




Map 有时能够返回一个值,有时候能够返回多个值,这是 Map 的特权语法。今天继续从底层角度来聊聊 Go 语言内置数据结构,Map。
Map
Map 中大量类似但又冗余的函数,原因之一便是没有泛型。
package main
var m = make(map[int] int, 10)
func main() {
v1 := m[1]
v2, ok := m[2]
println(v1, v2, ok)
}
利用之前提到的工具 go tool objdump 能够获得反汇编后的函数:
make → runtime.makemap
10 → hint
m[1] → runtime.mapaccess1_fast64
m[2] → runtime.mapaccess2_fast64
以上这些过程都是编译器帮我完成的,编译器判断赋值语句,如左边有一个值就翻译为 runtime.mapaccess1_fast64, 需要注意以下三点:
当 hint 大小大于 8 时,采用的是 makemap
当 hint 小于 8 时,采用的是 makemap_small
map 分配栈上时,不一定会调用 makemap
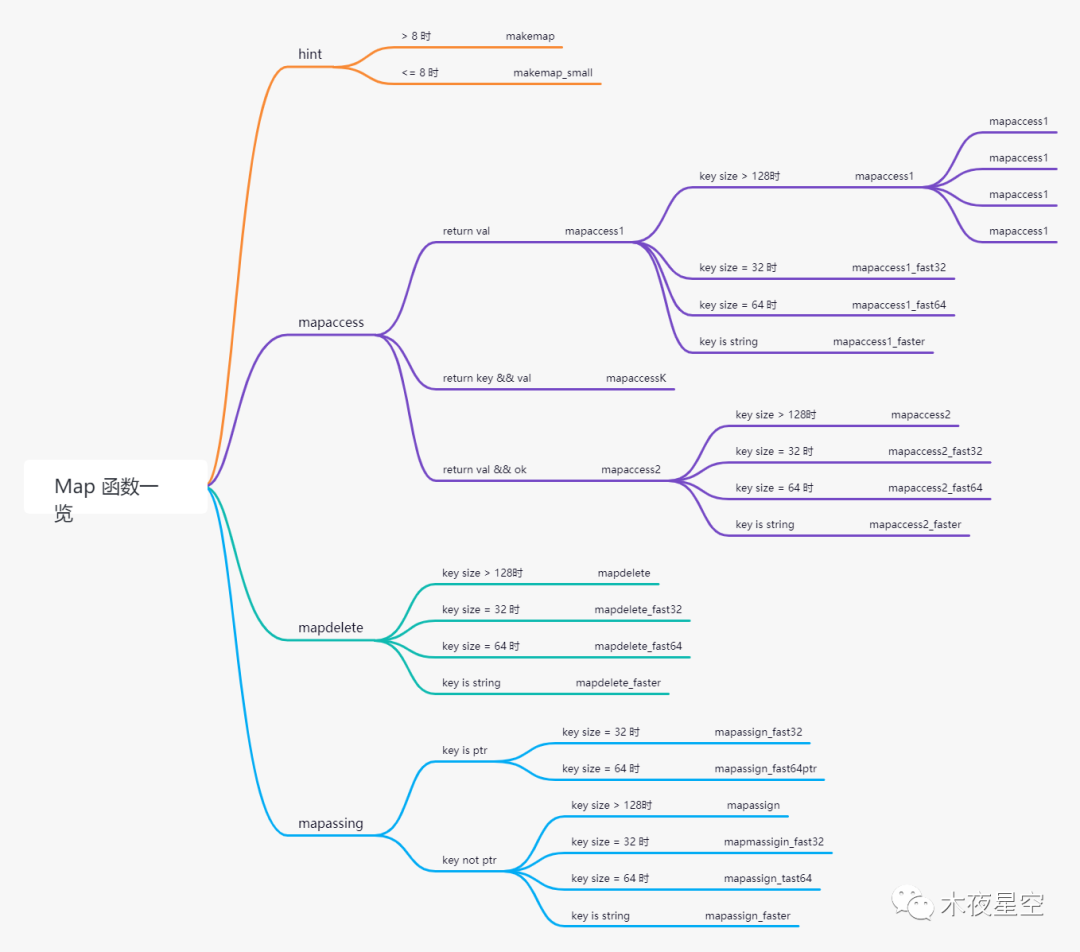
为什么一个 Go 语言内置数据结构就有这么多情况,那如果 Go 的 20 来个内置数据结构都有这种判定,岂不是底层就有差不多 60 个不同判定结构?确实是这样的,map 中存在大量类似但又冗余的函数,但不至于把性能拉低很多。这种问题主要是原因之一是 Go 语言在 1.16 版本前没有泛型。可喜的是,在 Go 1.17 版本之后将会引入泛型,大家感兴趣已经可以自己去尝试了。
曹大有个预见:有了泛型以后,类似 Map 底层函数中的数据结构很有可能有一波大的代码更新,不过也相比于现在的代码来说会轻松点,毕竟现在重复的代码太多了。
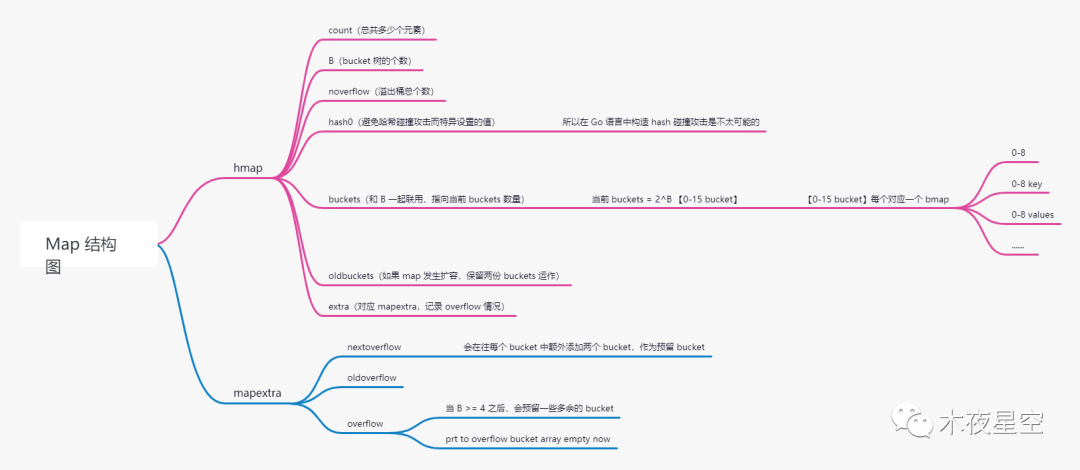
再来看看 Map 的底层结构有哪些:
注:图中有些不严谨的地方,后续会跟进完善,但不影响我们分析。
当我们写了一个 map 数据结构,其实底层对应的是 hamp 这个结构。在 hmap 中,关键的字段可以从图中看到
然后再来看看 Map 元素操作
主要分为三个操作:mapaccess 访问、mapassign 赋值 和 mapdelete 删除。mapaccess 和 mapassign 的原理和操作其实都差不多,具体流程如下:
