




Java 是当前非常流行的开发语言,很多 TiDB 用户的业务层都是使用 Java 开发的,本文将从 Java 数据库交互组件开发的角度出发,介绍各组件的推荐配置和推荐使用方式,希望能帮助 Java 开发者在使用 TiDB 时能更好的发挥数据库性能。
Java 应用中的数据库相关组件
网络协议:客户端通过标准 MySQL 协议 和 TiDB 进行网络交互。 JDBC API 及实现:Java 应用通常使用 JDBC (Java Database Connectivity) 来访问数据库。JDBC 定义了访问数据库 API,而 JDBC 实现完成标准 API 到 MySQL 协议的转换,常见的 JDBC 实现是 MySQL Connector/J,此外有些用户可能使用 MariaDB Connector/J。 数据库连接池:为了避免每次创建连接,通常应用会选择使用数据库连接池来复用连接,JDBC DataSource 定义了连接池 API,开发者可根据实际需求选择使用某种开源连接池实现。 数据访问框架:应用通常选择通过数据访问框架(MyBatis、Hibernate)的封装来进一步简化和管理数据库访问操作。 业务实现:业务逻辑控制着何时发送和发送什么指令到数据库,其中有些业务会使用 Spring Transaction 切面来控制管理事务的开始和提交逻辑。
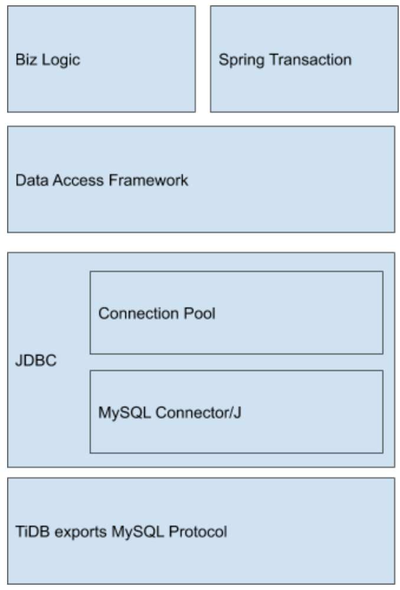
JDBC
1. JDBC API
?在客户端替换后以文本形式发送到客户端,所以除了要使用 Prepare API,还需要在 JDBC 连接参数中配置 useServerPrepStmts = true,才能在 TiDB 服务器端进行语句预处理(下面参数配置章节有详细介绍)。
注意: 对于 MySQL Connector/J 实现,默认 Batch 只是将多次 addBatch
的 SQL 发送时机延迟到调用executeBatch
的时候,但实际网络发送还是会一条条的发送,通常不会降低与数据库服务器的网络交互次数。如果希望 Batch 网络发送批量插入,需要在 JDBC 连接参数中配置 rewriteBatchedStatements=true
(下面参数配置章节有详细介绍)。
设置 FetchSize
为Integer.MIN_VALUE
让客户端不缓存,客户端通过StreamingResult
的方式从网络连接上流式读取执行结果。使用 Cursor Fetch 首先需 设置 FetchSize
为正整数且在 JDBC URL 中配置useCursorFetch=true
。
FetchSize设置为
Integer.MIN_VALUE的方式,比第二种功能实现更简单且执行效率更高。
2. MySQL JDBC 参数
useServerPrepStmts
useServerPrepStmts为 false,即尽管使用了 Prepare API,也只会在客户端做 “prepare”。因此为了避免服务器重复解析的开销,如果同一条 SQL 语句需要多次使用 Prepare API,则建议设置该选项为 true。
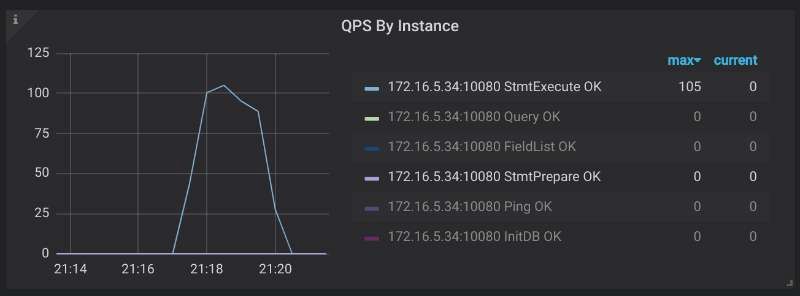
Query Summary > QPS By Instance查看请求命令类型,如果请求中
COM_QUERY被
COM_STMT_EXECUTE或
COM_STMT_PREPARE代替即生效。
cachePrepStmts
useServerPrepStmts=true能让服务端执行 prepare 语句,但默认情况下客户端每次执行完后会 close prepared 的语句,并不会复用,这样 prepare 效率甚至不如文本执行。所以建议开启
useServerPrepStmts=true后同时配置
cachePrepStmts=true,这会让客户端缓存 prepare 语句。
Query Summary > QPS By Instance查看请求命令类型,如果类似下图,请求中
COM_STMT_EXECUTE数目远远多于
COM_STMT_PREPARE即生效。
useConfigs=maxPerformance配置会同时配置多个参数,其中也包括
cachePrepStmts=true。
prepStmtCacheSqlLimit
cachePrepStmts后还需要注意
prepStmtCacheSqlLimit配置(默认为 256),该配置控制客户端缓存 prepare 语句的最大长度,超过该长度将不会被缓存。
Query Summary > QPS by Instance查看请求命令类型,如果已经配置了
cachePrepStmts=true,但
COM_STMT_PREPARE还是和
COM_STMT_EXECUTE基本相等且有
COM_STMT_CLOSE,需要检查这个配置项是否设置得太小。
prepStmtCacheSize
