





以下内容来自第三届携程大数据沙龙
1.业务分析人员的抉择
数据平台有多个可选的查询引擎,无数需要交互的查询语句,那么业务人员应该选择哪个引擎进行SQL语句的执行呢?
2.痛点
用户痛点:
不了解查询引擎,不知如何选择
需要更低的查询失败率
运维痛点:
引擎的忙闲不一,资源利用率低
客户端部署繁琐
3.交互查询平台的职责
提交SQL => 自适应引擎 => 返回查询结果
所以,需要引入统一引擎来解决这个问题
4.核心功能
统一鉴权
SQL路由
特征收集
引擎降级
引擎插件化
语法转换
限流
5.逻辑架构

6.模块层级

7.如何自适应引擎
(1)SQL画像
(2)打分排序
8.SQL画像
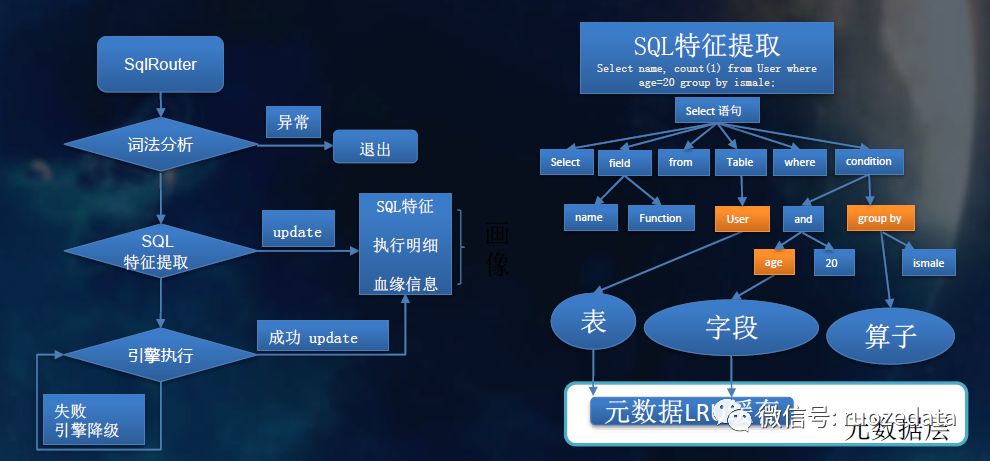
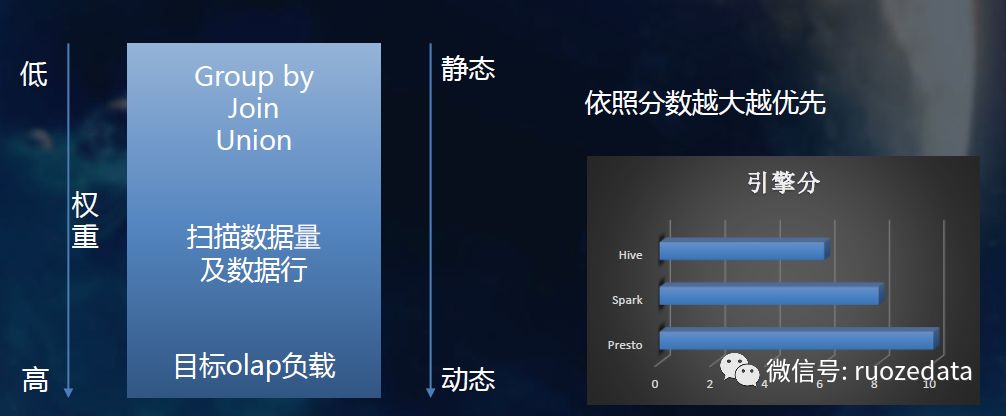
9.引擎打分和排序
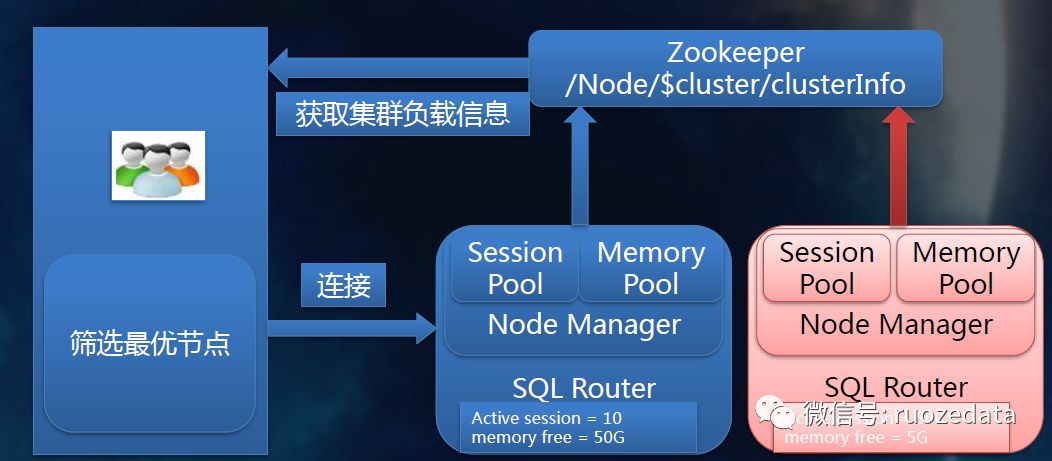
10.集群及负载均衡
