




❝论文标题 | HYPA: Efficient Detection of Path Anomalies in Time Series Data on Networks
论文来源 | ICDM 2020
论文链接 | http://www.eliassi.org/papers/hypa-sdm2020.pdf
源码链接 | https://github.com/tlarock/hypa
❞
TL;DR
由于现实复杂网络系统中节点的异构性(特指节点与边的频率统计分布),单纯地基于频率统计进行异常检测不再适用。论文中提出了一种无监督路径异常检测框架 HYPA (Higher-order Hyper-geometric path anomaly detection) 来检测图中不同长度的异常路径,即由于节点访问时序问题造成的路径访问频率次数异常,主要用于入侵检测、异常轨迹识别等。主要想法是将路径异常检测问题转化为 维德·布鲁因图的节点进行图上的边异常检测问题,注意仅是判断图中的长度为 路径是否频率异常。实验部分在交通运输系统数据中验证了算法的有效性。
Algorithm/Model
论文中提出 HYPA 框架如下图所示,
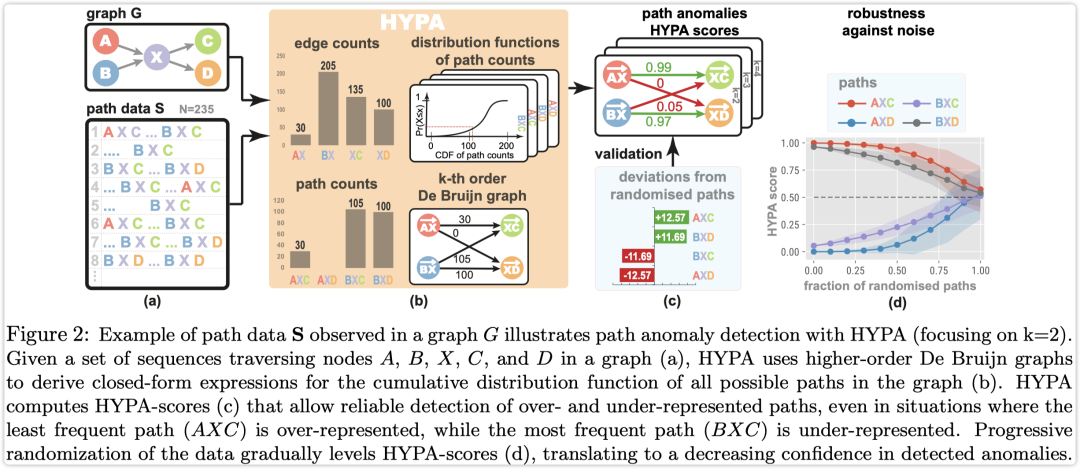
Path Anomaly Detection
首先明确论文中定义的路径异常检测问题:给定序列集合 ,异常路径检测是指统计序列中包含通过图的路径其频率高于或者低于期望值。形式化定义如下:
给定有向图 和包含 个序列 序列集合 ,其中 并且 。对于 ,检测所有包含在 中的路径 频率是否明显偏离 阶路径模型的期望。
论文的主要想法是将一阶图中的「路径异常检测问题」转化为高阶德·布鲁因图 中的「边异常检测问题」,涉及到一个德·布鲁因图转化过程。
德·布鲁因图转化可以参考我的另一篇博文:德布鲁因图 (De Bruijn graph) 与线图 (Line graph)
转化为高阶德·布鲁因图的好处是:可以将路径长度为 的路径异常检测问题转化为 阶德·布鲁因中异常边权重异常检测问题。
k-th order model of paths
对于给定的图 ,令 表示 阶路径德·布鲁因图,对于每条边 利用权重 表示 中子路径 的频率, 表示 的概率转移矩阵为 ,因此 阶模型中路径 的概率为 。
论文中假设随机路径图中的边权重分布符合「多变量超几何分布」,因此使用这个分布的边缘概率来计算每条边的权重:
然后使用边缘概率和边累计分布来计算每条边的 分数,
然后根据计算的分数,再给定阈值 来判断异常。
这个假设太强了,没看懂......可以参考原文,定义多而且论文写的太绕了...
