




翻译:尚凯
审核:魏波
目录
1 结构
2 例子
3 哈希语义
4 属性
5 内部
结构
1.普遍理论
现代许多编程语言都将哈希表作为基本的数据类型。在外部,哈希表看起来像一个常规数组,它使用任何数据类型(例如字符串)而不是整数作为索引。PostgreSQL中的哈希索引也是以类似的方式构造的。那么它是如何运作的?通常,数据类型的允许值范围非常大:在“text”类型的列中我们可以设想多少个不同的字符串?同时,在某个表的文本列中实际存储了多少个不同的值?通常情况下,没有那么多。
哈希的思想是将少量的数字(从0到N -1,总共N个值)与任何数据类型的值相关联。这样的关联称为哈希函数。所获得的数字可用作常规数组的索引,其中将存储对表行(TID)的引用。该数组的元素称为哈希表存储桶(bucket)-如果相同的索引值出现在不同的行中,则一个存储桶可以存储多个TID。
哈希函数按存储桶分配源值的方式越统一,效果越好。但是,即使是一个良好的哈希函数,有时也会对不同的源值产生相等的结果——这称为冲突。一个存储桶可以存储对应于不同键的TID,但因此需要重新检查从索引获得的TID。
举个例子:我们可以想到字符串的哪些哈希函数?假设存储桶的数量为256。然后,以桶的编号为例,我们可以采用第一个字符的代码(假设单字节字符编码)。这是一个很好的哈希函数吗?显然不是:如果所有字符串都以相同的字符开头,则所有字符串都将放入一个存储桶中,因此毫无疑问是统一的,所有值都需要重新检查,哈希将毫无意义。如果我们将所有以256为模的字符的代码相加怎么办?这样会更好,但远非理想。如果您对PostgreSQL中这种哈希函数的内部结构感兴趣,请查看hashfunc.c中hash_any()的定义。
2.索引结构
让我们回到哈希索引。对于某些数据类型(索引键)的值,我们的任务是快速找到匹配的TID。
当插入索引时,让我们计算键的哈希函数。PostgreSQL中的哈希函数总是返回«integer»类型,其范围为2的32次方≈40亿个值。存储桶的数量最初等于2,然后根据数据大小动态增加。存储桶编号可以使用位算法从哈希码中计算出来。这是我们将放置TID的存储桶。
但这还不够,因为可以将与不同键匹配的TID放入同一存储桶中。我们该怎么办?除了TID之外,还可以将键的源值存储在存储桶中,但这会大大增加索引大小。为了节省空间,存储桶不存储键,而是存储了键的哈希代码。
当搜索索引时,我们计算键的哈希函数并获取存储桶编号。现在,仍然需要遍历存储桶的内容,并仅返回具有适当哈希码的匹配TID。由于存储的“hash code - TID”对是有序的,因此可以高效地完成此操作。
但是,两个不同的键不仅可能会进入一个存储桶,而且可能会具有相同的四字节哈希码——没有人能消除冲突。因此,访问方法要求通用索引引擎通过重新检查表行中的条件来验证每个TID(引擎可以在进行可见性检查的同时执行此操作)。
3.将数据结构映射到页面
如果我们从缓冲区缓存管理器的角度而不是从查询计划和执行的角度看待索引,那么所有信息和所有索引行都必须打包到页面中。这样的索引页存储在缓存中,并以与表页完全相同的方式从缓存中删除。
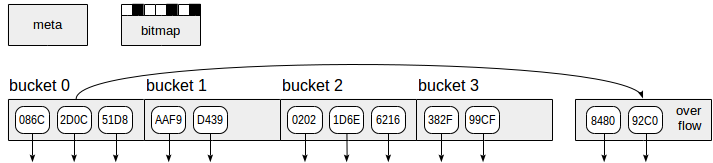
如图所示,哈希索引使用四种页面(灰色矩形):
• 元页面-第0页,其中包含有关索引内部内容的信息。
• 存储桶页面-索引的主页,将数据存储为“哈希码-TID”对。
• 溢出页面-与存储桶页面的结构相同,当一个存储桶超出一个页面时使用。
• 位图页面-跟踪当前清除的溢出页面,这些页面可重新用于其他存储桶。
从索引页元素开始的向下箭头表示TID,即对表行的引用。
每次索引增加,PostgreSQL即时创建的存储桶(也就是页面)数量是上次创建的存储桶数量的两倍。为了避免一次分配大量潜在的页面,版本10使大小增加更加平稳。对于溢出页面,它们会根据需要进行分配,并在位图页面中进行跟踪,位图页面也会根据需要进行分配。
请注意,哈希索引不能减小大小。如果我们删除一些索引行,则已经分配的页面不会返回给操作系统,而只会在VACUUMING之后重新用于新数据。减小索引大小的唯一选项是使用REINDEX或VACUUM FULL命令从头开始重建索引。
例子
让我们看看如何创建哈希索引。为了避免设计自己的表,从现在开始,我们将使用航空运输的演示数据库,这次我们将使用flights表。
demo=# create index on flights using hash(flight_no);WARNING: hash indexes are not WAL-logged and their use is discouragedCREATE INDEXdemo=# explain (costs off) select * from flights where flight_no = 'PG0001';QUERY PLAN----------------------------------------------------Bitmap Heap Scan on flightsRecheck Cond: (flight_no = 'PG0001'::bpchar)-> Bitmap Index Scan on flights_flight_no_idxIndex Cond: (flight_no = 'PG0001'::bpchar)(4 rows)
当前哈希索引实现的不便之处在于,带有索引的操作未记录在预写日志中(PostgreSQL在创建索引时会发出警告)。因此,哈希索引在失败后将无法恢复,并且不参与复制。此外,哈希索引的通用性远低于“ B-tree”,其效率也值得怀疑。因此,现在使用这样的索引是不切实际的。
但是,在PostgreSQL的10版本发布后,这种情况最早将在今年秋天(2017年)改变。在此版本中,哈希索引最终获得了对预写日志的支持;此外,还优化了内存分配,并发工作更加高效。
哈希语义
但是,为什么无法使用的哈希索引几乎从PostgreSQL诞生之日起到9.6就一直存在?问题是DBMS广泛使用了哈希算法(特别是用于哈希连接和分组),并且系统必须知道将哪种哈希函数应用于哪种数据类型。但是这种对应关系不是一成不变的,并且不能一劳永逸地设置,因为PostgreSQL允许动态添加新的数据类型。这是一种通过哈希的访问方法,其中存储了此对应关系,表示为辅助函数与运算符族的关联。
