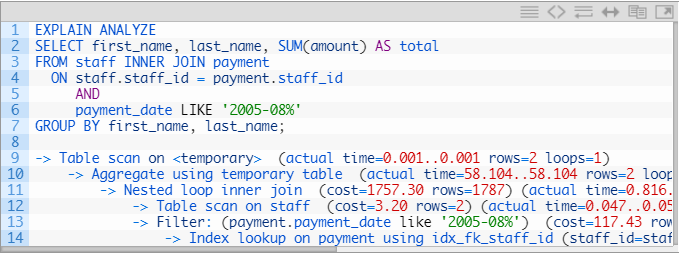
这里有几个新的度量:
- 获取第一行的实际时间(以毫秒为单位)
- 获取所有行的实际时间(以毫秒为单位)
- 实际读取的行数
- 实际循环数
让我们看一个具体的示例,即筛选迭代器的成本估算和实际度量,该迭代器在2005年8月实现销售(上面EXPLAIN ANALYZE输出中的第13行)。

我们的过滤器的估计成本为117.43,并且估计返回894行。这些估计是由查询优化器根据可用统计信息在执行查询之前进行的。此信息也出现在EXPLAIN FORMAT = TREE输出中。
我们将从循环数开始。此过滤迭代器的循环数为2。这是什么意思?要了解此数字,我们必须查看查询计划中过滤迭代器上方的内容。在第11行上,有一个嵌套循环联接,在第12行上,是在staff表上进行表扫描。这意味着我们正在执行嵌套循环连接,在其中扫描人员表,然后针对该表中的每一行,使用索引查找和对付款日期的过滤来查找付款表中的相应条目。由于人员表中有两行(Mike和Jon),因此我们在过滤和第14行的索引查找上获得了两个循环迭代。
对于许多人来说,EXPLAIN ANALYZE提供的最有趣的新信息是实际时间“ 0.464…22.767”,这意味着平均花费0.464毫秒读取第一行,而花费22.767毫秒读取所有行。一般?是的,由于存在循环,我们必须对该迭代器进行两次计时,并且报告的数字是所有循环迭代的平均值。这意味着过滤的实际执行时间是这些数字的两倍。因此,如果我们看一下在嵌套循环迭代器(第11行)中上一级接收所有行的时间,则为46.135毫秒,这是运行一次过滤迭代器的时间的两倍多。
该时间反映了植根于过滤运算符的整个子树的时间,即使用索引查找迭代器读取行然后评估付款日期为2005年8月的条件的时间。如果我们看一下索引循环迭代器(第14行),我们看到相应的数字分别为0.450和19.988 ms。这意味着大部分时间都花在了使用索引查找来读取行上,并且与读取数据相比,实际的过滤相对便宜。
实际读取的行数为2844,而估计为894行。因此,优化器错过了3倍的因素。同样,由于循环,估计值和实际值都是所有循环迭代的平均值。如果我们查看模式,则payment_date列上没有索引或直方图,因此提供给优化器以计算过滤器选择性的统计信息是有限的。对于更好的统计信息可以得出更准确的估计值的示例,我们可以再次查看索引查找迭代器。我们看到该索引提供了更加准确的统计信息:8043行与8024实际读取行的估计。很好 发生这种情况是因为索引附带了额外的统计信息,而这些数据对于非索引列是不存在的。