理解为根据假设:结合随机模拟数据、观测数据和边缘分布概率就能算出 阶图中每条边的异常分数。
Experiments
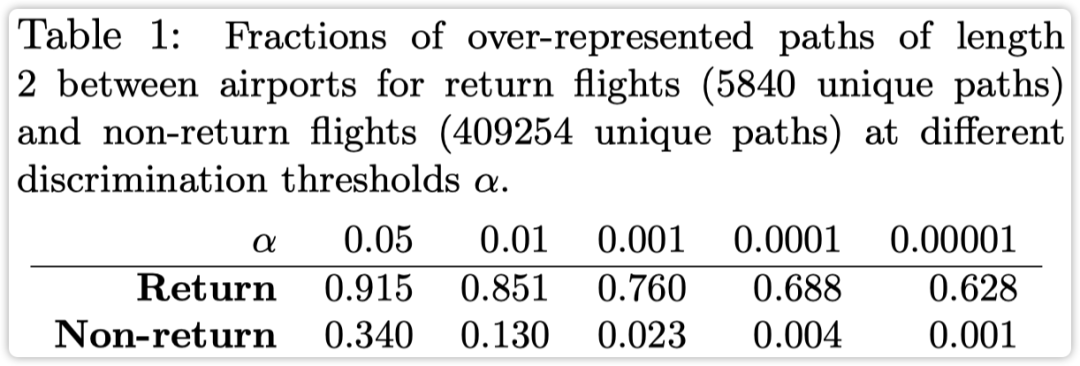
实验结果如下图所示
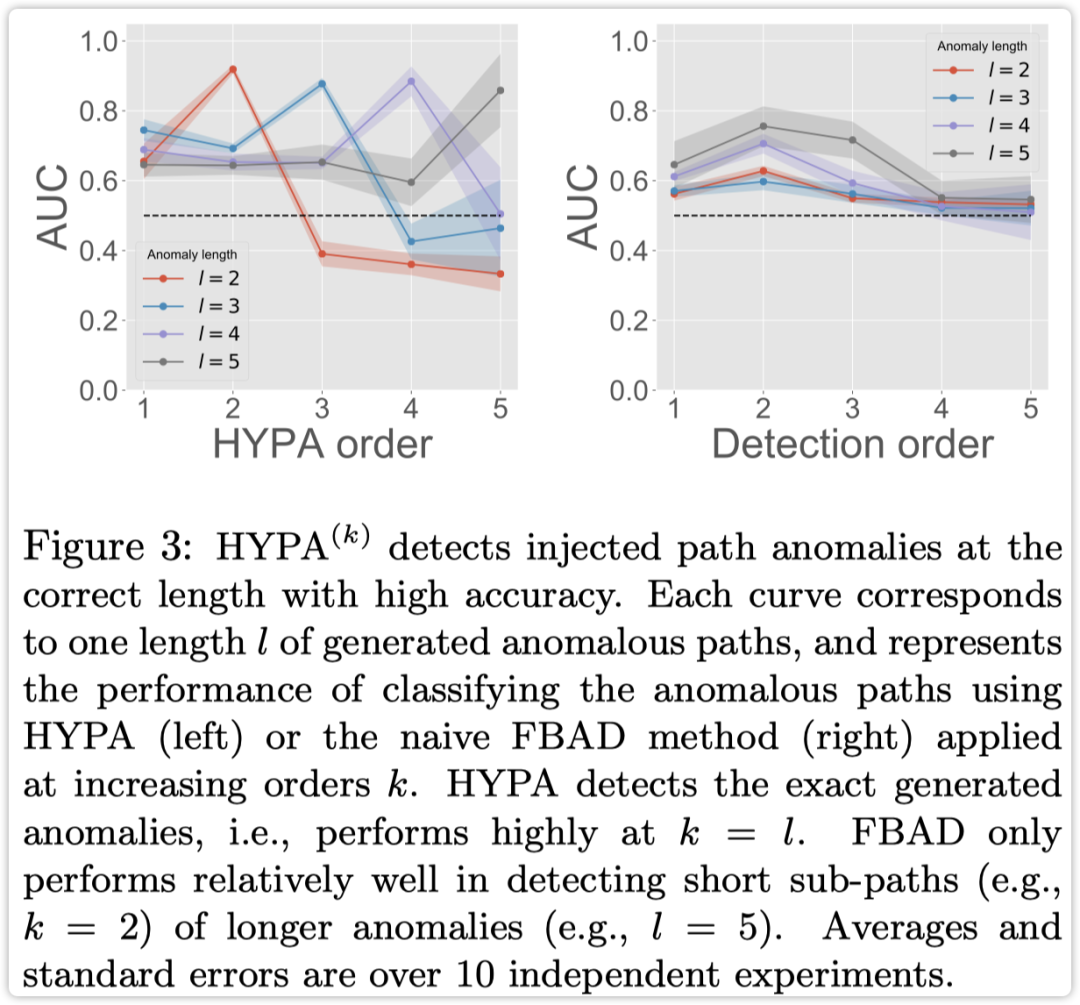
考虑不同参数的对异常路径判断的影响:
Thoughts
论文借德·布鲁因图转化了路径异常检测的表示形式,个人感觉是越搞越复杂,而且根据低阶图和线图来构建高阶德布鲁因图效率会非常低。 论文中的路径异常检测不是直接检测数据 Sequence 异常,而是根据 Sequence 统计检测给定图中所有的路径的异常,有点容易误导。 HYPA 方法仅检测了给定序列中子路径出现频率的异常,没有考虑路径属性、结构问题造成的异常。 对给定的所有序列进行频率偏差异常检测,说明就算给定的序列中没有异常也会检测出异常路径。
dreamhomes
博客:dreamhomes.top
隐形字
公众号:DreamHub



长按识别二维码关注
👇🏻 点击「阅读原文」,排版效果更好哦!
