1 前言
摸底数据源、数据质量
撰写指标、标签口径文档
讨论、撰写数据集成方案
与开发沟通确认开发逻辑
指标、标签的验收测试
撰写数据更新、脏数据处理方案等
初识Hive:简单了解Hadoop、Hive的原理、特点、应用。(实际工作中产品经理一般不会直接参与Hive的安装配置、数据装载等,但有关大数据存储、计算话题讨论,需要基于对Hadoop、Hive的基础认知)
Hive SQL:系统总结有关Hive SQL的DQL语法、函数、应用案例。(DQL语法和函数是SQL查询中高频应用的内容,同时也会结合数据化运营场景中的指标、标签的案例进行练习)
Hive SQL优化:简单了解有关Hive SQL查询优化的内容。(当数据量大的时候,查询性能问题是必须考虑的内容)
2 初识Apache Hive
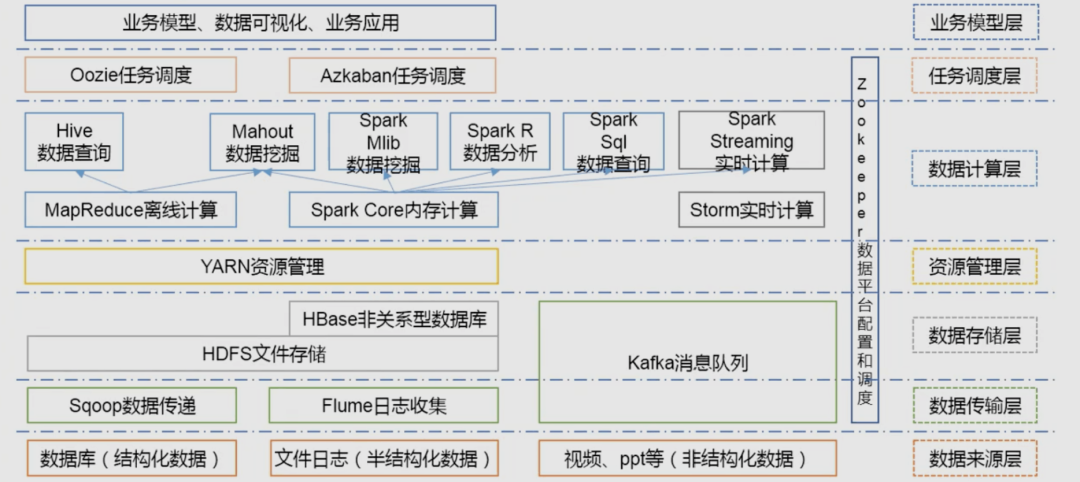
2.1 初识Hadoop
2.1.1 Hadoop的核心架构

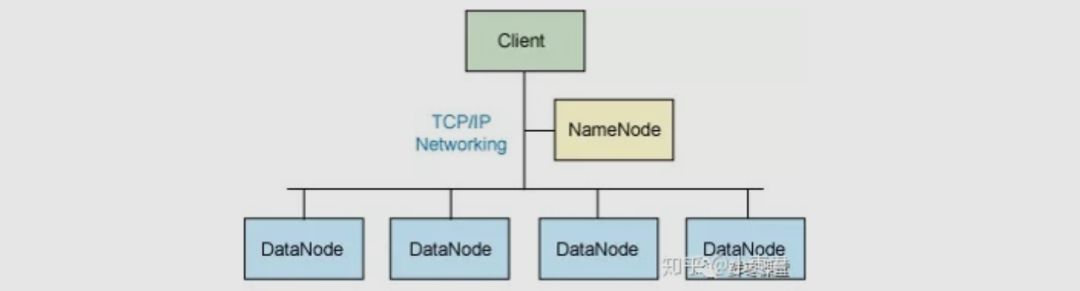
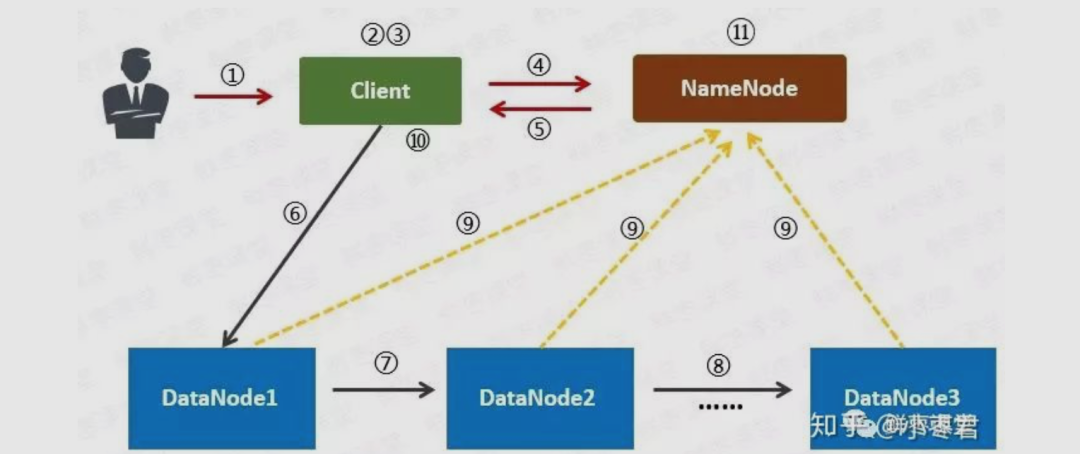
用户向Client(客户机)提出请求。例如,需要写入200MB的数据。
Client制定计划:将数据按照64MB为块,进行切割;所有的块都保存三份。
Client将大文件切分成块(block)。
针对第一个块,Client告诉NameNode(主控节点),请帮助我,将64MB的块复制三份。
NameNode告诉Client三个DataNode(数据节点)的地址,并且将它们根据到Client的距离,进行了排序。
Client把数据和清单发给第一个DataNode。
第一个DataNode将数据复制给第二个DataNode。
第二个DataNode将数据复制给第三个DataNode。
如果某一个块的所有数据都已写入,就会向NameNode反馈已完成。
对第二个Block,也进行相同的操作。
所有Block都完成后,关闭文件。NameNode会将数据持久化到磁盘上。
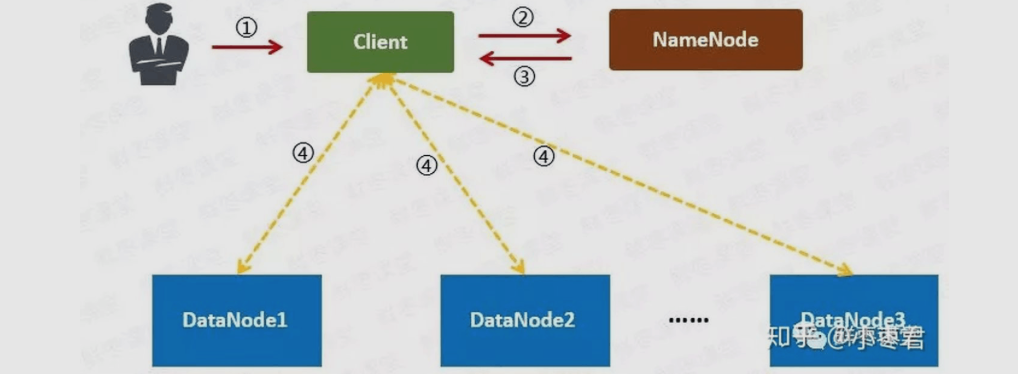
用户向Client提出读取请求。
Client向NameNode请求这个文件的所有信息。
NameNode将给Client这个文件的块列表,以及存储各个块的数据节点清单(按照和客户端的距离排序)。
Client从距离最近的数据节点下载所需的块。
2.1.2 Hadoop的生态圈
知乎搜索:深入浅出大数据:到底什么是Hadoop?
阿里云大数据学习路线→Hadoop快速入门→第一章:Hadoop介绍
2.2 初识Hive
2.2.1 Hive简介
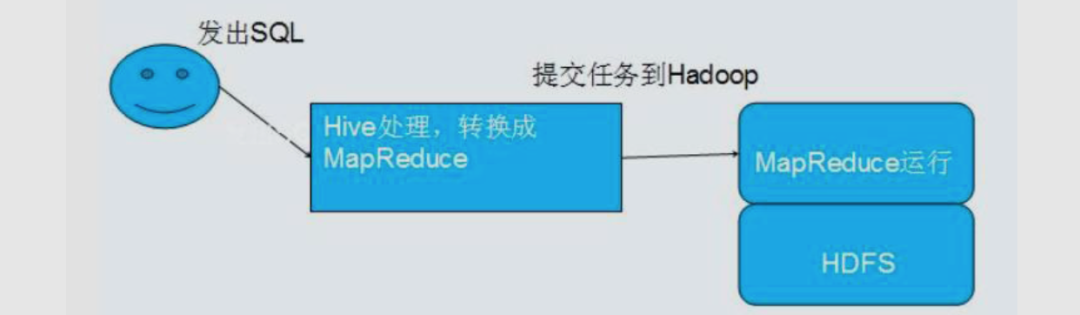
人员学习成本太高
MapReduce实现复杂查询逻辑开发难度太大
更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
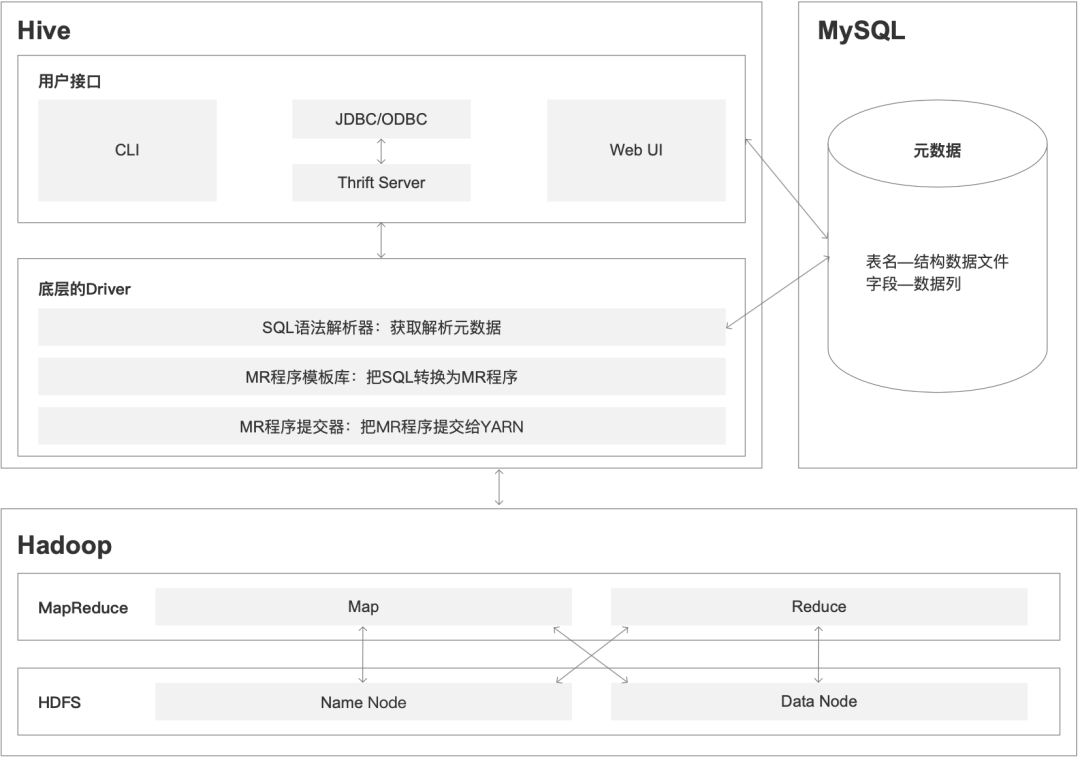
2.2.2 Hive的架构
2.2.3 Hive的数据存储结构

数据库 Databases
数据表 Tables
分区 Partitions
分桶 Buckets
2.2.4 Hive SQL
DDL(Data Defination Language):数据库定义语言
DML(Data manipulation language):数据操作语言
DQL(data query language):数据查询语言
2.2.5 其他
阿里云大数据学习路线→数据仓库系统Hive