prepStmtCacheSize控制缓存的 prepare 语句数目(默认为 25),如果应用需要 prepare 的 SQL 种类很多且希望复用 prepare 语句,可以调大该值。
Query Summary > QPS by Instance查看请求中
COM_STMT_EXECUTE数目是否远远多于
COM_STMT_PREPARE来确认是否正常。
rewriteBatchedStatements=true,在已经使用
addBatch或
executeBatch后默认 JDBC 还是会一条条 SQL 发送,例如:
pstmt = prepare(“insert into t (a) values(?)”);
pstmt.setInt(1, 10);
pstmt.addBatch();
pstmt.setInt(1, 11);
pstmt.addBatch();
pstmt.setInt(1, 12);
pstmt.executeBatch();
insert into t(a) values(10);
insert into t(a) values(11);
insert into t(a) values(12);
rewriteBatchedStatements=true,发送到 TiDB 的 SQL 将是:
insert into t(a) values(10),(11),(12);
insert into t (a) values (10) on duplicate key update a = 10;
insert into t (a) values (11) on duplicate key update a = 11;
insert into t (a) values (12) on duplicate key update a = 12;
insert into t (a) values (10) on duplicate key update a = values(a);
insert into t (a) values (11) on duplicate key update a = values(a);
insert into t (a) values (12) on duplicate key update a = values(a);
insert into t (a) values (10), (11), (12) on duplicate key update a = values(a);
update t set a = 10 where id = 1; update t set a = 11 where id = 2; update t set a = 12 where id = 3;
rewriteBatchedStatements=true。
elect @@session.transaction_read_only)。这些 SQL 对 TiDB 无用,推荐配置
useConfigs=maxPerformance来避免额外开销。
useConfigs=maxPerformance会包含一组配置:
cacheServerConfiguration=true
useLocalSessionState=true
elideSetAutoCommits=true
alwaysSendSetIsolation=false
enableQueryTimeouts=false
连接池
1. 连接数配置
maximumPoolSize
:连接池最大连接数,配置过大会导致 TiDB 消耗资源维护无用连接,配置过小则会导致应用获取连接变慢,所以需根据应用自身特点配置合适的值,可参考 这篇文章。minimumIdle
:连接池最大空闲连接数,主要用于在应用空闲时存留一些连接以应对突发请求,同样是需要根据业务情况进行配置。
metricRegistry),通过监控能及时定位连接池问题。
2. 探活配置
The last packet sent successfully to the server was 3600000 milliseconds ago. The driver has not received any packets from the server. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
n milliseconds ago中的
n是
0或很小的值,则通常是执行的 SQL 导致 TiDB 异常退出引起的报错,推荐查看 TiDB stderr 日志;如果
n是一个非常大的值(比如这里的 3600000),很可能是因为这个连接空闲太久然后被中间 proxy 关闭了,通常解决方式除了调大 proxy 的 idle 配置,还可以让连接池:
每次使用连接前检查连接是否可用。 使用单独线程定期检查连接是否可用。 定期发送 test query 保活连接。
数据访问框架
1. MyBatis
select 1 from t where id = #{param1}
会作为 prepare 语句转换为select 1 from t where id = ?
