




根据图数据库底层存储模式对图数据库产品进行分类,可以分为原生(Native)图存储和非原生(Non-Native)图存储两种。
其中原生图存储数据存储模式专门为存储和处理图而设计优化,可支持各类图算法的快速遍历;非原生图存储则采用关系数据库、面向对象数据库或其它通用数据存储策略存储数据,未专门优化存储方式。
Neo4j 是 Native 的图数据库,所谓 Native 图数据库,中文一般翻译为 “原生图数据库”,指从一开始便是为了解决图类数据结构而设计的数据库。对了解数据结构的同学来看,这里的 “原生” 的体现,其实主要就在两个方面:
- 图数据结构的存储
- 图数据的处理和查询
- 图数据结构的存储
不管是什么数据库,mysql,sql server,mongo,neo4j 等等,其存储的数据,最终都要落地到文件系统上的,那 neo4j 落地的文件大概都是什么样的呢?这里我以本地的一个应用的数据库来介绍一下。
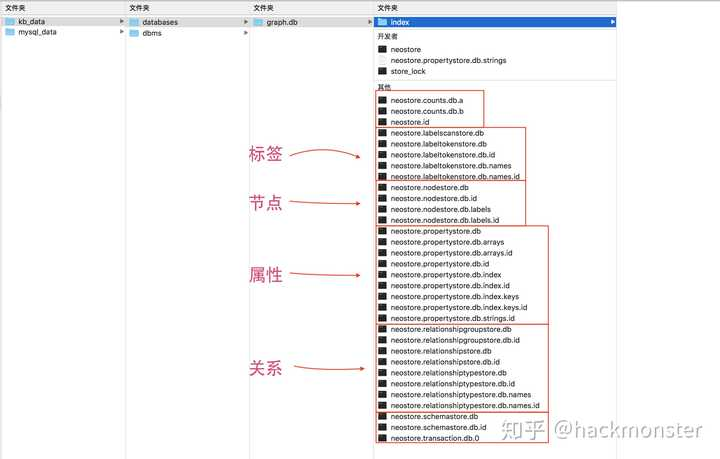
上面是我的本地一个图数据库的数据库文件,可以看出 Neo4j 把其数据库文件分为四大类来分类存储:
