




↑ 点击关注 ↑ 更多技术干货
目前我们的 flink 任务跑在 yarn 集群上,在面对以下问题时
1. 常驻实时 job 是否在稳定运行?
2. 实时数据的处理能力如何?消费过慢?是否需要申请更多资源提升消费能力?
3. 实时数据质量可靠?是否有丢数据的风险?
4. 实时任务现有的资源是否足够支撑现有的数据量?资源是否闲置浪费?
虽然 flink web ui 提供了一些监控信息,但是对开发还是不够友好,所以我们利用 flink metrics + prometheus + grafana 搭建了一套实时监控看板,有利于收集 flink 任务的实时状态。
首先介绍下 Flink Metric
1. Metric Types
Counter: 表示收集的数据是按照某个趋势(增加/减少)一直变化的
Gauge: 表示搜集的数据是一个瞬时的值,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
Histogram: 统计数据的分布情况。
Meter:度量一系列事件发生的速率(rate)。
2. Metric Reporters
Metrics 信息可以通过 flink-conf.yaml 配置,在 job 启动的时候实时上报到外部系统上。
3. System Metrics
Flink 内部会预定义一些 Metrics 指标信息,包含 CPU,Memory, IO,Thread,Network, JVM GarbageCollection 等信息
4. User Defined Metrics
用户可以自己根据自己的业务需要,自定义一些监控指标
val counter = getRuntimeContext().getMetricGroup().addGroup("MyMetricsKey", "MyMetricsValue").counter("myCounter")
Metric 监控搭建
1. 梳理监控指标
系统指标
job 数量的监控
1. 常驻 job 数量的监控
2. 及时发现 job 运行过程中的重启,失败问题
算子消息处理的numRecordsIn 和 numRecordsOut
1. 线图趋势掌握任务处理的负载量
2. 及时发现job资源分配是否合理,尽量避免消息波动带来的系统延迟增高
消息延迟监控
1. Flink 算子之间消息传递的最大,最小,平均延迟。
2. 及时发现任务消息的处理效率波动
内存,JVM GC 的状态
1. taskmanager 的内存,GC 状态的线图波动。
2. 及时发现系统中资源的利用率,合理分配集群资源。
b. 自定义监控指标
1. Source 端我们采用 kafka 作为数据的输入源
通过监控 kafka consumer group 的 lagOffset 来发现flow 的数据消费能力是否有降低。
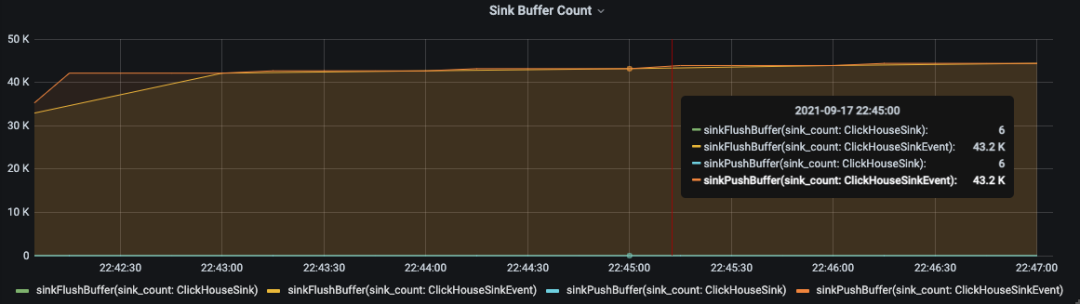
2. Sink 端我们自己实现了 clickhouse,hbase,hive,kafka 等多端输出,为了避免 Flink 的流式处理对 Sink 终端造成过大的写入压力,我们抽象了一个批次的 buffer cache,当数据的批次达到了阀值,或者 buffer cache 一定的时间间隔,就将 buffer cache 内的数据一次性 doFlush 到各端存储, 各个 sink实例 只需实现BucketBufferedSink.doFlush 方法
