




总共给定三份数据,数据名分别为users.csv,train.csv,test.csv,其中各字段解释如下:
User_id:买家ID
Item_id:商品ID
Cat_id:商品类别
Merchant_id:卖家ID
Brand_id:品牌ID
Month_id:交易月份
Day:交易日期
Action:交易行为,0表示点击、1表示加入购物车、2表示购买、3表示关注商品
Age_range:卖家年龄分段,1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知;
Gender:0表示女性、1表示男性,2和NULL表示未知
Province:收获地址省份
要求:利用Hive进行数据预处理与探索性数据分析,需要完成以下操作
首先要ssh localhost免密登录,cd usr/local/Cellar/hadoop/hadoop-3.1.2/sbin 启动Hadoop后,cd usr/local/Cellar/hive/3.1.2/libexec/bin 才能启动Hive,因为Hive是基于Hadoop平台的数据仓库。
step1:创建database maggie_test;
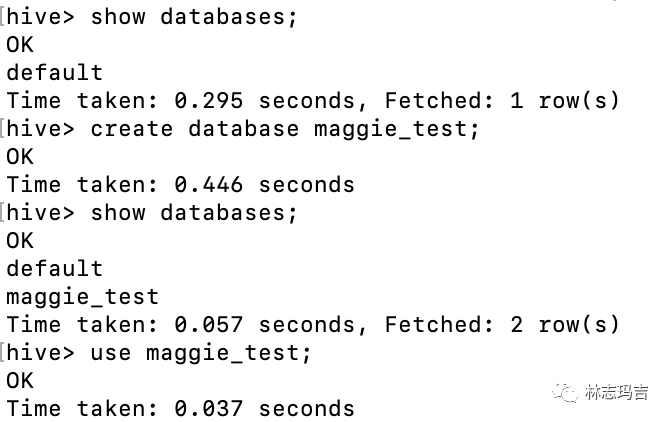
step2:按照csv文件格式创建表;

step3:将本地数据导入到hive表中;

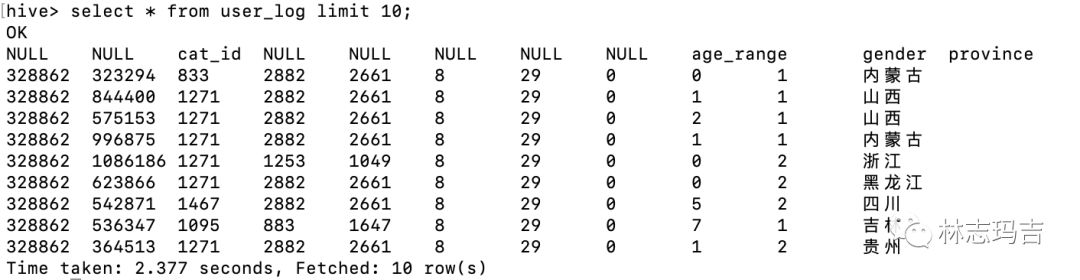
step4: 查看数据是否准确;
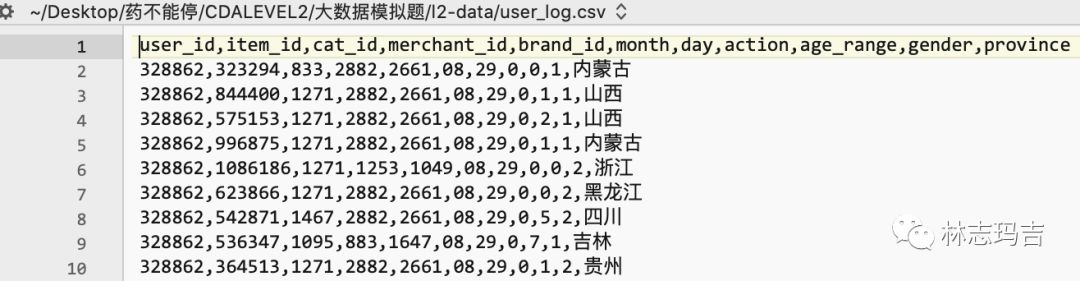
BBEidt打开的,由于2.6G的文件,excel无法打开,用BBEdit看个大概。
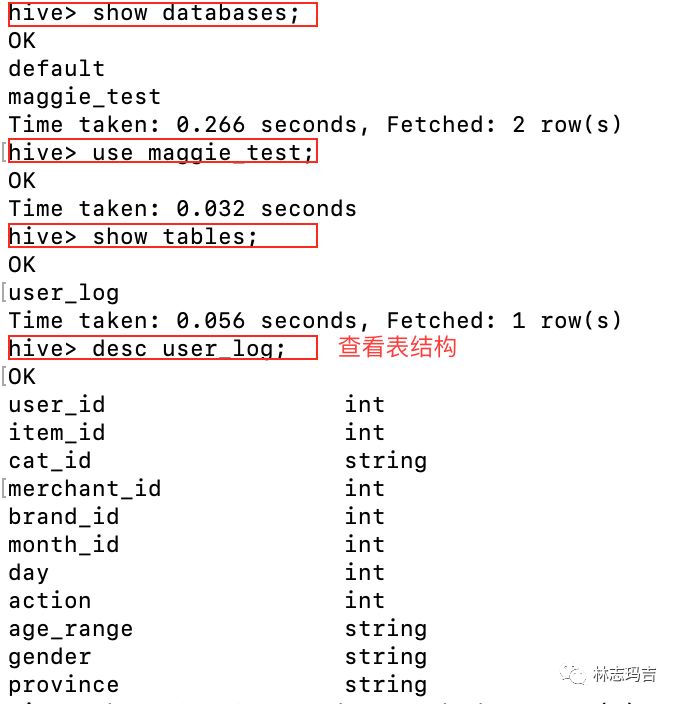
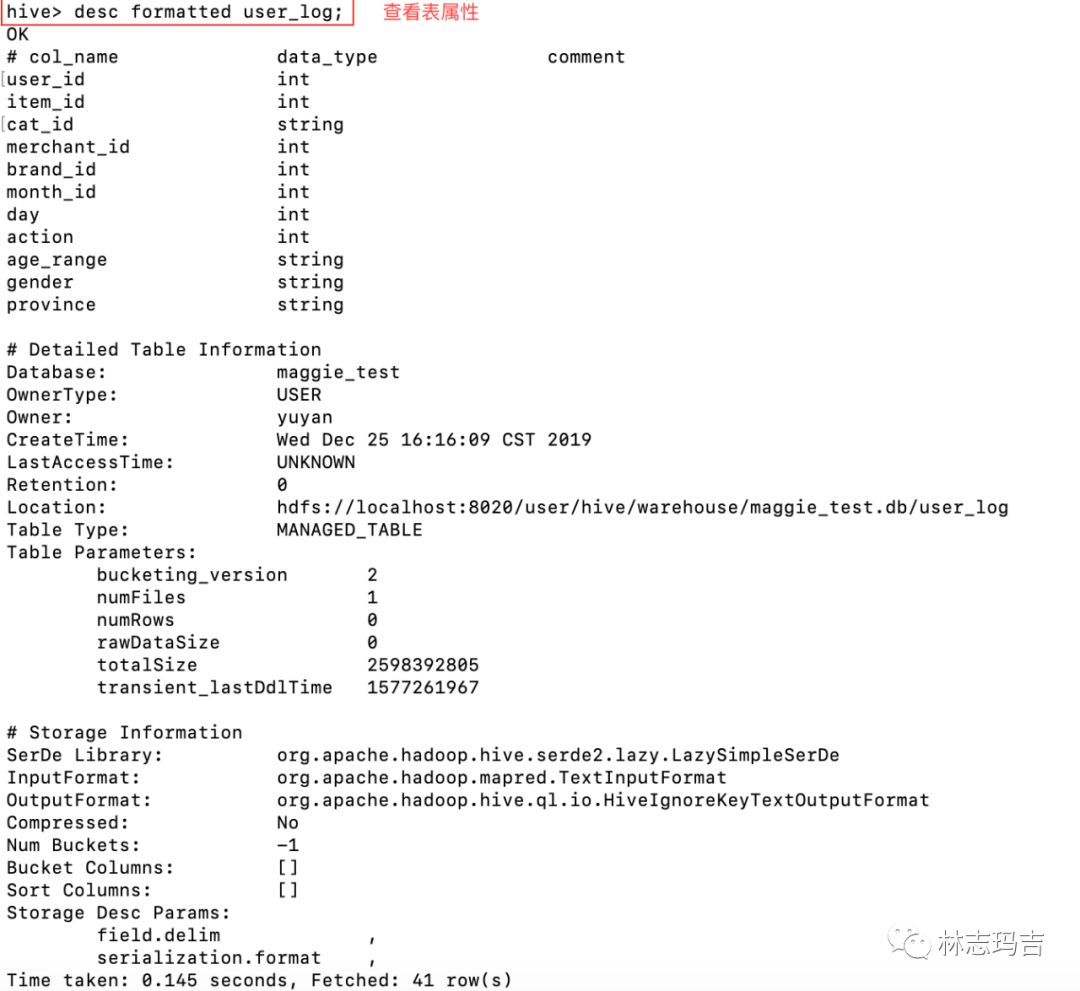
2. 用Hive查询users.csv表结构及属性
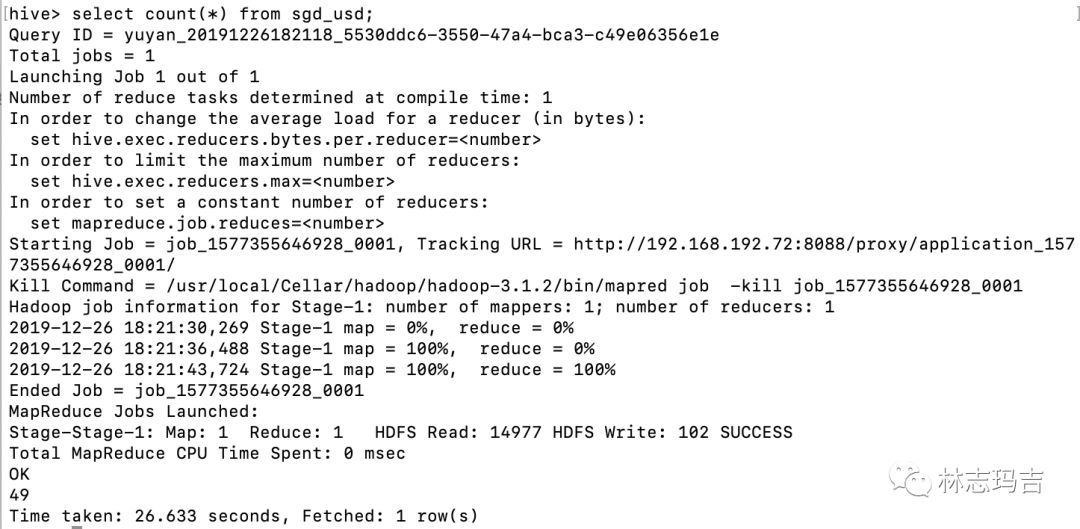