《Hive实战》
百度搜索:Hive学习之路
3 Hive SQL
3.1 DQL语法
3.1.1 数据检索
3.1.2 检索数据处理
ASC-升序;
DESC-降序。
3.1.3 数据过滤
=、!=(<>)、<、<=、>、>=:用来做比较;
between…and:表示一个区间,两边都可以取到;
in、not in:in 表示在集合中;not in 表示不在集合中;
is (not) null:判断是否为空;
百分号(%)通配符:表示任意字符;
下划线(_)通配符:只匹配单个字符;
3.1.4 多表查询


union all:包含重复行;
union:取消重复行;


不重复存储信息,不浪费空间;
数据变动、处理数据更加简单;
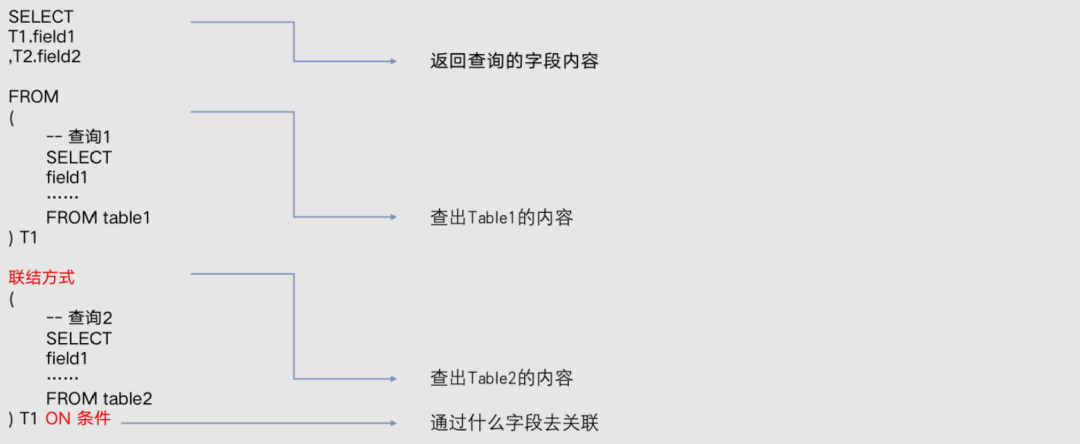
inner join 内联结:保留两边表都有的记录;
left join 左联结:保留左边表的信息,右边表没有匹配上的字段显示为null;
right join 右联结:保留右边表的信息,左边表没有匹配上的字段显示为null;
full join 全联结:左右两边表的信息都保留,没有匹配上的字段显示为null;
left semi join 左半联结:JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
过滤的关键词是 ON,不是 WHERE
ON 后面接的是等值筛选条件
3.1.5 执行顺序
--sql 1select a.* from table_a a left join table_b b on a.id = b.a_id where b.name = 'john';--sql 2select * from table_a where id = (select a_id from table_b where name = 'john');
(1) SELECT(2)DISTINCT<select_list>(3) FROM <left_table>(4) <join_type> JOIN <right_table>(5) ON <join_condition>(6) WHERE <where_condition>(7) GROUP BY <group_by_list>(8) WITH {CUBE|ROLLUP(9) HAVING <having_condition>(10) ORDER BY <order_by_condition>(11) LIMIT <limit_number>
(8) SELECT(9)DISTINCT<select_list>(1) FROM <left_table>(3) <join_type> JOIN <right_table>(2) ON <join_condition>(4) WHERE <where_condition>(5) GROUP BY <group_by_list>(6) WITH {CUBE|ROLLUP}(7) HAVING <having_condition>(10) ORDER BY <order_by_list>(11) LIMIT <limit_number>
(1) FROM:对FROM子句中的左表<left_table>和右表<right_table>执行笛卡儿积,产生虚拟表VT1;
(2) ON: 对虚拟表VT1进行ON筛选,只有那些符合<join_condition>的行才被插入虚拟表VT2;
