




在大数据场景下,我们的Spark、Flink等大数据计算引擎都是跑在jvm虚拟机上的,OOM是我们经常遇到的错误信息,要解决这个错误,要求我们对JVM的模型有一些基本了解,下面我们来分析下JVM模型,并且分析下Spark中常见OOM的原因。
JVM的有两种模式分别为
JVM Server模式
JVM Client模式(windows32位操作系统,或者配置比较低的其它类型操作系统)。
mixed mode 混合模式
Java可以是解释型 int ,也可以是编译型comp,我们可以通过参数去设置。
JDK7:永久代--》JDK8:Metaspace(jdk7到jdk8的变化)
JVM的参数有三种类型:
1、标准:从jvm最开始的版本到现在没有发生太大变化
2、X:java -Xint -version 相对变化较少的参数类型
3、XX:变化较多 JVM调优的重点,XX 参数又分为两种,分别是
a)boolean :-XX:[+/-]name(通过+/-号控制参数是否启用)
-XX:+UseG1GC -XX:-UseG1GC
两个命令:jps=>pid
jinfo -flag name pid
jinof -flags pid
b)非boolean(通过k-v的格式来设置参数)
-XX: name=value
-XX:MetaspaceSize=128m
PrintFlags系列
-XX:+PrintFlagsInitial
-XX:+PrintFlagsFinal
=默认值
:=修改过的、
几个特殊的XX参数
-Xmx min -XX:InitialHeapSize 1/64的menmory
-Xms max -XX: MaxHeapSize 1/4的menmory
-Xss -XX:ThreadStackSize 0?
这些是XX参数
MaxTenuringThreshold 新生代到老年代的次数是15次
运行时数据区
jvm定义了很多数据区,分为下面两种,jvm共享的,和每个线程独享的
jvm创建的时候创建,退出时销毁
每个Thread独有,Thread创建时创建,Thread退出时销毁
1)The pc Register 程序计数器 --每个thread独有
占用一小块内存
当前线程所执行的字节码的行号指示器
多线程 每个线程都有自己的程序计数器
字节码 不同的字节码指令干不同的东西 不同的字节码指令让程序干不同的事情
每个线程都有自己的程序计数器
2)Java Virtual Machine Stacks --每个线程独有
方法里面的局部变量 frames:栈贞
一个frame会被创建 当一个方法被调用的时候创建
在方法执行完的时候会被销毁
栈:main==>hello 入栈 出栈
抛出的异常:StackOverflowError
调用方法是,会为每个方法创建Frame 入栈
方法执行完毕后 frame 出栈
递归没出口 死循环会造成这个错误。
3)heap 堆 --所有jvm共享的区域
new 创建对象 数组是会在heap里,
当frame出栈以后 heap里的东西没有被销毁
GC回收对象 当我们在的对象Frames出栈之后,heap里的对象是没有源头指向的,所以需要GC
抛出的异常:OOM OutOfMemory Error 不停的new 比heap大小还大 会OOM
4)Method Area 1.8之后MetaSpace 所有JVM线程共享的
