




这是学习笔记的第 2153 篇文章

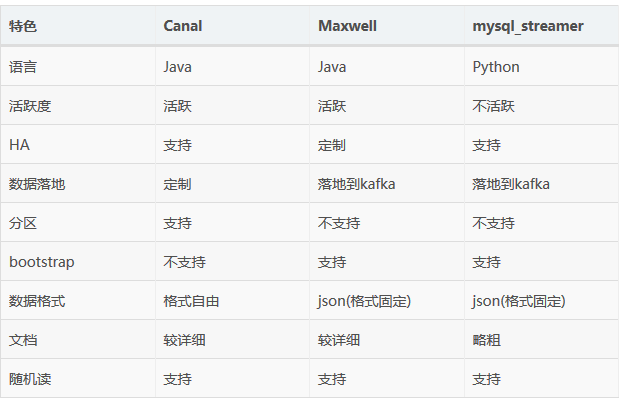
在Binlog解析方向和数据流转方向上,经常会提到比较有名的几类工具,阿里的Canal,Zendesk的Maxwell和Yelp的mysql_streamer,他们整体的情况如下:
主要设计思想是伪装MySQL Slave,通过与MySQL服务端协议通信,建立复制线程,从而获得主库推送的实时数据变化。
在功能完善性和生态建设上,Canal和Zendesk整体的表现要好一些,它们都是基于Java开发,支持多种模式的数据上下游集成,如果是想快速上手,Maxwell是一个不错的选择,而mysql_streamer的维护时间在2017年左右,在行业里看到的案例相对要少。
Maxwell相对比较精巧,它能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,这一点是我优先考虑Maxwell的首要原因,当然它也可以作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。如果说使用场景,它的常见应用场景有ETL、维护缓存、收集表级别的DML指标、增量到搜索引擎、数据分区迁移等。
bin/maxwell --user='maxwell' --password='XXXXXX' --port=33071 --host=127.0.0.1 --gtid_mode=true --output_server_id=true --output_thread_id=true --output_schema_id=true --output_primary_keys=true --output_primary_key_columns=true --output_binlog_position=true --output_gtid_position=true --output_null_zerodates=true --output_ddl=true --producer=stdout
开启了全量的指标,通过全量的指标来权衡各种语句中必须的选项和解析逻辑.
我们先按照两个大的维度来梳理和总结。
DML语句梳理
事务语句梳理
.DML语句调研梳理
主要覆盖Insert,Update,Delete,对返回的JSON数据进行梳理分析。
1) Insert语句
JSON返回数据
{
"database": "test",
"table": "test_data",
"type": "insert",
"ts": 1573024626,
"xid": 49482,
"commit": true,
"position": "binlog.000009:2466059",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:10310",
"server_id": 33091,
"thread_id": 147,
"schema_id": 5,
"primary_key": [3],
"primary_key_columns": ["id"],
"data": {
"id": 3,
"name": "cc"
}
}
语句解析设计
可以直接解析data中的数据,拼装为insert语句
字段列表需要根据data中的第1行数据进行拼装
需要解析的属性:
{
"database": "test",
"table": "test_data",
"type": "insert",
"ts": 1573024626,
"xid": 49482,
"commit": true,
"position": "binlog.000009:2466059",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:10310",
"server_id": 33091,
"data": {
"id": 3,
"name": "cc"
}
}
幂等伪SQL
Insert into [table]([id],[name]) values(?,?);
2) delete语句
JSON返回数据
{
"database": "test",
"table": "test_data",
"type": "delete",
"ts": 1573014236,
"xid": 39918,
"commit": true,
"position": "binlog.000009:1948897",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:8856",
"server_id": 33091,
"thread_id": 122,
"schema_id": 5,
"primary_key": [3],
"primary_key_columns": ["id"],
"data": {
"id": 3,
"name": "fff"
}
}
语句解析设计
{
"database": "test",
"table": "test_data",
"type": "delete",
"ts": 1573014236,
"xid": 39918,
"commit": true,
"position": "binlog.000009:1948897",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:8856",
"primary_key": [3],
"primary_key_columns": ["id"],
"data": {
"id": 3,
"name": "fff"
}
}
如果删除多行,假设SQL语句如下,删除两行数据:
delete from test_data where id>2;
Query OK, 2 rows affected (0.06 sec)
返回的JSON为:
{
"database": "test",
"table": "test_data",
"type": "delete",
"ts": 1573028638,
"xid": 54808,
"xoffset": 0,
"position": "binlog.000009:2754895",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:11120",
"primary_key": [3],
"primary_key_columns": ["id"],
}
{
"database": "test",
"table": "test_data",
"type": "delete",
"ts": 1573028638,
"xid": 54808,
"commit": true,
"position": "binlog.000009:2754895",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:11120",
"primary_key": [4],
"primary_key_columns": ["id"],
}
通过以上的分析和测试,可以看出delete操作可以关注于primary_key和primary_key_columns,得到相关的SQL语句,实现逻辑幂等性,
幂等伪SQL
Delete from [table] where [id]=?