进行 prepare, 并使用实际参数来复用执行,通过配合前面的 Prepare 连接参数能获得最佳性能。select 1 from t where id = ${param2}
会做文本替换为select 1 from t where id = 1
执行,如果这条语句被 prepare 成了不同参数,可能会导致 TiDB 缓存大量的 prepare 语句,并且这种方式执行 SQL 有注入安全风险。
insert ... values(...), (...), ...的形式,除了前面所说的在 JDBC 配置
rewriteBatchedStatements=true外,MyBatis 还可以使用动态 SQL 的 foreach 语法 来半自动生成 batch insert。比如下面的 mapper:
<insert id="insertTestBatch" parameterType="java.util.List" fetchSize="1">
insert into test
(id, v1, v2)
values
<foreach item="item" index="index" collection="list" separator=",">
(
#{item.id}, #{item.v1}, #{item.v2}
)
</foreach>
on duplicate key update v2 = v1 + values(v1)
</insert>
insert on duplicate key update语句,values 后面的
(?, ?, ?)数目是根据传入的 list 个数决定,最终效果和使用
rewriteBatchStatements=true类似,可以有效减少客户端和 TiDB 的网络交互次数,同样需要注意 prepare 后超过
prepStmtCacheSqlLimit限制导致不缓存 prepare 语句的问题。
1.3 Streaming 结果
可以通过在 mapper 配置中对单独一条 SQL 设置 fetchSize
(见上一段代码段),效果等同于调用 JDBC setFetchSize。可以使用带 ResultHandler 的查询接口来避免一次获取整个结果集。 可以使用 Cursor 类来进行流式读取。
<select>部分配置
fetchSize="-2147483648"(
Integer.MIN_VALUE) 来流式读取结果。
<select id="getAll" resultMap="postResultMap" fetchSize="-2147483648">
select * from post;
</select>
@Options(fetchSize = Integer.MIN_VALUE)并返回 Cursor 从而让 SQL 结果能被流式读取。
@Select("select * from post")
@Options(fetchSize = Integer.MIN_VALUE)
Cursor<Post> queryAllPost();
2. ExecutorType
openSession的时候可以选择
ExecutorType,MyBatis 支持三种 executor:
Simple
:每次执行都会向 JDBC 进行 prepare 语句的调用(如果 JDBC 配置有开启cachePrepStmts
,重复的 prepare 语句会复用)。
Reuse
:在 executor 中缓存 prepare 语句,这样不用 JDBC 的cachePrepStmts
也能减少重复 prepare 语句的调用。Batch
:每次更新只有在addBatch
到 query 或 commit 时才会调用executeBatch
执行,如果 JDBC 层开启了rewriteBatchStatements
,则会尝试改写,没有开启则会一条条发送。
Simple,需要在调用
openSession时改变
ExecutorType。如果是 Batch 执行,会遇到事务中前面的 update 或 insert 都非常快,而在读数据或 commit 事务时比较慢的情况,这实际上是正常的,在排查慢 SQL 时需要注意。
Spring Transaction
@Transactional注解标记方法,AOP 将会在方法前开启事务,方法返回结果前 commit 事务。如果遇到类似业务,可以通过查找代码
@Transactional来确定事务的开启和关闭时机。需要特别注意有内嵌的情况,如果发生内嵌,Spring 会根据 Propagation 配置使用不同的行为,因为 TiDB 未支持 savepoint,所以不支持嵌套事务。
排查工具
1. jstack
pprof/goroutine,可以比较方便地排查进程卡死的问题。
-m选项。
Mybatis BatchExecutor flush调用 update)或死锁问题(比如:测试程序都在抢占应用中某把锁导致没发送 SQL)
top -p $PID -H或者 Java swiss knife 都是常用的查看线程 ID 的方法。通过
printf "%x\n" pid把线程 ID 转换成 16 进制,然后去 jstack 输出结果中找对应线程的栈信息,可以定位“某个线程占用 CPU 比较高,不知道它在执行什么”的问题。
2. jmap & mat
pprof/heap不同,jmap 会将整个进程的内存快照 dump 下来(go 是分配器的采样),然后可以通过另一个工具 mat 做分析。
3. trace
4. 火焰图
总结
《TiDB 最佳实践系列文章》是面向广大 TiDB 用户的系列教程,旨在深入浅出介绍 TiDB 的架构与原理,帮助用户在生产环境中最大限度发挥 TiDB 的优势。我们将分享一系列典型场景下的最佳实践路径,便于大家快速上手,迅速定位并解决问题。
往期回顾:

最后修改时间:2019-11-07 09:19:40
文章转载自PingCAP,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