(3)JOIN: 如果指定了OUTER JOIN(如LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2,产生虚拟表VT3。如果FROM子句包含两个以上的表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1~步骤3,直到处理完所有的表;
(4)WHERE: 对虚拟表VT3应用WHERE过滤条件,只有符合<where_condition>的记录才会被插入虚拟表VT4;
(5)GROUP By: 根据GROUP BY子句中的列,对VT4中的记录进行分组操作,产生VT5;如果应用了group by,那么后面的所有步骤都只能得到的vt5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行;
(6)CUBE|ROllUP: 对VT5进行CUBE或ROLLUP操作,产生表VT6;
(7)HAVING: 对虚拟表VT6应用HAVING过滤器,只有符合<having_condition>的记录才会被插入到VT7;
(8)SELECT: 第二次执行SELECT操作,选择指定的列,插入到虚拟表VT8中;
(9)DISTINCT: 去除重复,产生虚拟表VT9;
(10)ORDER BY: 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10;
(11)LIMIT: 取出指定街行的记录,产生虚拟表VT11,并返回给查询用户 。
3.2 Hive SQL函数
3.2.1 日期函数
from_unixtime(bigint unixtime[, string format])from_unixtime(1250111000,"yyyy-MM-dd") 得到2009-03-12format可为“yyyy-MM-dd hh:mm:ss”,“yyyy-MM-dd hh”,“yyyy-MM-dd hh:mm”等等
date_format(date/timestamp/string ts, string fmt)date_format("2016-06-22","MM-dd")=06-22
unix_timestamp(string date)unix_timestamp('2009-03-20 11:30:01') = 1237573801
to_date(string timestamp)to_date("1970-01-01 00:00:00") = "1970-01-01"
year(string date)year("1970-01-01") = 1970year("1970-01-01 00:00:00") = 1970
month(string date)month("1970-11-01") = 11month("1970-11-01 00:00:00") = 11
day(string date)day("1970-11-01") = 1day("1970-11-01 00:00:00") = 1hour(string date)minute(string date)econd(string date)
weekofyear(string date)weekofyear("1970-11-01 00:00:00") = 44weekofyear("1970-11-01") = 44
datediff(string enddate, string startdate)datediff('2009-03-01', '2009-02-27') = 2
date_add(string startdate, int days)date_add('2008-12-31', 1) = '2009-01-01'.