3) update语句
JSON返回数据
{
"database": "test",
"table": "test_data",
"type": "update",
"ts": 1573024676,
"xid": 49552,
"commit": true,
"position": "binlog.000009:2470294",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:10322",
"server_id": 33091,
"thread_id": 147,
"schema_id": 5,
"primary_key": [3],
"primary_key_columns": ["id"],
"data": {
"id": 3,
"name": "ccc"
},
"old": {
"name": "cc"
}
}
语句解析设计
{
"database": "test",
"table": "test_data",
"type": "update",
"ts": 1573024676,
"xid": 49552,
"commit": true,
"position": "binlog.000009:2470294",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:10322",
"primary_key": [3],
"primary_key_columns": ["id"],
"data": {
"id": 3, --去除主键列
"name": "ccc"
},
"old": {
"name": "cc"
}
}
需要尽可能得到完整的Update语句。
幂等伪SQL
Update [table] set [name]=? Where [id]=? and [name]=?
4) 复杂SQL语句
表关联修改场景1:
mysql> update test_data set name='bb' where id in (select id from test_data2);
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
会转换为幂等的update语句。
{"database":"test","table":"test_data","type":"update","ts":1573096677,"xid":64394,"commit":true,"position":"binlog.000009:3276416","gtid":"f73d7025-f25b-11e9-9824-52540058c70f:12583","server_id":33091,"thread_id":170,"schema_id":6,"primary_key":[1],"primary_key_columns":["id"],"data":{"id":1,"name":"bb"},"old":{"name":"aa"}}
表关联修改场景2:
mysql> update test_data,test_data2 set test_data.name='cc' where test_data.id=test_data2.id and test_data2.name='aa';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
{"database":"test","table":"test_data","type":"update","ts":1573097195,"xid":65078,"commit":true,"position":"binlog.000009:3314180","gtid":"f73d7025-f25b-11e9-9824-52540058c70f:12689","server_id":33091,"thread_id":170,"schema_id":6,"primary_key":[1],"primary_key_columns":["id"],"data":{"id":1,"name":"cc"},"old":{"name":"bb"}}
5) DML语句幂等小结
整体是基于行模式的解析,可以逻辑幂等的设计原则来进行完善。
语句类型 | 幂等SQL |
insert | Insert into [table]([id],[name]) values(?,?); |
delete | Delete from [table] where [id]=? |
update | Update [table] set [name]=? Where [id]=? and [name]=? |
通过以上的小结,其实我们可以明确对于分布式ID的强烈需求,这会是我们构筑业务多活的基础实现。
二。事务调研和梳理
1) SQL操作分析
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_data set name='cc' where id=3;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> insert into test_data values(4,'dd');
Query OK, 1 row affected (0.00 sec)
mysql> delete from test_data where id=2 and name='bb';
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
2) JSON返回数据
{
"database": "test",
"table": "test_data",
"type": "update",
"ts": 1573024725,
"xid": 49621,
"xoffset": 0,
"position": "binlog.000009:2476678",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:10340",
"server_id": 33091,
"thread_id": 147,
"schema_id": 5,
"primary_key": [3],
"primary_key_columns": ["id"],
"data": {
"id": 3,
"name": "cc"
},
"old": {
"name": "ccc"
}
}
{
"database": "test",
"table": "test_data",
"type": "insert",
"ts": 1573024735,
"xid": 49621,
"xoffset": 1,
"position": "binlog.000009:2476778",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:10340",
"server_id": 33091,
"thread_id": 147,
"schema_id": 5,
"primary_key": [4],
"primary_key_columns": ["id"],
"data": {
"id": 4,
"name": "dd"
}
}
{
"database": "test",
"table": "test_data",
"type": "delete",
"ts": 1573024754,
"xid": 49621,
"commit": true,
"position": "binlog.000009:2476868",
"gtid": "f73d7025-f25b-11e9-9824-52540058c70f:10340",
"server_id": 33091,
"thread_id": 147,
"schema_id": 5,
"primary_key": [2],
"primary_key_columns": ["id"],
"data": {
"id": 2,
"name": "bb"
}
}
3) 语句逻辑解析设计
按照xoffset来递增,下标为0,最后一个事务没有xoffset,commit为true
对于insert,delete,update的解析逻辑可以复用DML处理的部分
SQL语句/命令 | type | xid | timestamp | xid | xoffset | commit |
begin; | ||||||
update test_data set name='cc' where id=3; | update | 49621 | 1573024725 | 147 | 0 | |
insert into test_data values(4,'dd'); | insert | 49621 | 1573024735 | 147 | 1 | |
delete from test_data where id=2 and name='bb'; | delete | 49621 | 1573024754 | 147 | true | |
commit; |
4) 大事务binlog
如果瞬间产生了大量的binlog,为了控制内存使用,会将处理延迟的binlog下沉到文件系统。
xxxxx INFO BinlogConnectorLifecycleListener - Binlog connected.
xxxxx INFO ListWithDiskBuffer - Overflowed in-memory buffer, spilling over into /tmp/maxwell7935334910787514257events
后续补充Maxwell解析DDL和设计中的一些潜在问题和补救措施。
近期热文:
数据库修改密码风险高,如何保证业务持续,这几种密码双活方案可以参考
MySQL中的主键和rowid,看似简单,其实有一些使用陷阱需要注意
转载热文:
QQ群号:763628645
QQ群二维码如下, 添加请注明:姓名+地区+职位,否则不予通过


