




什么是直方图
我们可以将直方图定义为列中值的数据分布的良好近似。
引入了基于直方图的统计信息,以为优化器提供更多执行计划,以调查和解决查询。在此之前,在某些情况下,优化器无法找到最佳的执行计划,因为忽略了未索引的列。
使用直方图统计信息,现在优化器可能有更多选择,因为还可以考虑使用非索引列。在某些特定情况下,查询的运行速度可能比平常快。
让我们考虑下表来存储火车的出发时间:
id INT PRIMARY KEY,
train_code VARCHAR(10),
departure_station VARCHAR(100),
departure_time TIME);
我们可以假设在高峰时段(从7 AM到9 AM),有更多的行,而在夜间,则只有很少的行。
让我们看一下以下两个查询:
SELECT * FROM train_schedule WHERE departure_time BETWEEN '07:30:00' AND '09:15:00';
SELECT * FROM train_schedule WHERE departure_time BETWEEN '01:00:00' AND '03:00:00';
在没有任何统计信息的情况下,优化器默认情况下会假设Leave_time列中的值是均匀分布的,但并非均匀分布。实际上,由于这种假设,第一个查询返回更多行。
发明了直方图,以向优化器提供对返回的行的良好估计。对于到目前为止我们所看到的简单查询,这似乎是微不足道的。但是,让我们现在考虑一下在JOIN中包含与其他表相同的表。在这种情况下,对于优化器决定执行计划中考虑表的顺序,返回的行数可能非常重要。
如果对返回的行进行了很好的估算,则优化器可以在返回几行的情况下在第一阶段打开表。这样可以使最终笛卡尔积的总行数最小化。然后,查询可以运行得更快。
MySQL支持两种不同类型的直方图:“单身”和“等高”。所有直方图类型的共同点是它们将数据集划分为一组“存储桶”,而MySQL自动将值划分为存储桶,还将自动决定要创建哪种直方图。
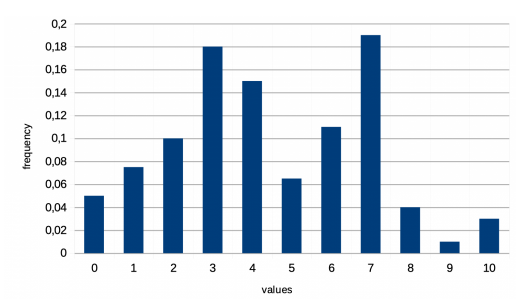
单例直方图
- 每桶一个值
- 每个存储桶
- 值
- 累积频率
- 非常适合相等和范围条件
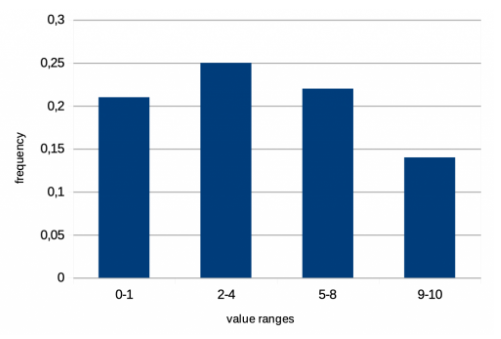
等高直方图
- 每个存储桶有多个值
- 每个存储桶
- 最小值
- 最大值
- 累积频率
- 不同值的数量
- 不是真正的等高:频繁的值在单独的存储桶中
- 非常适合范围条件
如何使用直方图
直方图功能在服务器上可用并已启用,但优化器无法使用。如果没有显式创建,则优化器的工作原理与往常相同,并且无法从直方图基统计中获得任何好处。
需要执行一些手动操作。让我们来看看。
在下一个示例中,我们将使用可从此处下载的世界示例数据库:https : //dev.mysql.com/doc/index-other.html
让我们开始执行一个连接两个表的查询,以找出世界上最大的城市(超过一千万人口)使用的所有语言。
mysql> select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+-----------------+-----------+
| name | language |
+-----------------+-----------+
| Mumbai (Bombay) | Asami |
| Mumbai (Bombay) | Bengali |
| Mumbai (Bombay) | Gujarati |
| Mumbai (Bombay) | Hindi |
| Mumbai (Bombay) | Kannada |
| Mumbai (Bombay) | Malajalam |
| Mumbai (Bombay) | Marathi |
| Mumbai (Bombay) | Orija |
| Mumbai (Bombay) | Punjabi |
| Mumbai (Bombay) | Tamil |
| Mumbai (Bombay) | Telugu |
| Mumbai (Bombay) | Urdu |
+-----------------+-----------+
12 rows in set (0.04 sec)
查询需要0.04秒。数量不多,但是请考虑数据库很小。如果愿意,可以使用BENCHMARK函数获得更多相关的响应时间。
让我们看一下说明:
mysql> explain select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+----+-------------+-----------------+------------+-------+---------------------+-------------+---------+-----------------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+-------+---------------------+-------------+---------+-----------------------------------+------+----------+-------------+
| 1 | SIMPLE | countrylanguage | NULL | index | PRIMARY,CountryCode | CountryCode | 3 | NULL | 984 | 100.00 | Using index |