每一个线程的结构 常量池
方法、代码、构造器
.class加载在这里
抛出的异常:OutOfMemoryError
5)Run-Time Constant Pool 存在 Method Area
6)Nativ Method Stacks
native修饰的方法 是调用本地操作系统里面的方法
StackOverflowError/OutOfMemoryError
Area:不属于jvm 属于堆外内存 spark, 直接去操作内存空间
DirectByteBuffer.java类
运行时数据区是一个规范:
JVM内存结构是一个实现
堆区 GC √
新生代 Yong(S0 S1 Eden)
老年代
非堆区
metaspace ccs codecache
谈谈你遇到过的常见的jvm相关的异常信息:
堆管存储、栈管执行
1)java.lang.OutOfMemoryError: Java heap space:这个oom是在我们的heap里的,我们知道我们heap里存储的是我们new出来的对象,所以我们可以通过参数 -Xmx -Xms参数来调节;
2)java.lang.OutOfMemoryError: GC overhead limit exceeded:当GC为释放很小空间占用大量时间时抛出;一般是因为堆太小,导致异常的原因,没有足够的内存。【解决方案】:
1、查看系统是否有使用大内存的代码或死循环;
2、通过添加JVM配置,来限制使用内存:
< jvm-arg>-XX:-UseGCOverheadLimit< jvm-arg>
3) java.lang.OutOfMemoryError: Direct buffer memory。这个是我们用代码直接分配本地的内存,这个内存太小,我们可以手动设定。
调整-XX:MaxDirectMemorySize= 参数,如添加JVM配置:
< jvm-arg>-XX:MaxDirectMemorySize=128m< jvm-arg>
4) java.lang.OutOfMemoryError: unable to create new native thread
【原因】:Stack空间不足以创建额外的线程,要么是创建的线程过多,要么是Stack空间确实小了
5) java.lang.StackOverflowError
这也内存溢出错误的一种,即线程栈的溢出,要么是方法调用层次过多(比如存在无限递归调用),要么是线程栈太小。
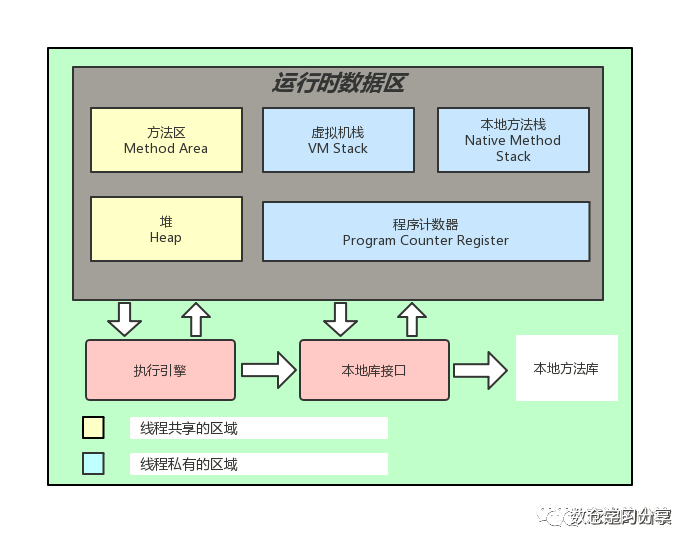
1、当我们编写的java程序被编译成.class文件后,会有类加载器将我们的.class文件加载到方法区里面
2、当方法被调用的时候会进入我们的虚拟机栈,虚拟机栈里面会有方法的局部变量,这个是对象的一个引用,这个引用会指向我们的heap区。
3、程序计数器,记录了我们每一个线程的执行到的字节码的位置。
Spark里的OOM错误
我们先来看下Spark的内存模型
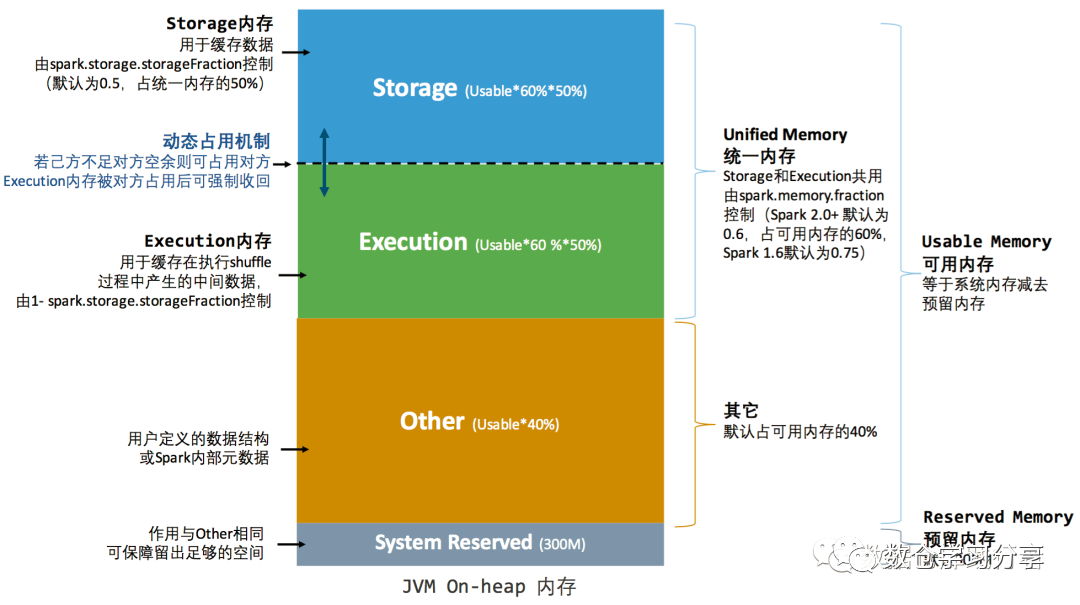
jvm堆内(heap)的内存分为四个部分(spark.memory.fraction=0.6)
reservedMemory:预留内存300M,用于保障spark正常运行
other memory:用于spark内部的一些元数据、用户的数据结构、防止在稀疏和异常大的记录的情况下出现对内存估计不足导致oom时的内存缓冲