想要访问一个 map 元素,先对一个 key 做 hash。比如有个 hash values 值是 64 位。这 64 位可以大概分成三部分:开头前八位我们叫做 tophash、最后几位我们叫做 low bits。而这个 low bits 其实是跟 bucket 大小相关的,比如我们 bucket 的大小是 2 的 5次方 32,那么 low bits 就会对 5 做与运算。

具体我们怎么找到,某个元素在 bucket 中存在于什么位置呢?即先对这个 key 做 hash 处理,然后找到 topash 值,根据这个 topash 的值来找到 bucket 中的某个位置。同时在选中之前需要确定 bmap 选的哪个 bucket。
这里的 tophash 其实是和 bmap 的对比,tophash 存在也并不意味着这个 key 是在 Map 中存在的,实际上还需要和 bmap 中的 keys 做个简单对比。如果 topash 和 keys 都是相等,那么才能说明这个 key 是存在的。
有一点疑问了,既然访问和赋值流程差不多,那有什么区别呢?访问找到就结束,而赋值找到了还需要做一步覆盖,如没找到就要找个空填进去(这里也需要解决 hash 冲突问题)。
总结一下三个常见解决 hash 表冲突的方法:
链式寻址
拉链法(Go 语言用的这种),哈希冲突如果放不下,那么就一直回链。
开放地址法
mapdelete 的操作也类似,找到这个值,然后对比 tophash 和 keys,找到了则置空 empty。
Map 扩容
这也是 map 最麻烦的过程。一般而言,扩容在哪个地方出发?访问,赋值还是删除?一般是在 mapassign 中。load factor 过大 或者 overflow bucket 过多的时候,具体流程如下:
从图中可以看到,搬运过程是需要渐进的。
扩容中
mapasssign:将命中的 bucket 从 oldbuckets 顺⼿搬运到buckets 中,顺便再多搬运⼀个 bucket
mapdelete:将命中的 bucket 从 oldbuckets 顺⼿搬运到buckets 中,顺便再多搬运⼀个 bucket
mapaccess: 优先在 oldbuckets 中找,如果命中,则说明这个 bucket 没有被搬运
需要注意:搬运 bucket x 时,会被该桶的 overflow 桶也⼀并搬完
Map 缺陷
最后,来说说 Map 的缺陷:
如果已经扩容,无法进行收缩
保证并发安全时,要手动读写锁,容易出错
多核心下表现较差
难以使用 sync.Pool 进行重用
这些缺陷笔者也并没有都遇到,先简单记录,后续有案例会继续分析和分享。
