




看过上一章节的朋友对hive已经有了初步的了解,本章节说说hive的简单使用。
hive如何安装这里就不啰嗦了,大家可自行百度,但是要记得安装下mysql哦,mysql是作为元数据管理的。
安装好mysql后不要忘记配置hive-site.xml:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- hive元数据的存储位置 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://laifeiyang03:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false</value><description>JDBC connect string for a JDBC metastore</description></property><!-- 指定驱动程序 --><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><!-- 连接数据库的用户名 --><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value><description>username to use against metastore database</description></property><!-- 连接数据库的口令 --><property><name>javax.jdo.option.ConnectionPassword</name><value>12345678</value><description>password to use against metastore database</description></property><property><!-- 数据默认的存储位置(HDFS) --><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property><property><!-- 在命令行中,显示当前操作的数据库 --><name>hive.cli.print.current.db</name><value>true</value><description>Whether to include the current database in the hive prompt.</description></property><property><!-- 在命令行中,显示数据的表头 --><name>hive.cli.print.header</name><value>true</value></property><property><!-- 操作小规模数据时,使用本地模式,提高效率 --><name>hive.exec.mode.local.auto</name><value>true</value><description>Let Hive determine whether to run in local mode automatically</description></property><!--指定metastore地址,之前添加过可以不添加 --><property><name>hive.metastore.uris</name><value>thrift://laifeiyang01:9083,thrift://laifeiyang03:9083</value></property><property><name>hive.metastore.client.socket.timeout</name><value>3600</value></property></configuration>
备注:
注意jdbc的连接串,如果没有 useSSL=false 会有大量警告。
在xml文件中 & 表示 &。
还需要拷贝,mysql的驱动到hive安装目录的lib下。
最后启动hive:

查看参数配置信息:
--查看全部参数
