






读完需要
速读需 3 分钟
Python 2.7
Chrome
Wireshark
Tesseract-ocr + Pytesseract
1. 首先利用chrome浏览器查看登录页面的验证码地址的对应的请求地址。

2. 然后查看登录时请求的地址(注意不是登录页面的地址,如果错误会发生异常)。
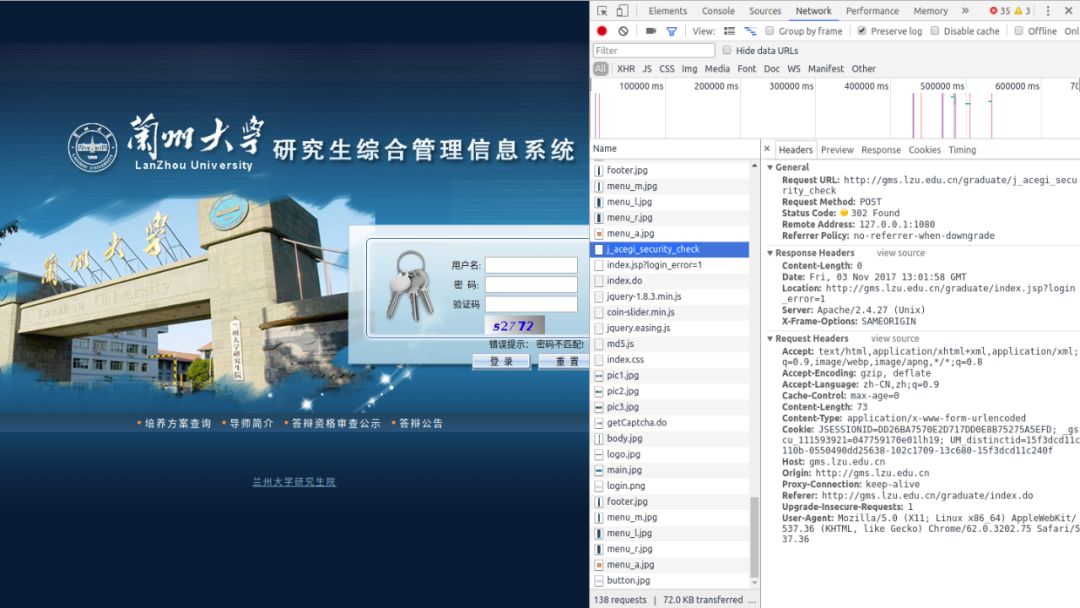
3. 对于网页中的验证码,先下载到本地然后再展示出来供用户手动输入。
# -*- coding:utf-8 -*-'''Created on 2017年10月30日@summary: 利用Python爬虫爬取研究生教务系统信息@author: dreamhome'''import urllibimport urllib2import cookielibimport reimport jsonimport matplotlib.pyplot as pltimport matplotlib.image as mpimg # mpimg 用于读取图片from bs4 import BeautifulSouploginUrl = "http://gms.lzu.edu.cn/graduate/j_acegi_security_check"#cookiecookie = cookielib.CookieJar()handler = urllib2.HTTPCookieProcessor(cookie)opener = urllib2.build_opener(handler)#postdatavalues = {'j_username':'','j_password':'','j_captcha':''}#headersheader = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36','Referer':'http://gms.lzu.edu.cn/graduate/j_acegi_security_check'}#输入学号print "请输入学号:"values['j_username']=raw_input()#输入密码print "请输入密码:"values['j_password']=raw_input()#获取验证码validate_number=opener.open("http://gms.lzu.edu.cn/graduate/getCaptcha.do?")validate_number_data=validate_number.read()validate_number_pic=file("validate.jpg",'wb')validate_number_pic.write(validate_number_data)validate_number_pic.close()#显示验证码validate = mpimg.imread('validate.jpg')plt.imshow(validate)plt.axis('off') # 不显示坐标轴plt.show()#输入验证码print '请输入验证码:'values['j_captcha']=raw_input()#模拟登陆postdata = urllib.urlencode(values)request = urllib2.Request(loginUrl,postdata,header)response = opener.open(request)score_url = 'http://gms.lzu.edu.cn/graduate/studentscore/queryScore.do?groupId=&moduleId=25011'response = opener.open(score_url)html=response.read()#判断登录是否成功if "权限不够,访问被拒绝" in html:print "登录信息错误,请重新登录"exit()#简单数据解析soup = BeautifulSoup(html.decode('utf8'),'lxml')trs = soup.findAll('tr')score_data=[]for tr in trs:row=tr.get_text().split()temp_row=[]for x in row:temp_row.append(x.strip())score_data.append(temp_row)#输出成绩信息for x in range(len(score_data)):for y in score_data[x]:print y,
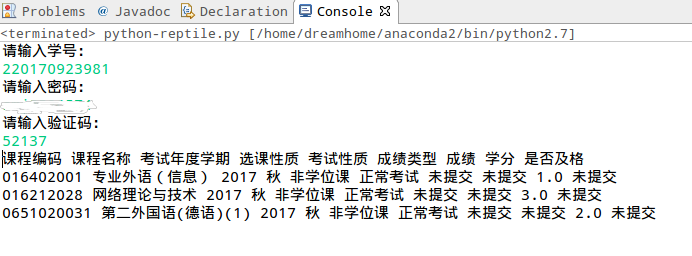
拓展
1.tesseract-ocr安装sudo apt-get install tesseract-ocr2.pytesseract安装sudo pip install pytesseract
from PIL import Imageimport pytesseract# 自动识别验证码image=Image.open('validate.jpg')code= pytesseract.image_to_string(image)print code
dreamhomes
博客:梦家の博客
隐形字
公众号:DreamHub



长按识别二维码关注
文章转载自AISeer,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