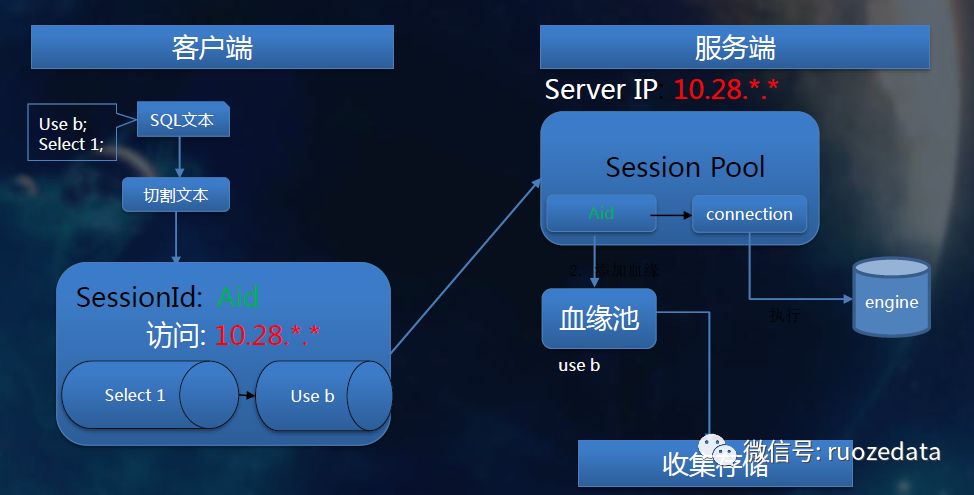
11.查询上下文的实现
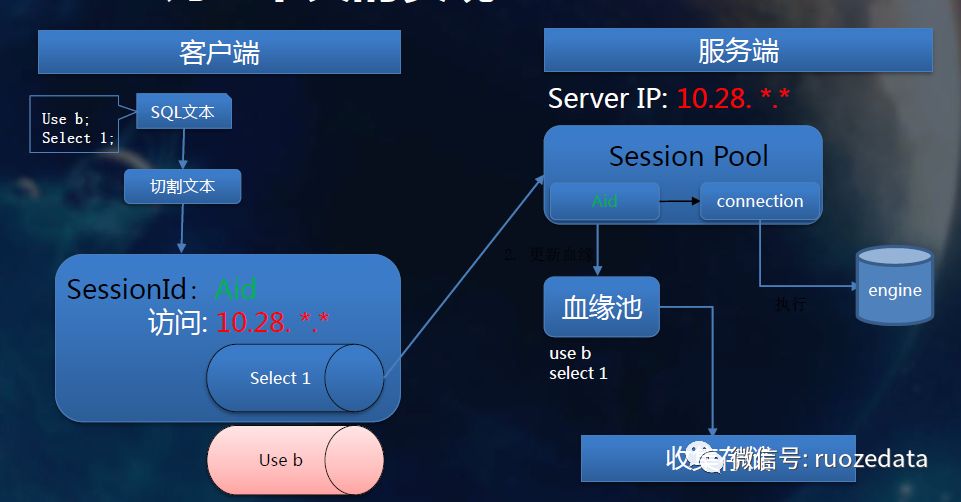
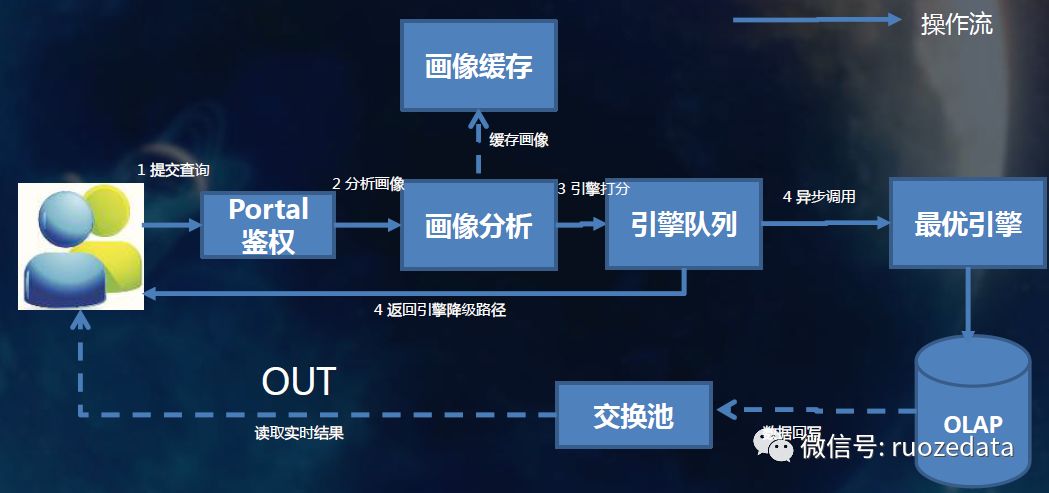
12.查询流程
13.思考
(1)缓存击穿,缓存失效?
(2)如何更有效地传输数据?
14.展望
技术面
(1)基于SQL画像的特征分析,自动构建Kylin cube,并接入Kylin引擎。
(2)基于逻辑回归算法,实现引擎智能路由。
(3)语法的深度转换和重写。
应用面
(1)API对外方式接入用户。
(2)接入报表平台
(3)替换查询工具的底层引擎。
回归原创文章:
最全的Flink部署及开发案例(KafkaSource+SinkToMySQL)
代码 | Spark读取mongoDB数据写入Hive普通表和分区表
文章转载自若泽大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