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3
两个表均使用索引,并且笛卡尔乘积的估计值为984 * 18 = 17,712行。
现在在“ 人口”列上生成直方图。这是用于过滤数据的唯一列,并且没有索引。
为此,我们必须使用ANALYZE命令:
mysql> ANALYZE TABLE city UPDATE HISTOGRAM ON population WITH 1024 BUCKETS;
+------------+-----------+----------+-------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+------------+-----------+----------+-------------------------------------------------------+
| world.city | histogram | status | Histogram statistics created for column 'Population'. |
我们使用1024个存储桶创建了一个直方图。存储桶数不是强制性的,它可以是1到1024之间的任何数字。如果省略,则默认值为100。
块的数量会影响统计信息的可靠性。您拥有的值越独特,所需的块就越多。
现在让我们看一下执行计划,然后再次执行查询。
mysql> explain select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 0.06 | Using where |
| 1 | SIMPLE | countrylanguage | NULL | ref | PRIMARY,CountryCode | CountryCode | 3 | world.city.CountryCode | 984 | 100.00 | Using index |
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
mysql> select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+-----------------+-----------+
| name | language |
+-----------------+-----------+
| Mumbai (Bombay) | Asami |
| Mumbai (Bombay) | Bengali |
| Mumbai (Bombay) | Gujarati |
| Mumbai (Bombay) | Hindi |
| Mumbai (Bombay) | Kannada |
| Mumbai (Bombay) | Malajalam |
| Mumbai (Bombay) | Marathi |
| Mumbai (Bombay) | Orija |
| Mumbai (Bombay) | Punjabi |
| Mumbai (Bombay) | Tamil |
| Mumbai (Bombay) | Telugu |
| Mumbai (Bombay) | Urdu |
+-----------------+-----------+
12 rows in set (0.00 sec)
执行计划不同,查询运行更快。
我们可以注意到,表的顺序与以前相反。即使需要全面扫描,城市表也处于第一阶段。这是因为过滤后的值只有0.06。这意味着完全扫描返回的行中只有0.06%将用于与下表连接。因此,只有4188 * 0.06%= 2.5行。总计,估计的笛卡尔积为2.5 * 984 = 2.460行。这大大低于以前的执行,并解释了为什么查询速度更快。
我们所看到的听起来有点违反直觉,不是吗?实际上,在MySQL 5.7之前,我们习惯于在大多数情况下认为完全扫描非常糟糕。在我们的情况下,取而代之的是,通过对非索引列使用直方图统计信息强制进行全面扫描,可以使查询得到优化。
直方图统计在哪里
直方图统计信息存储在数据字典的column_statistics表中,用户无法直接访问。而是可以将实现为数据字典视图的INFORMATION_SCHEMA.COLUMN_STATISTICS表用于相同的目的。
让我们看看表的统计信息。
mysql> SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, JSON_PRETTY(HISTOGRAM)
-> FROM information_schema.column_statistics
-> WHERE COLUMN_NAME = 'population'\G
*************************** 1. row ***************************
SCHEMA_NAME: world
TABLE_NAME: city
COLUMN_NAME: Population
JSON_PRETTY(HISTOGRAM): {
"buckets": [
[
42,
455,
0.000980632507967639,
4
],
[
503,
682,
0.001961265015935278,
4
],
[
700,
1137,
0.0029418975239029173,
4
],
...
...