由于 Sink 过程中,可能面临部分 buffer cache 中的数据在 flush 过程中因为某种原因失败而导致数据丢失,所以必须要及时发现数据不一致,以便重跑任务恢复数据。我们在 BucketBufferedSink 之上抽象了 SinkMetric,并在 BucketBufferedSink.addBuffer() 做了 sinkPushCounter.inc 埋点计数BucketBufferedSink.flush() 做了 sinkFlushCounter.inc()
sinkPushCounter 统计进入到 buffercache 的数据条数
sinkFlushCounter 统计 buffercache flush 出去的数据条数
2. 实施搭建监控系统
系统部署图

在 flink-conf.yml 中 配置 flink metrics reporter,可让 flink 自动的上报 metric 信息
1)通过 flink run-yD metrics.reporter.grph.prefix="${JOB_NAME}" 的方式可动态指定各个实时任务的监控进行分组。
2)通过 metrics.latency.interval: 30000 设置每 30s flink 自动上报算子之间的延迟信息。
Graphite-exporter 作为 prometheus 收集系统的网关,是所有metric 信息的上报入口
1)通过配置 mapping.yml 转化为有 label 维度的 Prometheus 数据,推送给 Prometheus
mappings:- match: 'flink\.([\w-]+)\.(.*)\.taskmanager\.(\w+)\.Status\.(\w+)\.(\w+)\.([\w-]+)\.(\w+)'match_type: regexname: flink_taskmanager_Status_${4}_${5}_${6}_${7}labels:host: $2container: $3job_name: $1- match: 'flink\.([\w-]+)\.(.*)\.taskmanager\.(\w+)\.([\w-]+)\.(.+)\.(\d+)\.Shuffle\.Netty\.(.*)'match_type: regexaction: dropname: dropped- match: 'flink\.([\w-]+)\.(.*)\.taskmanager\.(\w+)\.([\w-]+)\.(.+)\.(\d+)\.(.*)\.(Buffers|buffers)\.(.*)$'match_type: regexaction: dropname: dropped- match: 'flink\.([\w-]+)\.(.*)\.taskmanager\.(\w+)\.([\w-]+)\.(.+)\.(\d+)\.([\w]+)\-([\w]+)\.(\w+)'match_type: regexname: flink_taskmanager_operator_${7}_${9}labels:host: $2container: $3job_name: $1operator: $5task: $6custom_metric: $7sink_instance: $8- match: 'flink\.([\w-]+)\.(.*)\.taskmanager\.(\w+)\.([\w-]+)\.(.+)\.(\d+)\.([\w-]+)\.(\w+)'match_type: regexname: flink_taskmanager_operator_${7}_${8}labels:host: $2container: $3job_name: $1operator: $5task: $6- match: 'flink\.([\w-]+)\.(.*)\.jobmanager\.Status\.(.