date_sub(string startdate, int days)date_sub('2008-12-31', 1) = '2008-12-30'--CURRENT_DATE() - INTERVAL '1' DAY
current_date()=2021-07-08
current_timestamp=2021-07-08 16:25:54.226
3.2.2 字符串函数
concat(string|binary A, string|binary B...)concat('foo', 'bar') 返回 'foobar'
SELECT CONCAT_WS(',','First name','Last Name' ) 返回 First name, Last Name
get_json_object(string json_string, string path)--对于jsonArray(json数组),如person表的xjson字段有数据:[{"name":"王二狗","sex":"男","age":"25"},{"name":"李狗嗨","sex":"男","age":"47"}]--取出第一个json对象,那么hive sql为:SELECT get_json_object(xjson,"$.[0]") FROM person;结果是:{"name":"王二狗","sex":"男","age":"25"}--取出第一个json的age字段的值:SELECT get_json_object(xjson,"$.[0].age") FROM person;结果:25
instr(string str, string substr)select instr("abcde",'b'),结果是2
length(string A)
substr(string|binary A, int start)substr('foobar', 4) 返回 'bar'
substr(string|binary A, int start, int len)substr('foobar', 4, 1) 返回 'b'
3.2.3 条件函数
if(boolean testCondition, T valueTrue, T valueFalseOrNull)select IF(1=1,'TRUE','FALSE') 返回 'True'select IF(1=1, 'working', 'not working') 返回'working'
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] ENDCASE 4 WHEN 5 THEN 5 WHEN 4 THEN 4 ELSE 3 END 将返回4