demo=# select opf.opfname as opfamily_name,amproc.amproc::regproc AS opfamily_procedurefrom pg_am am,pg_opfamily opf,pg_amproc amprocwhere opf.opfmethod = am.oidand amproc.amprocfamily = opf.oidand am.amname = 'hash'order by opfamily_name,opfamily_procedure;opfamily_name | opfamily_procedure--------------------+--------------------abstime_ops | hashint4aclitem_ops | hash_aclitemarray_ops | hash_arraybool_ops | hashchar...
尽管这些函数没有文档说明,但可以使用它们计算适当数据类型值的哈希码。例如,如果对«text_ops»运算符族使用«hashtext»函数:
demo=# select hashtext('one');hashtext-----------127722028(1 row)demo=# select hashtext('two');hashtext-----------345620034(1 row)
属性
让我们看一下哈希索引的属性,其中此访问方法向系统提供有关自身的信息。上节我们提供了查询。现在,我们也不会超出上次的结果:
name | pg_indexam_has_property---------------+-------------------------can_order | fcan_unique | fcan_multi_col | fcan_exclude | tname | pg_index_has_property---------------+-----------------------clusterable | findex_scan | tbitmap_scan | tbackward_scan | tname | pg_index_column_has_property--------------------+------------------------------asc | fdesc | fnulls_first | fnulls_last | forderable | fdistance_orderable | freturnable | fsearch_array | fsearch_nulls | f
哈希函数不保留顺序关系:如果一个键的哈希函数的值小于另一键的哈希函数的值,则无法对键本身如何排序做出结论。因此,通常哈希索引可以支持唯一的操作“=”:
demo=# select opf.opfname AS opfamily_name,amop.amopopr::regoperator AS opfamily_operatorfrom pg_am am,pg_opfamily opf,pg_amop amopwhere opf.opfmethod = am.oidand amop.amopfamily = opf.oidand am.amname = 'hash'order by opfamily_name,opfamily_operator;opfamily_name | opfamily_operator---------------+----------------------abstime_ops | =(abstime,abstime)aclitem_ops | =(aclitem,aclitem)array_ops | =(anyarray,anyarray)bool_ops | =(boolean,boolean)...
因此,哈希索引不能返回有序数据(«can_order»,«orderable»)。
出于同样的原因,哈希索引不能处理NULL:«equals»操作对NULL(«search_nulls»)没有意义。
由于哈希索引不存储键(仅存储其哈希码),因此它不能用于仅索引访问(«returnable»)。此访问方法也不支持多列索引(«can_multi_col»)。
内部
从版本10开始,可以通过“ pageinspect ”扩展名查看哈希索引内部。这就是它的样子:
demo=# create extension pageinspect;
元页面(我们获取索引中的行数和已用的最大存储桶数):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));hash_page_type----------------metapage(1 row)demo=# select ntuples, maxbucketfrom hash_metapage_info(get_raw_page('flights_flight_no_idx',0));ntuples | maxbucket---------+-----------33121 | 127(1 row)
存储桶页面(我们获得活动元组和死元组的数量,即可以清除的元组的数量):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));hash_page_type----------------bucket(1 row)demo=# select live_items, dead_itemsfrom hash_page_stats(get_raw_page('flights_flight_no_idx',1));live_items | dead_items------------+------------407 | 0(1 row)
但是,在不检查源代码的情况下几乎不可能找出所有可用字段的含义。如果你想这样做,则应从README(链接点击文末“阅读原文”)开始。
下期预告
本系列下篇文章将会讨论最常用的B-Tree索引,这是最传统且使用最广泛的索引。