hive> set;
-- 查看某个参数
hive> set hive.exec.mode.local.auto;
hive.exec.mode.local.auto=false
参数配置的三种方式:
1、用户自定义配置文件(hive-site.xml)
2、启动hive时指定参数(-hiveconf)
3、hive命令行指定参数(set)
配置信息的优先级:
set > -hiveconf > hive-site.xml > hive-default.xml
启动Hive时,可以在命令行添加 -hiveconf param=value 来设定参数,这些设定仅对本次启动有效。
# 启动时指定参数
hive -hiveconf hive.exec.mode.local.auto=true
hive命令这里不多说,可以hive命令进去查,也可以hive -e “sql” 不进入hive窗口操作数据。
hive数据类型
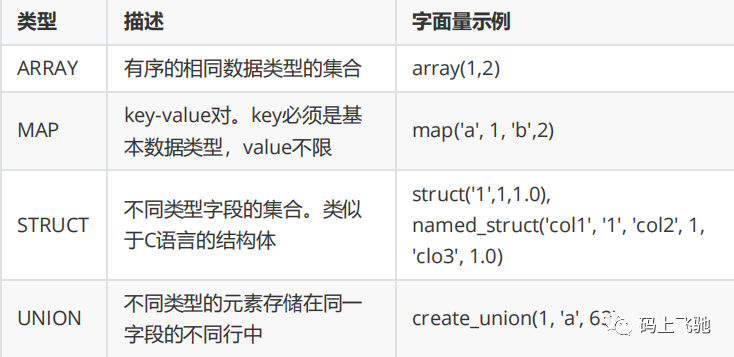
Hive支持关系型数据库的绝大多数基本数据类型,同时也支持4种集合数据类型。
Hive类似和java语言中一样,会支持多种不同长度的整型和浮点类型数据,同时也支持布尔类型、字符串类型,时间戳数据类型以及二进制数组数据类型等。具体的如下表:
Hive的数据类型是可以进行隐式转换的,类似于Java的类型转换。如用户在查询中将一种浮点类型和另一种浮点类型的值做对比,Hive会将类型转换成两个浮点类型中值较大的那个类型,即:将FLOAT类型转换成DOUBLE类型;当然如果需要的话,任意整型会转化成DOUBLE类型。Hive 中基本数据类型遵循以下层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。如下图:
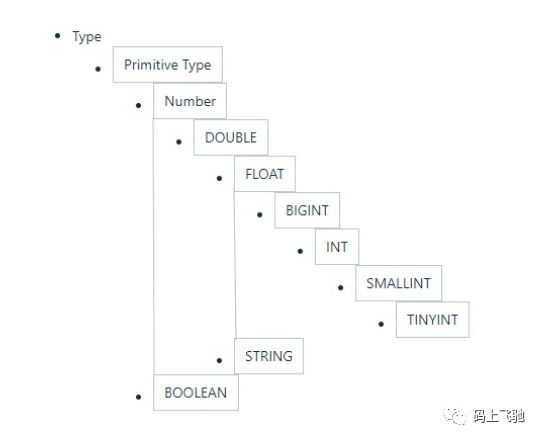
Hive支持集合数据类型,包括array、map、struct、union
文本文件数据编码:

读时模式:
在传统数据库中,在加载时发现数据不符合表的定义,则拒绝加载数据。数据在写入数据库时对照表模式进行检查,这种模式称为"写时模式"(schema on write)。
写时模式 -> 写数据检查 -> RDBMS
Hive中数据加载过程采用"读时模式" (schema on read),加载数据时不进行数据格式的校验,读取数据时如果不合法则显示NULL。这种模式的优点是加载数据迅速。
读时模式 -> 读时检查数据 -> Hive;好处:加载数据快;问题:数据显示NULL
内部表 & 外部表:
在创建表的时候,可指定表的类型。表有两种类型,分别是内部表(管理表)、外部表。
默认情况下,创建内部表。如果要创建外部表,需要使用关键字 external
在删除内部表时,表的定义(元数据) 和 数据 同时被删除
在删除外部表时,仅删除表的定义,数据被保留
在生产环境中,多使用外部表
分区表:
Hive在执行查询时,一般会扫描整个表的数据。由于表的数据量大,全表扫描消耗时间长、效率低。而有时候,查询只需要扫描表中的一部分数据即可,Hive引入了分区表的概念,将表的数据存储在不同的子目录中,每一个子目录对应一个分区。只查询部分分区数据时,可避免全表扫描,提高查询效率。在实际中,通常根据时间、地区等信息进行分区。
分桶表:
当单个的分区或者表的数据量过大,分区不能更细粒度的划分数据,就需要使用分桶技术将数据划分成更细的粒度。将数据按照指定的字段进行分成多个桶中去,即将数据按照字段进行划分,数据按照字段划分到多个文件当中去。
装载数据(Load)
一般hive导入文件数据,用load即可:
load data local inpath '/home/servers/test/clicklog.dat'into table user_clicklog;
数据导入:load data insert create table .... as select ..... import table