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] ENDCASE WHEN 5>0 THEN 5 WHEN 4>0 THEN 4 ELSE 0 END 将返回5CASE WHEN 5<0 THEN 5 WHEN 4<0 THEN 4 ELSE 0 END 将返回0
3.2.4 类型转换函数
cast(expr as <type>)cast("1" as BIGINT) 将字符串1转换成了BIGINT类型,如果转换失败将返回NULLevent_day <= CAST('2020-05-01' AS date)
3.2.5 聚合函数
count(*)
count(expr)
count(DISTINCT expr[, expr...])
sum(col)
sum(DISTINCT col)
avg(col)
avg(DISTINCT col)
min(col)
max(col)
3.2.6 窗口函数
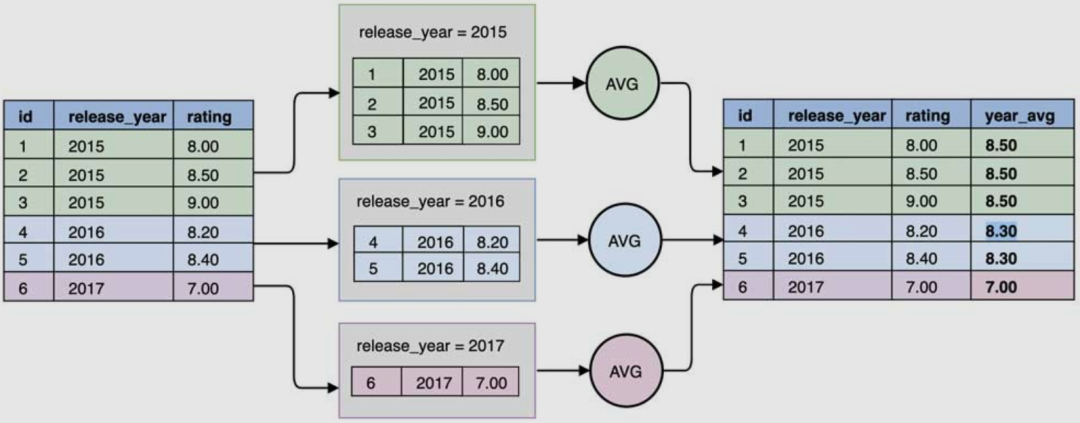
xxx() over(PARTITION by yyy ORDER by zzz)
xxx 为函数名
OVER() 括号中的内容这窗口内容
PARTITION by 后的为分组的字段,划分的范围被称为窗口
ORDER by 后决定着窗口范围内数据的排序方式
row_number():不间断,序号不重复,如 1、2、3、4、5
rank():间断,相同值同序号,如 1、1、3、4、5
dense_rank():不间断,相同值同序号,如 1、1、2、3、3
first_value(expr):求分组内第一个值
last_value(expr):求分组内最后一个值
sum(expr):求分组内从起点到当前行的累计值
avg(expr):求分组内从起点到当前行的平均值
min(expr):求分组内从起点到当前行的最小值
max(expr):求分组内从起点到当前行的最大值
lag(expr [, offset] [, default]): 向下位移,意思是滞后
lead(expr [, offset] [, default]): 向上位移,意思是超前
3.3 Hive SQL应用案例
3.3.1 用户过去7天订单实付金额总和
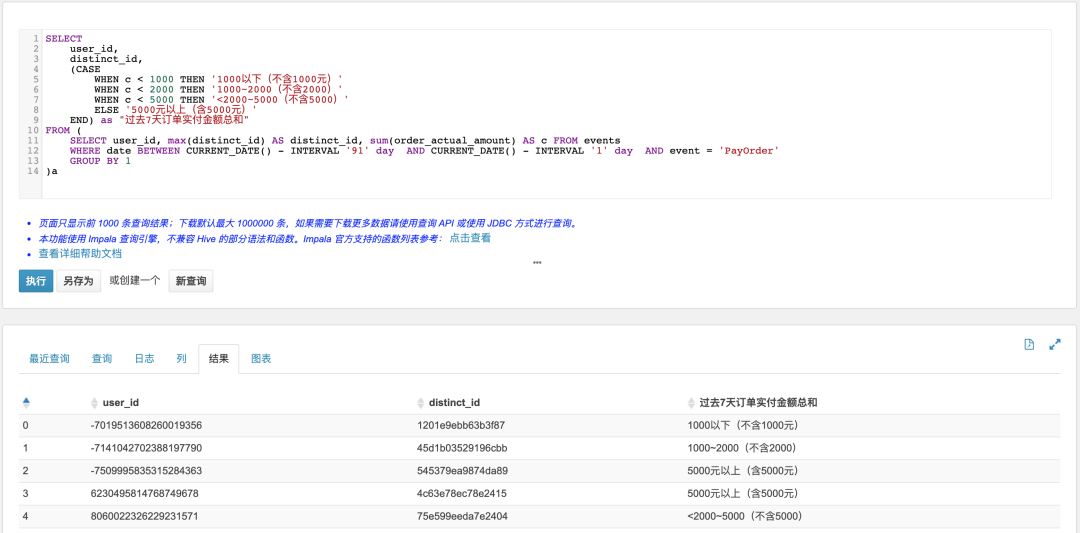
