




虽然 NoSQL 运动是革命性的技术创新,但现在对传统 SQL 和 RDBMS 的需求在复苏,两者结合的新产品可以最好地满足需求。这催生了新型的强大数据库引擎 EsygnDB,它整合了 Apache HBase 原生的 NoSQL 能力、Apache ORC 和其他 Apache Hive 文件格式。
借助于 NoSQL 的实践经验,EsgynDB 的发展方向是与多种存储引擎集成,为用户提供多种数据结构/模型选项,从而支持各类工作负载和用例。EsgynDB 在 HBase 之上支持结构化的关系型抽象、Google Big Table 模型(使用原生 HBase)和采用 key-value 或列式存储(使用 ORC)的 Hive 表。
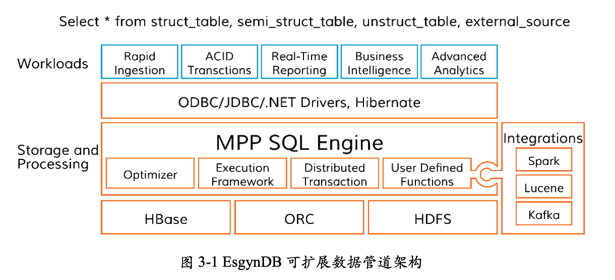
为了支持多数据模型和满足不同用例的需求,EsgynDB 继续与存储引擎进行集成。 这些多模型支持覆盖内存、文本搜索、JSON/文件支持和图形数据库能力领域。某 些集成工作早已开始,例如,与基于 Apache Geode 的 Ampool 集成、与 Apache Spark 集成(内存)、与 Apache Lucene 集成(文本搜索)、与 JSON 文档管理集成 和与 JanusGraph(旧称 Titan,解决图遍历问题)集成。
多模型支持拥有可扩展数据管道架构,在生态系统中,它能轻松地与其他技术进行 集成。Table UDF 基础架构允许与 Kafka 集成(流式)、与机器学习算法集成 (Continuum 的 Anaconda)、与 JDBC 数据源集成(导入存储在其他数据库的数 据)、与 Spark 集成(内存分析)和与 Lucene 集成(外部网站搜索)。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