execution:用于spark的计算:shuffle、sort、aggregation等这些计算时会用到的内存
storage:主要用于rdd的缓存
spark的OOM错误可能发生在:
Driver端的oom
1、不合适的api调用
2、广播了大变量
Excutor端的OOM错误
1、低效的查询
2、不合适的Driver端和Executor端内存
3、不合适的YARN Container内存
4、内存中缓存了大量数据
5、不合适的任务并行度
Driver端OOM Error
Driver端内存是通过配置“spark.driver.memory”来指定的,默认1g
1. 不适合的API调用
针对这种情况,我们有以下3中解决方法:
最简单粗暴的就是增加Driver端内存。
在RDD/Dataset上调用repartition()方法,将数据交给Executor上的一个任务处理。因为一般来讲,Executor会设置较多的内存。
可以设置“spark.driver.maxResultSize”(默认1g)来避免Driver出现OOM errors。
2. 广播了大变量
将RDD/Dataset进行广播时,会先将它们发送到Driver,然后由Driver端分发给每个Executor,如果我们的应用程序中广播了多个大变量,超出了Driver内存限制,就可能造成OOM Error。
针对这种情况,我们有以下2中解决方法:
增加Driver端内存。
通过配置“spark.sql.autoBroadcastJoinThreshold”减小要广播的变量的大小。
Executor端OOM Error
Executor端内存是通过配置“spark.executor.memory”来指定的,默认1g。
1. 低效的查询
比如,在列式存储格式的表上执行select * from t返回不必要的列;没有提前使用过滤条件过滤掉不必要的数据。
所以,我们在查询的时候,要尽量将过滤条件前置;要尽量只读需要的列;分区表上只查询指定分区的数据等等。
2. 不合适的Driver端和Executor端内存
每个Spark应用程序所需的内存都是不一样的,因此我们要结合所处理的数据的大小和应用监控(比如,Spark Web UI)来合理的为每个应用配置合适的Driver端和Executor端内存大小。
4. 内存中缓存大量数据
如果Spark应用程序指定在内存中缓存了大的RDD/Dataset,或者是缓存了较多的RDD/Dataset,就有可能发生OOM Error:
Spark内存模型中,Execution内存和Storage内存的总大小为0.6*(heap space - 300MB),这总大小里面两者默认各占一半,我们应用中缓存的哪些数据集正是存储在Storage内存区域的。如果Spark应用程序中计算较少,那么我们可以通过spark.memory.storage适当调大Storage内存,或者通过配置spark.memory.fraction整体调大两者的总内存。
5. 不合适任务并行度
假如我们的Spark应用程序中要读取的表或文件数据量比较大,而我们没有配置合适的内存大小,并且分配了比较高的并发度和CPU核数,这些数据要在内存中计算,这就可能会造成Executor端OOM。
如果任务并行度较低,而某个任务又被分配了较多的数据,也会造成OOM。