SELECTuser_id,distinct_id,(CASEWHEN c < 1000 THEN '1000以下(不含1000元)'WHEN c < 2000 THEN '1000~2000(不含2000)'WHEN c < 5000 THEN '<2000~5000(不含5000)'ELSE '5000元以上(含5000元)'END) as "过去7天订单实付金额总和"FROM (SELECT user_id, max(distinct_id) AS distinct_id, sum(order_actual_amount) AS c FROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '7' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'PayOrder'GROUP BY 1)a
3.3.2 用户首次支付订单的距今天数
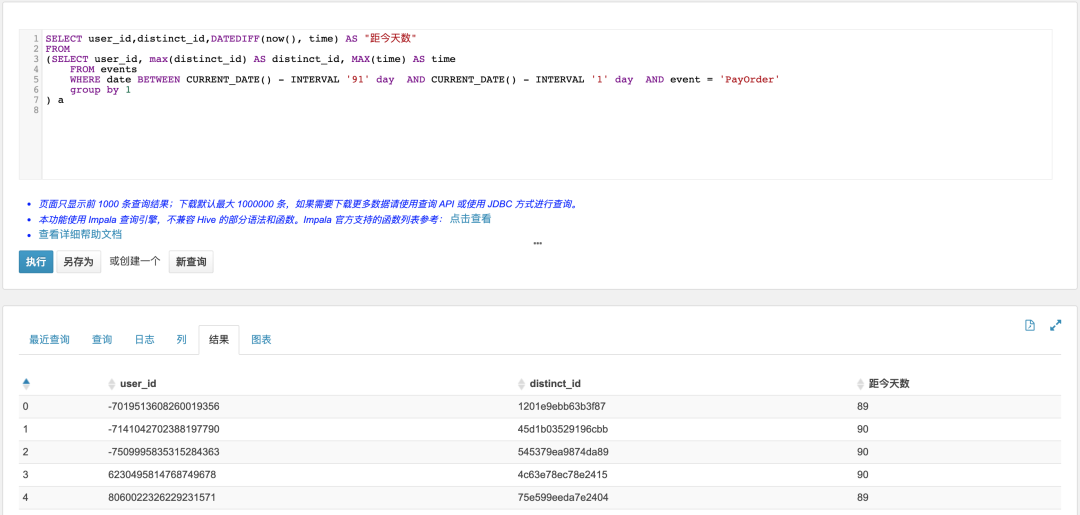
SELECT user_id,distinct_id,DATEDIFF(now(), time) AS "距今天数"FROM(SELECT user_id, max(distinct_id) AS distinct_id, MAX(time) AS timeFROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '91' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'PayOrder'group by 1) a
3.3.3 支付订单金额高于300元的订单中,哪个一级分类最受客户自己偏爱
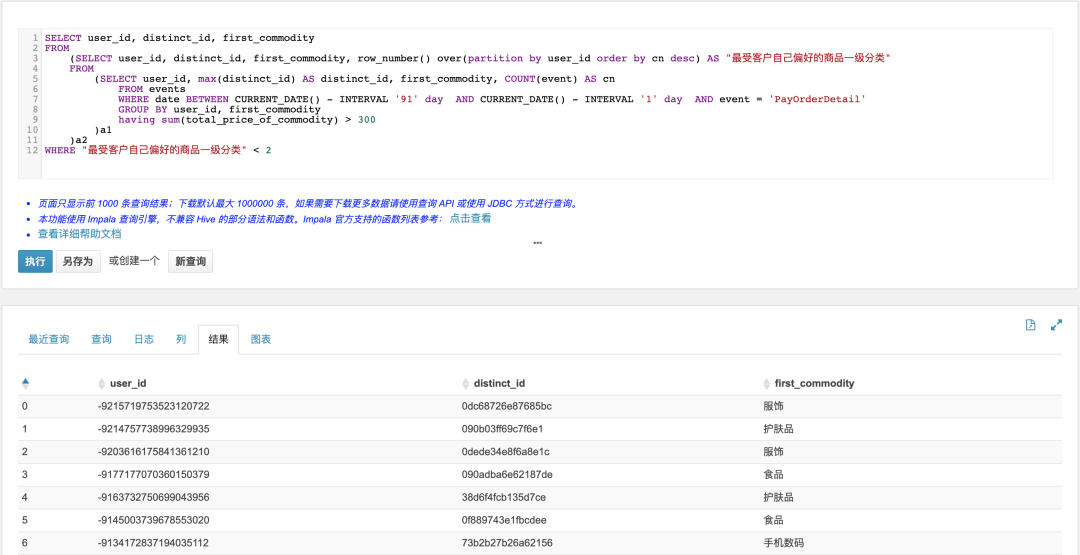
SELECT user_id, distinct_id, first_commodityFROM(SELECT user_id, distinct_id, first_commodity, row_number() over(partition by user_id order by cn desc) AS "最受客户自己偏好的商品一级分类"FROM(SELECT user_id, max(distinct_id) AS distinct_id, first_commodity, COUNT(event) AS cnFROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '91' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'PayOrderDetail'GROUP BY user_id, first_commodityhaving sum(total_price_of_commodity) > 300)a1)a2WHERE "最受客户自己偏好的商品一级分类" < 2
