




特征缩放
● 在运用一些机器学习算法的时候不可避免地要对数据进行特征缩放,比如:在随机梯度下降算法中,特征缩放有时能提高算法的收敛速度。
01
什么是特征缩放
● 特征缩放大多出现在一些机器学习算法中,大多数情况下,你的数据集将包含在大小、单位和范围上差别很大的特征。但是,由于大多数机器学习算法在计算中使用两个数据点之间的欧氏距离,这会是一个问题。如果不加考虑,这些算法只考虑特征的大小而忽略了单位。在5kg和5000gms不同的单元之间,结果会有很大的差异。在距离计算中,大尺度的特征比小尺度的特征要重要得多。
02
使用特征缩放的作用
●使不同量纲的特征处于同一数值量级,减少方差大 的特征的影响,使模型更准确。
● 加快学习算法的收敛速度。
01
两种方法
● 同比例缩放所有属性的两种常用方法是最小-最大缩放和标准化。
● 最小-最大缩放(又叫做归一化),是将值重新缩放使其最终范围归于0~1之间,实现方法是将值减去最小值并除以最大值和最小值的差。对此,Scikit-Learn提供了一个名为MinMaxScaler的转换器。如果我们希望范围不是0~1,那么可以通过调整超参数feature_range进行更改。
● 标准化则完全不一样,首先减去平均值(所以标准化值的均值总是0),然后除以方差,从而使得结果的分布具备单位方差。不同于最小-最大缩放的是,标准化不将值绑定到特定范围。标准化的方法受异常值的影响更小。Scikit-Learn提供了一个标准化的转换器StandadScaler。
01
小例子
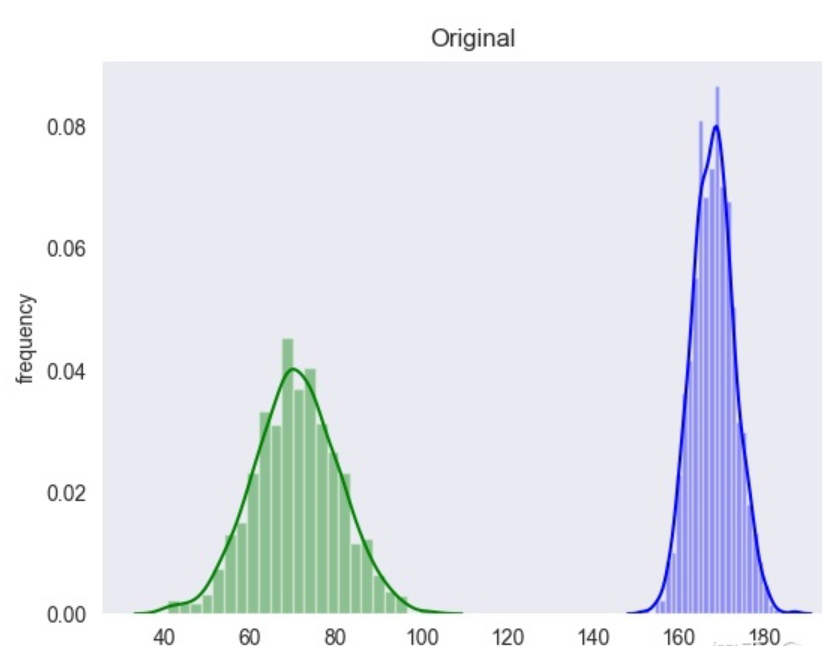
● 举个例子来看看两种方法之间的区别,假设一个数据集包括「身高」和「体重」两个特征,它们都满足正态分布,画出原始数据图像为:
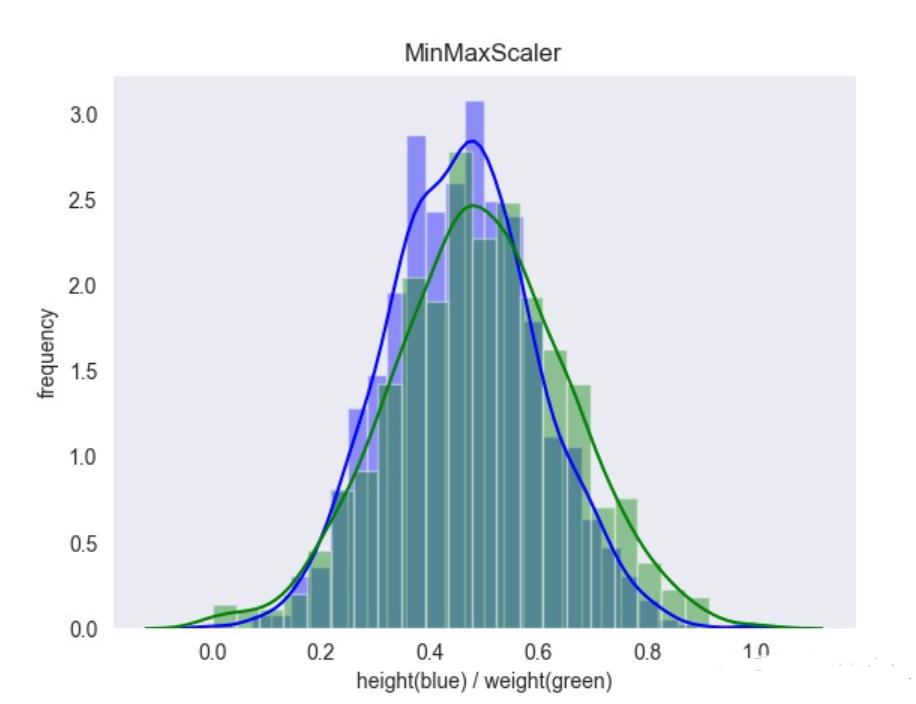
使用MinMaxScaler()缩放,结果为:
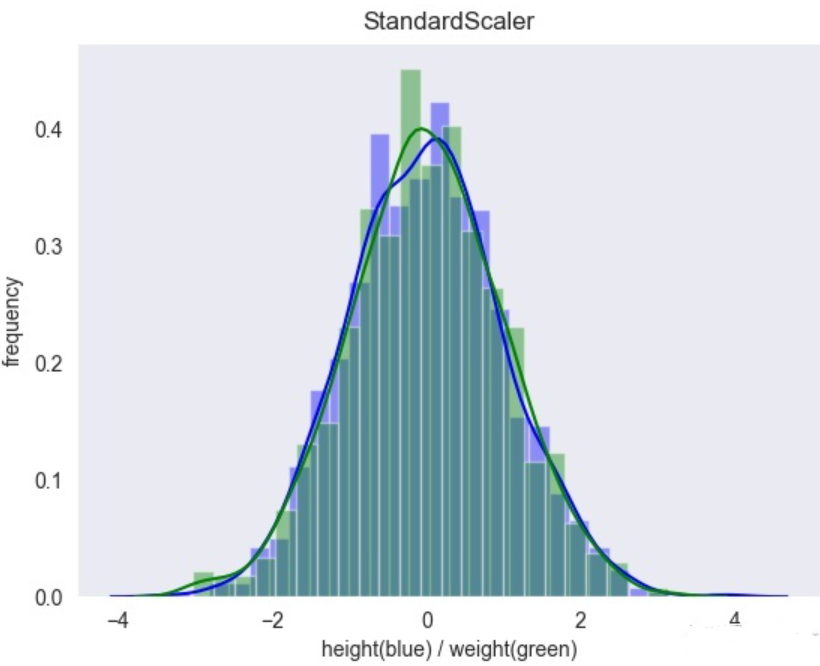
使用StandardScaler()缩放,结果为:

凌云网络实验室
排版/图文|孙梦丹
审核|孙梦丹