数据导出:insert overwrite ... diretory ... hdfs dfs -get hive -e "select ..." >a.log export table ...
Hive的数据导入与导出还可以使用其他工具:Sqoop、DataX等;
元数据管理与存储
Metastore
在Hive的具体使用中,首先面临的问题便是如何定义表结构信息,跟结构化的数据映射成功。所谓的映射指的是一种对应关系。在Hive中需要描述清楚表跟文件之间的映射关系、列和字段之间的关系等等信息。这些描述映射关系的数据的称之为Hive的元数据。该数据十分重要,因为只有通过查询它才可以确定用户编写sql和最终操作文件之间的关系
Metadata即元数据。元数据包含用Hive创建的database、table、表的字段等元信息。元数据存储在关系型数据库中。如hive内置的Derby、第三方如MySQL等。
Metastore即元数据服务,是Hive用来管理库表元数据的一个服务。有了它上层的服务不用再跟裸的文件数据打交道,而是可以基于结构化的库表信息构建计算框架
通过metastore服务将Hive的元数据暴露出去,而不是需要通过对Hive元数据库mysql的访问才能拿到Hive的元数据信息;metastore服务实际上就是一种thrift服务,通过它用户可以获取到Hive元数据,并且通过thrift获取元数据的方式,屏蔽了数据库访问需要驱动,url,用户名,密码等细节。
metastore三种配置方式
1:内嵌模式:
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外启动Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
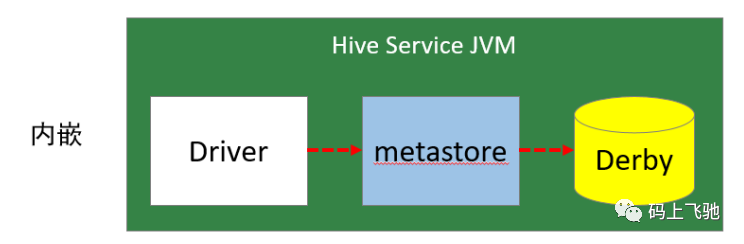
优点:配置简单,解压hive安装包 bin/hive 启动即可使用;
缺点:不同路径启动hive,每一个hive拥有一套自己的元数据,无法共享。
本地模式:
本地模式采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server。作者采用的是MySQL。本地模式不需要单独起metastore服务,用的是跟Hive在同一个进程里的metastore服务。也就是说当启动一个hive 服务时,其内部会启动一个metastore服务。Hive根据 hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
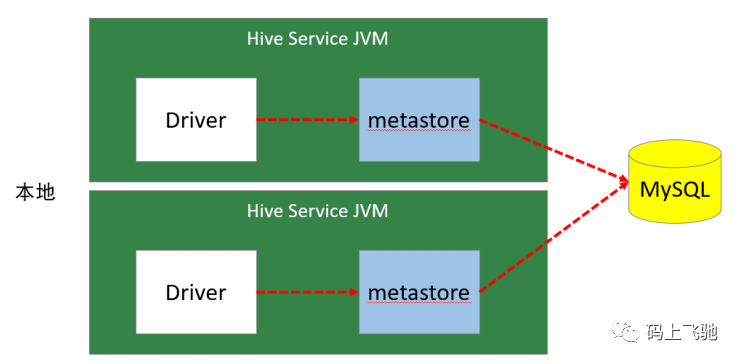
缺点:每启动一次hive服务,都内置启动了一个metastore;在hive-site.xml中暴露的数据库的连接信息;
优点:配置较简单,本地模式下hive的配置中指定mysql的相关信息即可。
远程模式:
远程模式下,需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。在生产环境中,建议用远程模式来配置Hive Metastore。
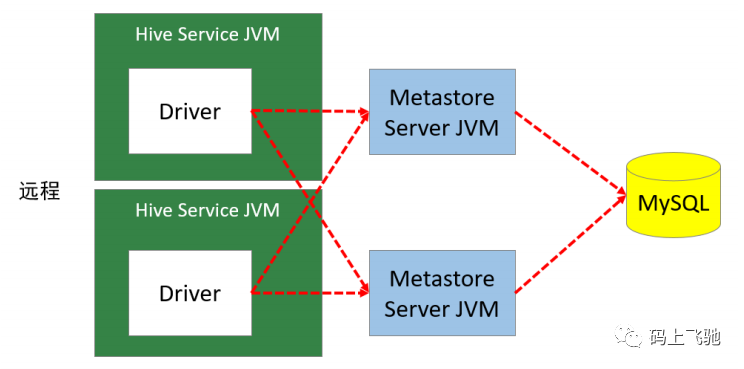
在这种模式下,其他依赖Hive的软件都可以通过Metastore访问Hive。此时需要配置hive.metastore.uris 参数来指定 metastore 服务运行的机器ip和端口,并且需要单独手动启动metastore服务。metastore服务可以配置多个节点上,避免单节点故障导致整个集群的hive client不可用。同时hive client配置多个metastore地址,会自动选择可用节点。
HiveServer2
HiveServer2是一个服务端接口,使远程客户端可以执行对Hive的查询并返回结果。目前基于Thrift RPC的实现是HiveServer的改进版本,并支持多客户端并发和身份验证,启动hiveServer2服务后,就可以使用jdbc、odbc、thrift 的方式连接。Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。