3.3.4 过去90天内,登录App次数分布
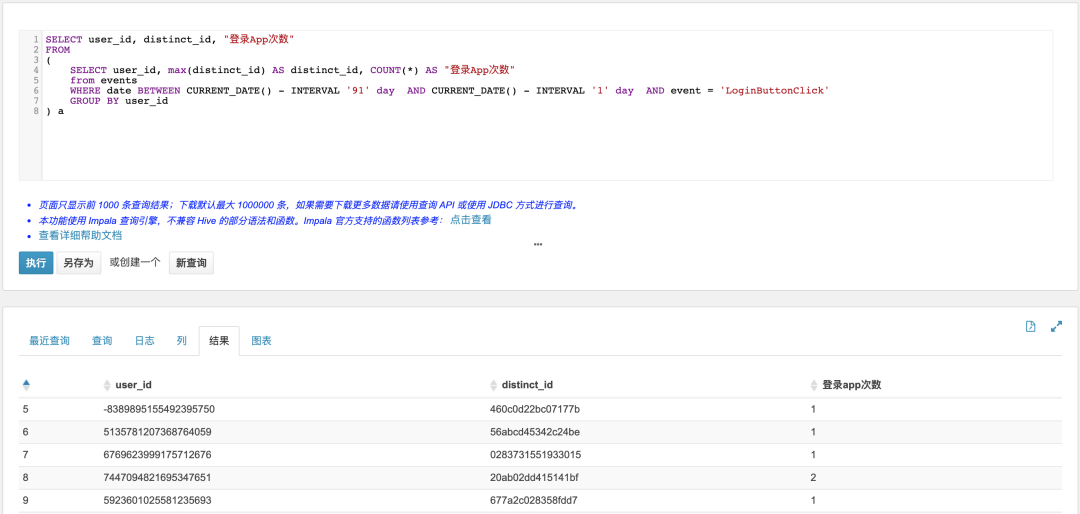
SELECT user_id, distinct_id, "登录App次数"FROM(SELECT user_id, max(distinct_id) AS distinct_id, COUNT(*) AS "登录App次数"from eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '91' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'LoginButtonClick'GROUP BY user_id) a
3.3.5 新增用户数(昨日做过App激活,并且是首次访问)
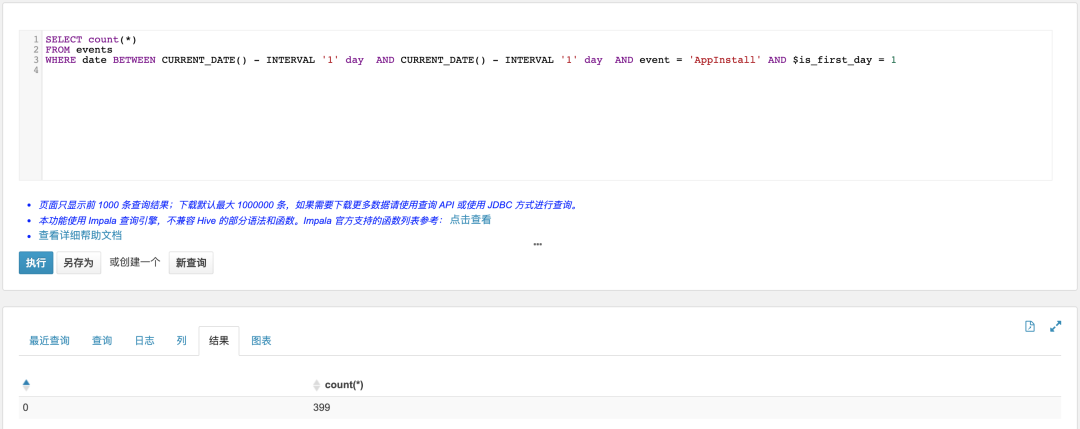
SELECT count(*)FROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '1' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'AppInstall' AND $is_first_day = 1
3.3.6 连续活跃用户(昨日做过App启动,同时满足前天做过App启动)
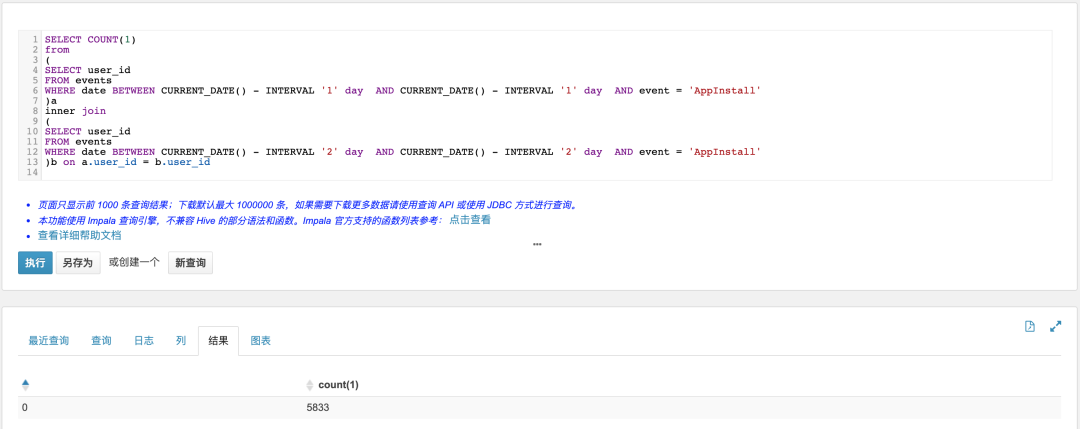
SELECT COUNT(1)from(SELECT user_idFROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '1' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'AppInstall')ainner join(SELECT user_idFROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '2' day AND CURRENT_DATE() - INTERVAL '2' day AND event = 'AppInstall')b on a.user_id = b.user_id
3.3.7 流失用户(昨日之前做过App启动,但昨日没有做过启动App)
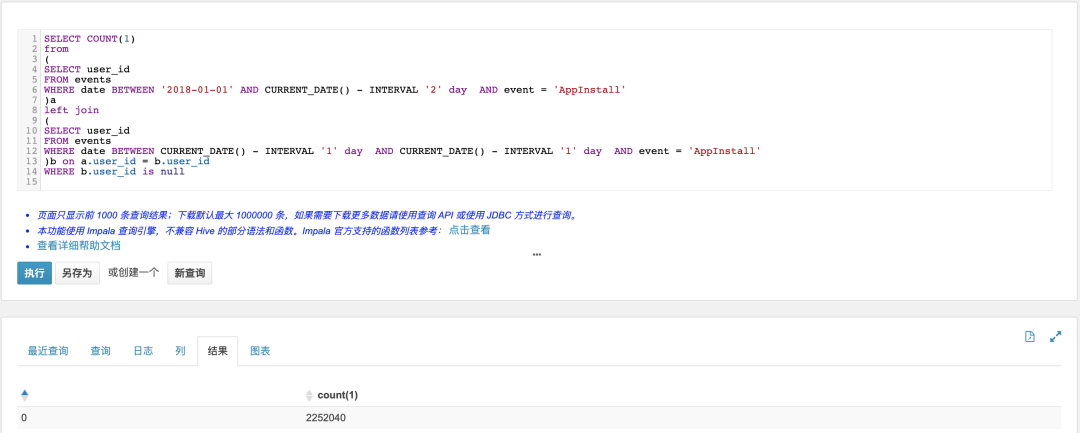