[
8591309,
9604900,
0.9990193674920324,
4
],
[
9696300,
10500000,
1.0,
4
]
],
"data-type": "int",
"null-values": 0.0,
"collation-id": 8,
"last-updated": "2019-10-14 22:24:58.232254",
"sampling-rate": 1.0,
"histogram-type": "equi-height",
"number-of-buckets-specified": 1024
}
我们可以看到任何块的最小值和最大值,累积频率和项数。此外,我们可以看到MySQL决定使用等高 直方图。
让我们尝试在另一个表和列上生成直方图。
mysql> ANALYZE TABLE country UPDATE HISTOGRAM ON Region;
+---------------+-----------+----------+---------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+---------------+-----------+----------+---------------------------------------------------+
| world.country | histogram | status | Histogram statistics created for column 'Region'. |
+---------------+-----------+----------+---------------------------------------------------+
1 row in set (0.01 sec)
mysql> SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, JSON_PRETTY(HISTOGRAM) FROM information_schema.column_statistics WHERE COLUMN_NAME = 'Region'\G
*************************** 1. row ***************************
SCHEMA_NAME: world
TABLE_NAME: country
COLUMN_NAME: Region
JSON_PRETTY(HISTOGRAM): {
"buckets": [
[
"base64:type254:QW50YXJjdGljYQ==",
0.02092050209205021
],
[
"base64:type254:QXVzdHJhbGlhIGFuZCBOZXcgWmVhbGFuZA==",
0.04184100418410042
],
[
"base64:type254:QmFsdGljIENvdW50cmllcw==",
0.05439330543933054
],
[
"base64:type254:QnJpdGlzaCBJc2xhbmRz",
0.06276150627615062
],
[
"base64:type254:Q2FyaWJiZWFu",
0.1631799163179916
],
[
"base64:type254:Q2VudHJhbCBBZnJpY2E=",
0.20083682008368198
],
[
"base64:type254:Q2VudHJhbCBBbWVyaWNh",
0.23430962343096232
],
[
"base64:type254:RWFzdGVybiBBZnJpY2E=",
0.3179916317991631
],
[
"base64:type254:RWFzdGVybiBBc2lh",
0.35146443514644343
],
[
"base64:type254:RWFzdGVybiBFdXJvcGU=",
0.39330543933054385
],
[
"base64:type254:TWVsYW5lc2lh",
0.41422594142259406
],
[
"base64:type254:TWljcm9uZXNpYQ==",
0.44351464435146437
],
[
"base64:type254:TWljcm9uZXNpYS9DYXJpYmJlYW4=",
0.4476987447698744
],
[
"base64:type254:TWlkZGxlIEVhc3Q=",
0.5230125523012552
],
[
"base64:type254:Tm9yZGljIENvdW50cmllcw==",
0.5523012552301255
],
[
"base64:type254:Tm9ydGggQW1lcmljYQ==",
0.5732217573221757
],
[
"base64:type254:Tm9ydGhlcm4gQWZyaWNh",
0.602510460251046
],
[
"base64:type254:UG9seW5lc2lh",
0.6443514644351465
],
[
"base64:type254:U291dGggQW1lcmljYQ==",
0.7029288702928871
],
[
"base64:type254:U291dGhlYXN0IEFzaWE=",
0.7489539748953975
],
[
"base64:type254:U291dGhlcm4gQWZyaWNh",
0.7698744769874477
],
[
"base64:type254:U291dGhlcm4gYW5kIENlbnRyYWwgQXNpYQ==",
0.8284518828451883
],
[
"base64:type254:U291dGhlcm4gRXVyb3Bl",
0.891213389121339
],
[
"base64:type254:V2VzdGVybiBBZnJpY2E=",
0.9623430962343097
],
[
"base64:type254:V2VzdGVybiBFdXJvcGU=",
1.0
]
],
"data-type": "string",
"null-values": 0.0,
"collation-id": 8,
"last-updated": "2019-10-14 22:29:13.418582",
"sampling-rate": 1.0,
"histogram-type": "singleton",
"number-of-buckets-specified": 100
}
在这种情况下,将生成单例直方图。
使用以下查询,我们可以查看更多人类可读的统计信息。
mysql> SELECT SUBSTRING_INDEX(v, ':', -1) value, concat(round(c*100,1),'%') cumulfreq,
-> CONCAT(round((c - LAG(c, 1, 0) over()) * 100,1), '%') freq
-> FROM information_schema.column_statistics, JSON_TABLE(histogram->'$.buckets','$[*]' COLUMNS(v VARCHAR(60) PATH '$[0]', c double PATH '$[1]')) hist