HiveServer2(HS2)是一种允许客户端对Hive执行查询的服务。HiveServer2是HiveServer1的后续版本。HS2支持多客户端并发和身份验证,旨在为JDBC、ODBC等开放API客户端提供更好的支持。HS2包括基于Thrift的Hive服务(TCP或HTTP)和用于Web UI 的Jetty Web服务器。
HiveServer2作用:
1:为Hive提供了一种允许客户端远程访问的服务。
2:基于thrift协议,支持跨平台,跨编程语言对Hive访问。
3:允许远程访问Hive
数据存储格式:
Hive支持的存储数据的格式主要有:TEXTFILE(默认格式) 、SEQUENCEFILE、RCFILE、ORCFILE、PARQUET。
textfile为默认格式,建表时没有指定文件格式,则使用TEXTFILE,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
sequencefile、rcfile、orcfile格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入sequencefile、rcfile、orcfile表中。
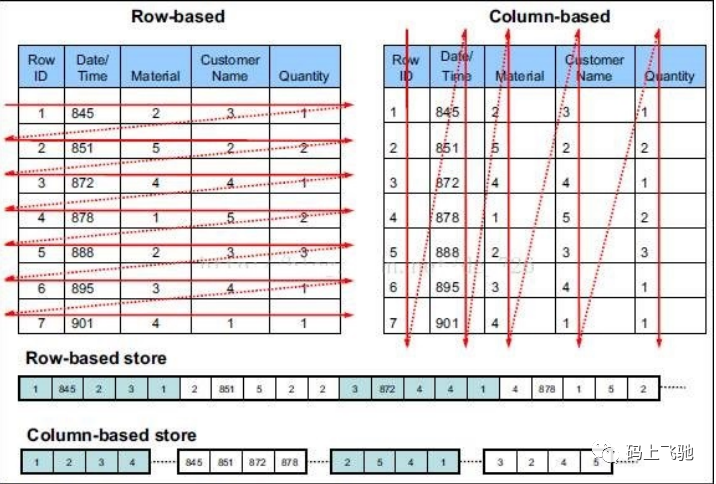
行存储与列存储:
行式存储下一张表的数据都是放在一起的,但列式存储下数据被分开保存了。
行式存储:
优点:数据被保存在一起,insert和update更加容易
缺点:选择(selection)时即使只涉及某几列,所有数据也都会被读取
列式存储:
优点:查询时只有涉及到的列会被读取,效率高
缺点:选中的列要重新组装,insert/update比较麻烦
TEXTFILE、SEQUENCEFILE 的存储格式是基于行存储的;
ORC和PARQUET 是基于列式存储的。
TextFile:
Hive默认的数据存储格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作
SEQUENCEFILE:
SequenceFile是Hadoop API提供的一种二进制文件格式,其具有使用方便、可分割、可压缩的特点。SequenceFile支持三种压缩选择:none,record,block。Record压缩率低,一般建议使用BLOCK压缩。
RCFile:
RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对数据文件。RCFile结合列存储和行存储的优缺点,是基于行列混合存储的RCFile。
RCFile遵循的“先水平划分,再垂直划分”的设计理念。先将数据按行水平划分为行组,这样一行的数据就可以保证存储在同一个集群节点;然后在对行进行垂直划分。
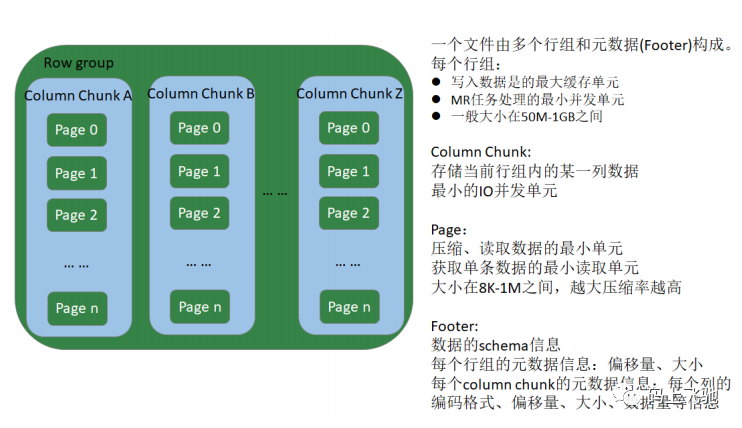
ORCFile:
ORC File,它的全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化,在hive 0.11中引入的存储格式。这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。
Parquet:
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Mapreduce、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),与语言和平台无关的。
Parquet文件是以二进制方式存储的,不能直接读取的,文件中包括实际数据和元数据,Parquet格式文件是自解析的。
在生产环境中,Hive表的数据格式使用最多的有三种:TextFile、ORCFile、Parquet。
TextFile文件更多的是作为跳板来使用(即方便将数据转为其他格式)
有update、delete和事务性操作的需求,通常选择ORCFile
没有事务性要求,并且希望支持Impala、Spark,建议选择Parquet