3. 使用count聚合函数查询数据数量
原想用user_log.csv来尝试,但是由于数据量过于巨大,准备用一个小一点的数据去尝试。
sgd_usd是新加坡兑美元汇率(2015-2018 monthly);
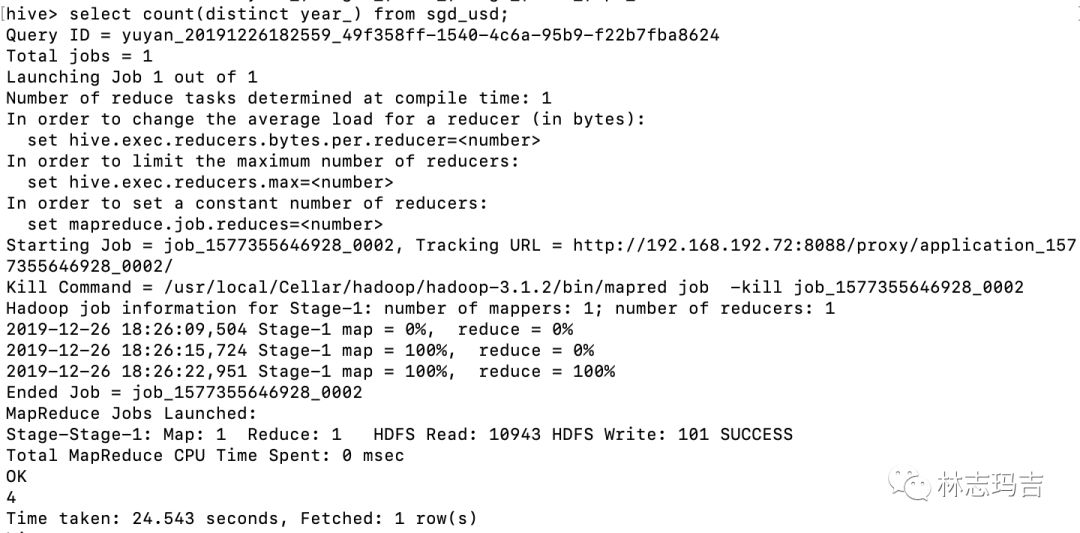
4. 使用distinct方法查询不重复数据数量
5. 查询双十一当天发生购买行为的顾客数量
这个就不再测试了,没有什么意义。但是由于我电脑内存有限,还剩18g不敢随随便便跑个2.6g的数据。
select count(*) from user_log where month_id = 11 and day = 11 and Action =2;
reference:
1)https://www.jianshu.com/p/3e99d09ad430
2)https://cloud.tencent.com/developer/ask/33907
3)https://www.cnblogs.com/dozn/p/9040237.html
