





简介
《大数据:互联网大规模数据挖掘与分布式处理》,原书名:Mining of Massive Datasets,作者是 (美)拉贾拉曼(Rajaraman,A.) (美)厄尔曼(Ullman,J.D.) ,由王斌老师所翻译。本书由斯坦福大学的“web 挖掘”课程的内容总结而成,主要关注极大规模数据的挖掘。主要内容包括分布式文件系统、相似性搜索、搜索引擎技术、频繁项集挖掘、聚类算法、广告管理及推荐系统。

这本书可以作为学大数据的一个指南,虽然说它讲得并不深,但是几乎包含了大数据领域的各种关键词句,以它为引导,可以将整个大数据体系给清楚地罗列一下,个人意见,很适合刚入门的小白们了解一下哟!
本书比较新意的是将map-reduce引入到内容中,有一定借鉴意义。有些内容是偏理论,先引导,再实践。

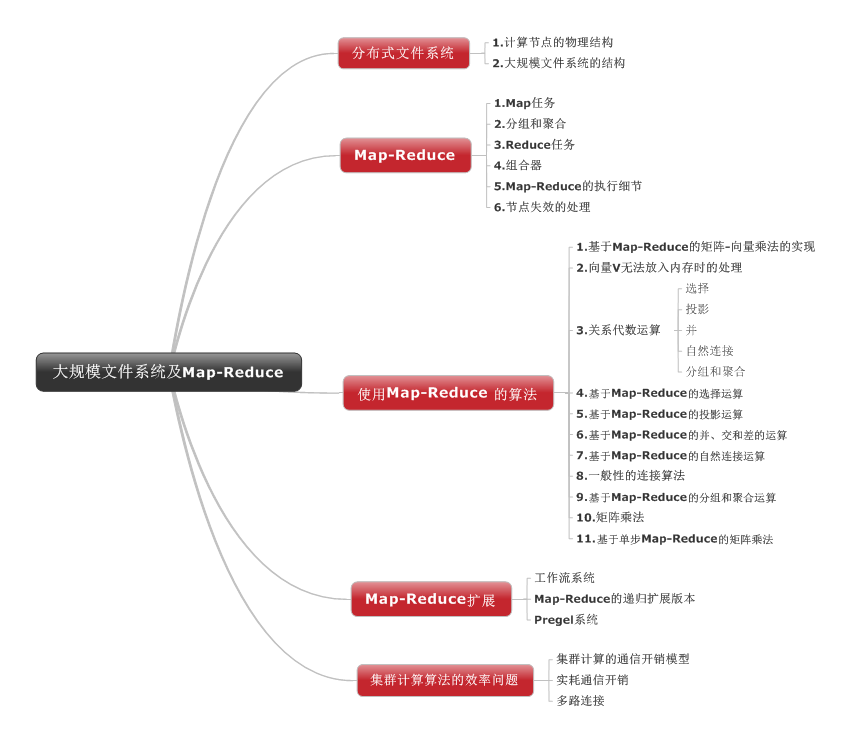
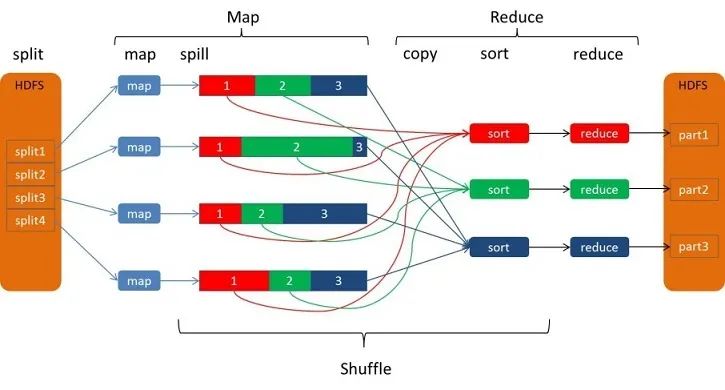
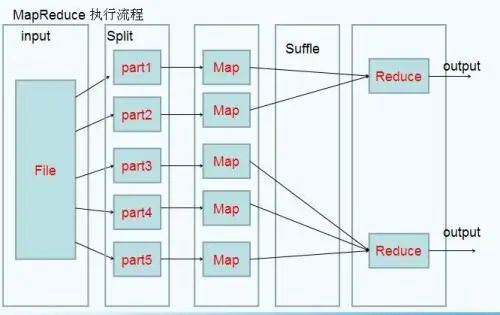

这本书对map-reduce介绍的比较浅显易懂。集合运算的map-reduce实现,也有一定的参考意义。后面对map-reduce扩展以及map-reduce算法效率问题的理论理论知识也可以进行参考,欢迎大家去阅读哟!

图文:杨立
审核:马淑芳
文章转载自凌云网络实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