*)'match_type: regexname: flink_jobmanager_Status_$3labels:host: $2job_name: $1- match: 'flink\.([\w-]+)\.(.*)\.jobmanager.(\w+)$'match_type: regexname: flink_jobmanager_${3}labels:host: $2job_name: $1- match: 'flink\.([\w-]+)\.(.*)\.jobmanager.(.*)\.(\w+)'match_type: regexname: flink_jobmanager_${4}labels:host: $2job_name: $1- match: 'flink\.([\w-]+)\.(.*)\.jobmanager.(.*)\.(.*)\.(.*)'match_type: regexname: flink_jobmanager_${4}_${5}labels:host: $2job_name: $1- match: "."match_type: regexaction: dropname: "dropped"
实时监控看板展示
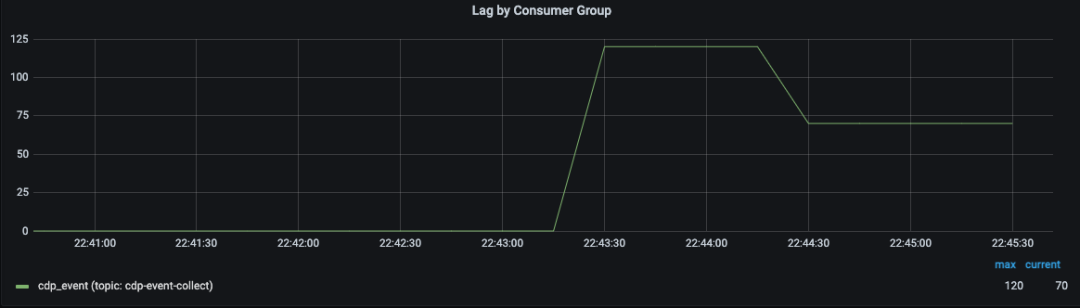
2. 通过检测在线运行 Job 数量,及时发现Job运行失败的问题。
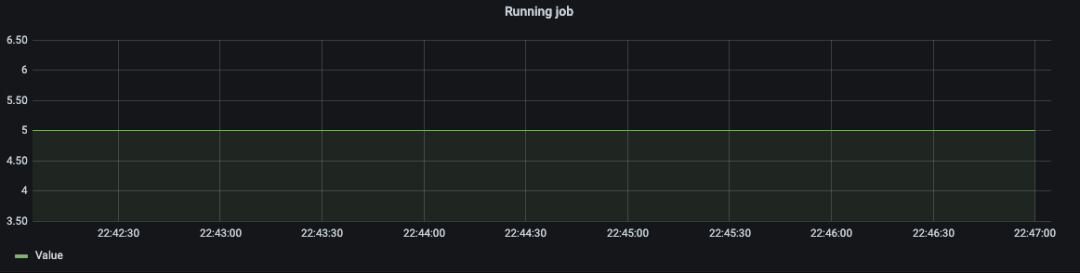
3. 通过统计 Source 端 和 Sink 端的消息处理速度,及时反应当前任务的处理能力。

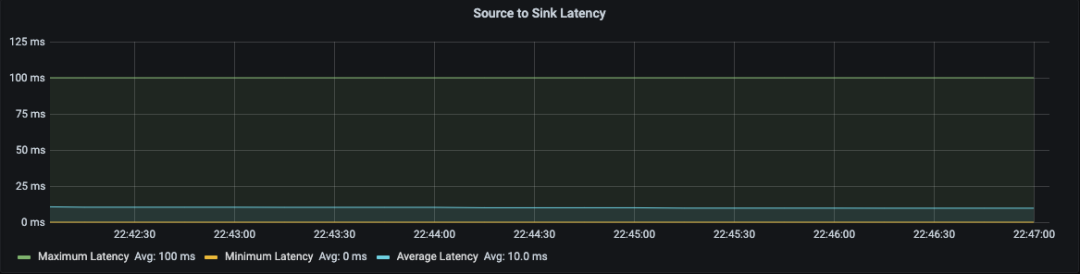
4. 通过消息的延时指标,发现 Job 的流处理的响应延迟。
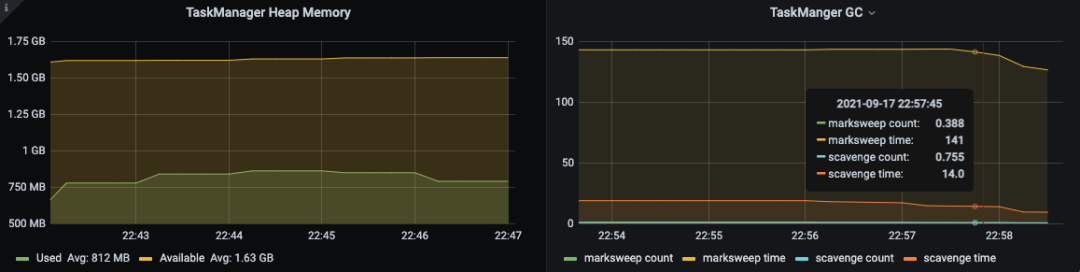
5. 通过 Jvm 内存及 GC 状态,合理分配系统资源。
6. 通过Sink 算子的 Push to BufferCache 数量与 BufferCache Flush 到各端存储数量的对比,及时发现数据丢失问题。
引用文章
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/ops/metrics/
https://github.com/prometheus/graphite_exporter
https://prometheus.io/docs/introduction/overview/
https://grafana.com/docs/?plcmt=footer
作者:王通|后端、大数据工程师
关于 GrowingIO
作为国内领先的一站式数据增长引擎整体方案服务商,GrowingIO以数据智能分析为核心,通过构建客户数据平台,打造增长营销闭环,帮助企业提升数据驱动能力,赋能商业决策、实现业务增长。
GrowingIO专注于零售、电商、保险、酒旅航司、教育、内容社区等行业,成立以来,累计服务超过1500家企业级客户,获得LVMH集团、百事、达能、老佛爷百货、戴尔、lululemon、美素佳儿、宜家、乐高、美的、海尔、安踏、汉光百货、上汽集团、广汽蔚来、理想汽车、招商仁和人寿、飞鹤、红星美凯龙、东方航空、滴滴、新东方、喜茶、每日优鲜、奈雪的茶、永辉超市等客户的青睐。
招聘信息
GrowingIO技术团队是一个活力四射、对技术充满激情的团队,多个岗位持续招聘中!诚招前端工程师/大数据工程师/Java工程师等,欢迎有兴趣的同学投递简历至:jianli@growingio.com(邮件标题请注明具体岗位名称),更多职位及信息可进入招聘官网查看。

点击「阅读原文」获取 GrowingIO 15 天免费试用!
↓↓↓