-> WHERE schema_name = 'world' and table_name = 'country' and column_name = 'region';
+---------------------------+-----------+-------+
| value | cumulfreq | freq |
+---------------------------+-----------+-------+
| Antarctica | 2.1% | 2.1% |
| Australia and New Zealand | 4.2% | 2.1% |
| Baltic Countries | 5.4% | 1.3% |
| British Islands | 6.3% | 0.8% |
| Caribbean | 16.3% | 10.0% |
| Central Africa | 20.1% | 3.8% |
| Central America | 23.4% | 3.3% |
| Eastern Africa | 31.8% | 8.4% |
| Eastern Asia | 35.1% | 3.3% |
| Eastern Europe | 39.3% | 4.2% |
| Melanesia | 41.4% | 2.1% |
| Micronesia | 44.4% | 2.9% |
| Micronesia/Caribbean | 44.8% | 0.4% |
| Middle East | 52.3% | 7.5% |
| Nordic Countries | 55.2% | 2.9% |
| North America | 57.3% | 2.1% |
| Northern Africa | 60.3% | 2.9% |
| Polynesia | 64.4% | 4.2% |
| South America | 70.3% | 5.9% |
| Southeast Asia | 74.9% | 4.6% |
| Southern Africa | 77.0% | 2.1% |
| Southern and Central Asia | 82.8% | 5.9% |
| Southern Europe | 89.1% | 6.3% |
| Western Africa | 96.2% | 7.1% |
| Western Europe | 100.0% | 3.8% |
在这种情况下,将生成单例直方图。
使用以下查询,我们可以查看更多人类可读的统计信息。
mysql> SELECT SUBSTRING_INDEX(v, ':', -1) value, concat(round(c*100,1),'%') cumulfreq,
-> CONCAT(round((c - LAG(c, 1, 0) over()) * 100,1), '%') freq
-> FROM information_schema.column_statistics, JSON_TABLE(histogram->'$.buckets','$[*]' COLUMNS(v VARCHAR(60) PATH '$[0]', c double PATH '$[1]')) hist
-> WHERE schema_name = 'world' and table_name = 'country' and column_name = 'region';
+---------------------------+-----------+-------+
| value | cumulfreq | freq |
+---------------------------+-----------+-------+
| Antarctica | 2.1% | 2.1% |
| Australia and New Zealand | 4.2% | 2.1% |
| Baltic Countries | 5.4% | 1.3% |
| British Islands | 6.3% | 0.8% |
| Caribbean | 16.3% | 10.0% |
| Central Africa | 20.1% | 3.8% |
| Central America | 23.4% | 3.3% |
| Eastern Africa | 31.8% | 8.4% |
| Eastern Asia | 35.1% | 3.3% |
| Eastern Europe | 39.3% | 4.2% |
| Melanesia | 41.4% | 2.1% |
| Micronesia | 44.4% | 2.9% |
| Micronesia/Caribbean | 44.8% | 0.4% |
| Middle East | 52.3% | 7.5% |
| Nordic Countries | 55.2% | 2.9% |
| North America | 57.3% | 2.1% |
| Northern Africa | 60.3% | 2.9% |
| Polynesia | 64.4% | 4.2% |
| South America | 70.3% | 5.9% |
| Southeast Asia | 74.9% | 4.6% |
| Southern Africa | 77.0% | 2.1% |
| Southern and Central Asia | 82.8% | 5.9% |
| Southern Europe | 89.1% | 6.3% |
| Western Africa | 96.2% | 7.1% |
| Western Europe | 100.0% | 3.8% |
直方图维护
直方图统计信息不会自动重新计算。如果您的表经常被许多INSERT,UPDATE和DELETE更新,则统计信息可能很快就会过时。直方图不可靠会导致优化器选择错误。
当发现直方图对于优化查询很有用时,还需要制定计划的计划以不时刷新统计信息,尤其是在对表进行大量修改之后。
要刷新直方图,您只需要运行我们之前看到的相同的ANALYZE命令。
要完全删除直方图,您可以运行以下命令:
ANALYZE TABLE city DROP HISTOGRAM ON population;
采样
所述histogram_generation_max_mem_size系统变量控制的可用于直方图生成存储器的最大量。全局值和会话值可以在运行时设置。
如果要读取的用于直方图生成的估计数据量超出了变量定义的限制,则MySQL会对数据进行采样,而不是将其全部读取到内存中。采样均匀地分布在整个表中。
默认值是20000000,但是如果希望获得更准确的统计信息,则可以在大列的情况下增加该值。对于非常大的列,请注意不要将阈值增加到大于可用内存的数量,以避免过多的开销或中断。
结论
如示例所示,直方图统计信息对于非索引列特别有用。
通常可以依靠索引的执行计划是最好的,但是直方图在某些情况下或创建新索引时会有所帮助。
由于这不是一项自动功能,因此需要进行一些手动测试以调查您是否真的可以获得直方图的好处。另外,维护需要一些计划的和手动的活动。
如果确实需要直方图,请使用直方图,但不要滥用它们,因为非常大的表上的直方图会占用大量内存。
通常,直方图的最佳候选者是:
- 随时间变化不大的值
- 低基数值
- 分布不均
原文链接:https://www.percona.com/blog/2019/10/29/column-histograms-on-percona-server-and-mysql-8-0/