标签
节点
属性
关系
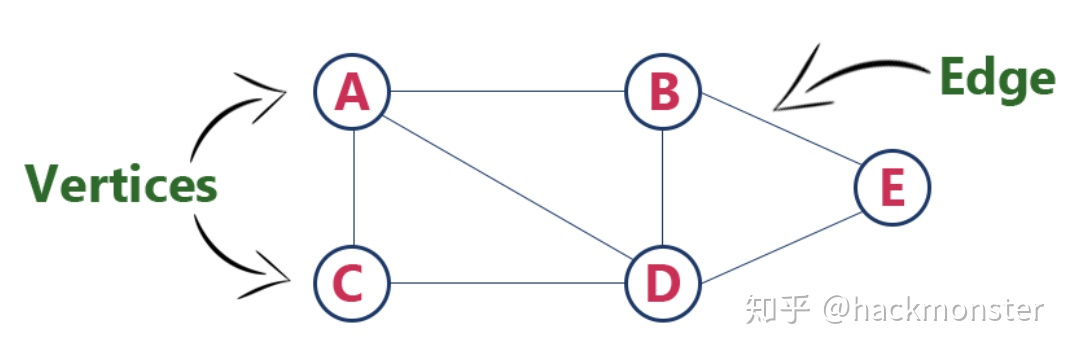
其实按照我们图论中的一般说法,其实对于一个图数据结构来说,只需要存储节点和关系就可以了,如下面这个图数据一样:
这里是我们应用中一个实际案例,大家看看我们对标签和属性的划分:
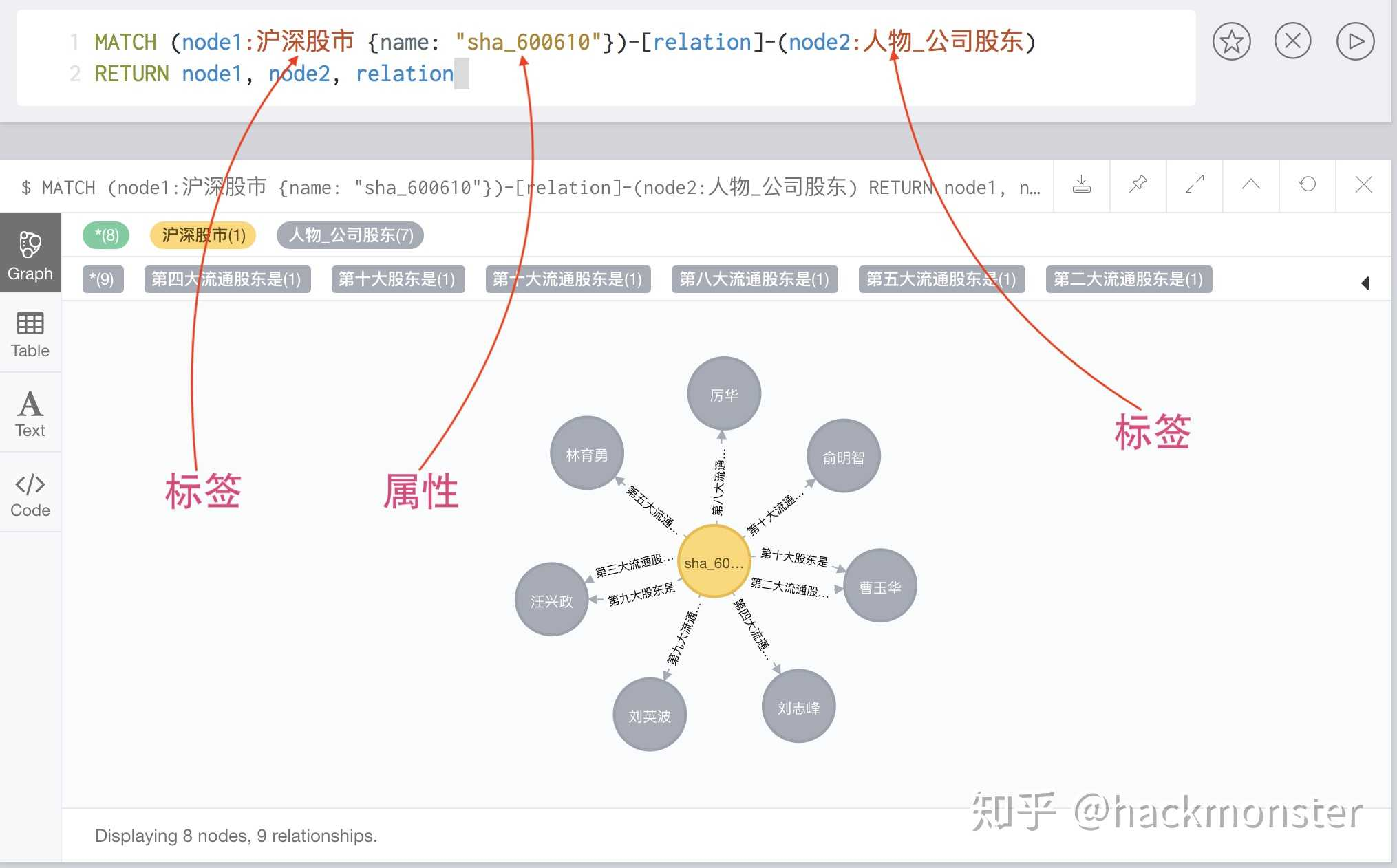
– 这里咱们先看看这个语句表达的什么意思,这是 Neo4j 专用的查询语言 Cypher
– 下面这个查询语句含义如下:
– step 1: 首先查询一个具有标签为 “沪深股市”,且有一个属性对 “{name: “sha_600610”}” 的节点,
– step 2: 然后查找这个节点的所有双向关系
– step 3: 在这些关系的中,要求另外一个节点具有 “人物_公司股东” 这个标签
– step 4: 返回这个节点,以及满足要求的关系和相关节点
MATCH (node1:沪深股市 {name: “sha_600610”})-[relation]-(node2:人物_公司股东)
RETURN node1, node2, relation