SELECT COUNT(1)from(SELECT user_idFROM eventsWHERE date BETWEEN '2018-01-01' AND CURRENT_DATE() - INTERVAL '2' day AND event = 'AppInstall')aleft join(SELECT user_idFROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '1' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'AppInstall')b on a.user_id = b.user_idWHERE b.user_id is null
3.3.8 回流用户(昨日做过App启动,且不是首次,同时满足前天没做过App启动)
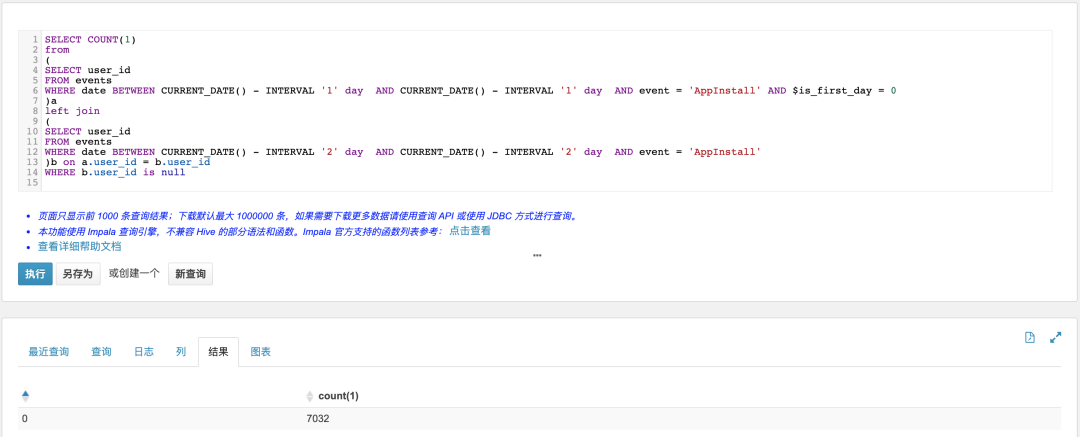
SELECT COUNT(1)from(SELECT user_idFROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '1' day AND CURRENT_DATE() - INTERVAL '1' day AND event = 'AppInstall' AND $is_first_day = 0)aleft join(SELECT user_idFROM eventsWHERE date BETWEEN CURRENT_DATE() - INTERVAL '2' day AND CURRENT_DATE() - INTERVAL '2' day AND event = 'AppInstall')b on a.user_id = b.user_idWHERE b.user_id is null
4 Hive SQL性能优化
4.1 设计合适的数据模型
4.2 优化Hive SQL查询语句
4.2.1 列裁剪和分区裁剪

4.2.2 谓词下推
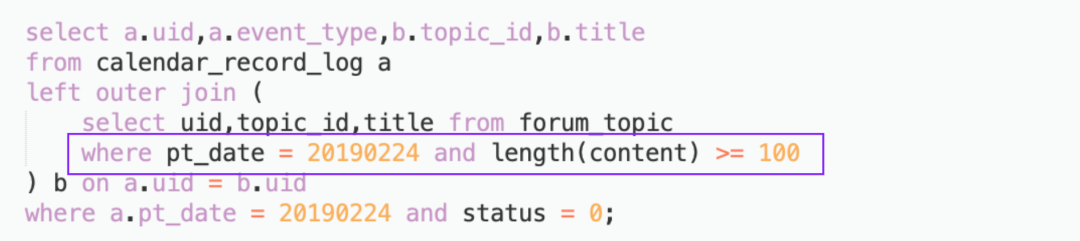
4.2.3 sort by代替order by

4.2.4 group by代替distinct

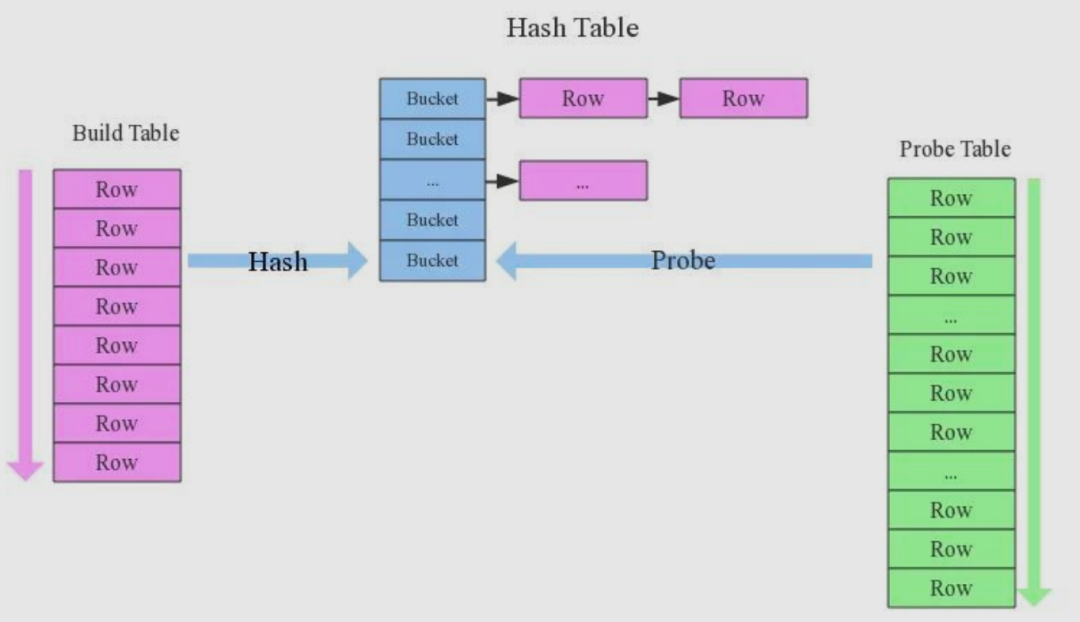
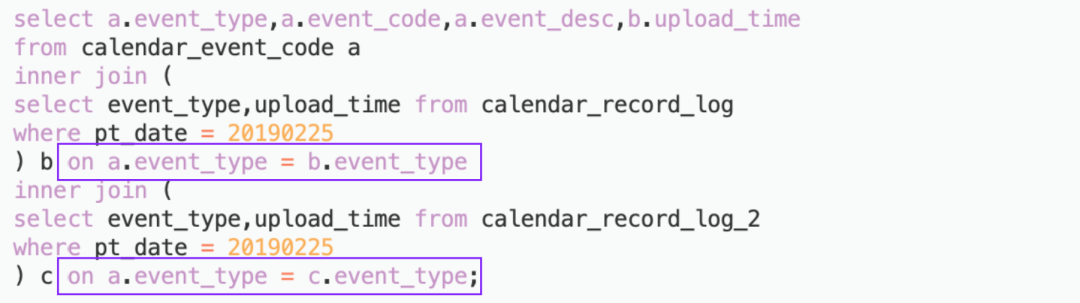
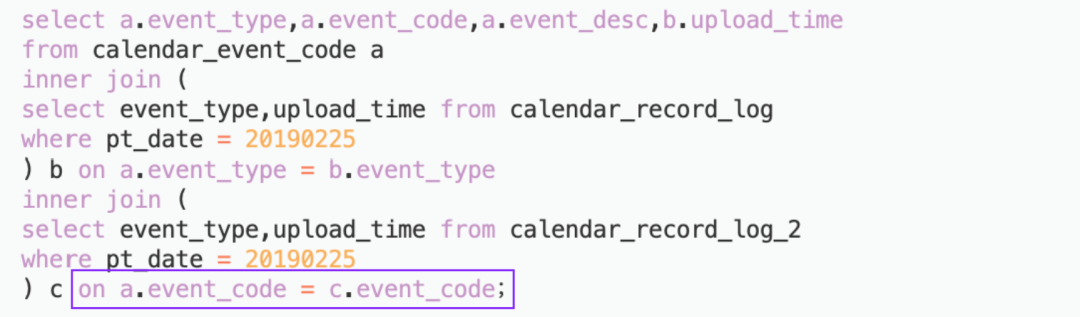
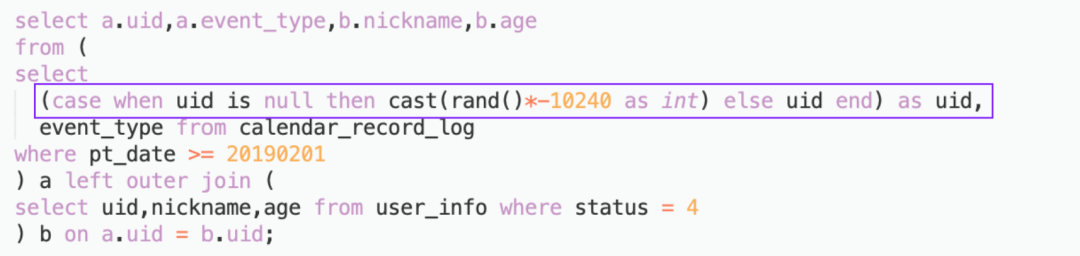
4.2.5 join优化