





2 瀚高的全文检索简介
3 瀚高全文检索分词简介
4 瀚高全文检索常见索引
4.1 GIN索引结构
4.2 RUM索引
5 基于词库的解决方案
5.1 基于SCWS分词
5.2 基于pg_jieba 分词
6 基于二元分词的解决方案
A 测试用例
【基于SCWS分词的全文检索测试用例】
【基于pg_jieba的全文检索测试用例】
【基于二元分词的全文检索测试用例】
1 数据分类
数据是数据库中存储的基本对象,凡是计算机中用来描述事物的记录都可以统称为数据,包括数字、文字、图形、图像、音频、视频、学生的档案记录等等,可以分为两类:结构化数据、非结构化数据。
2 瀚高的全文检索简介

3 瀚高全文检索分词简介
4 瀚高全文检索常见索引
4.1 GIN索引结构
4.1.1逻辑结构
4.1.2物理结构
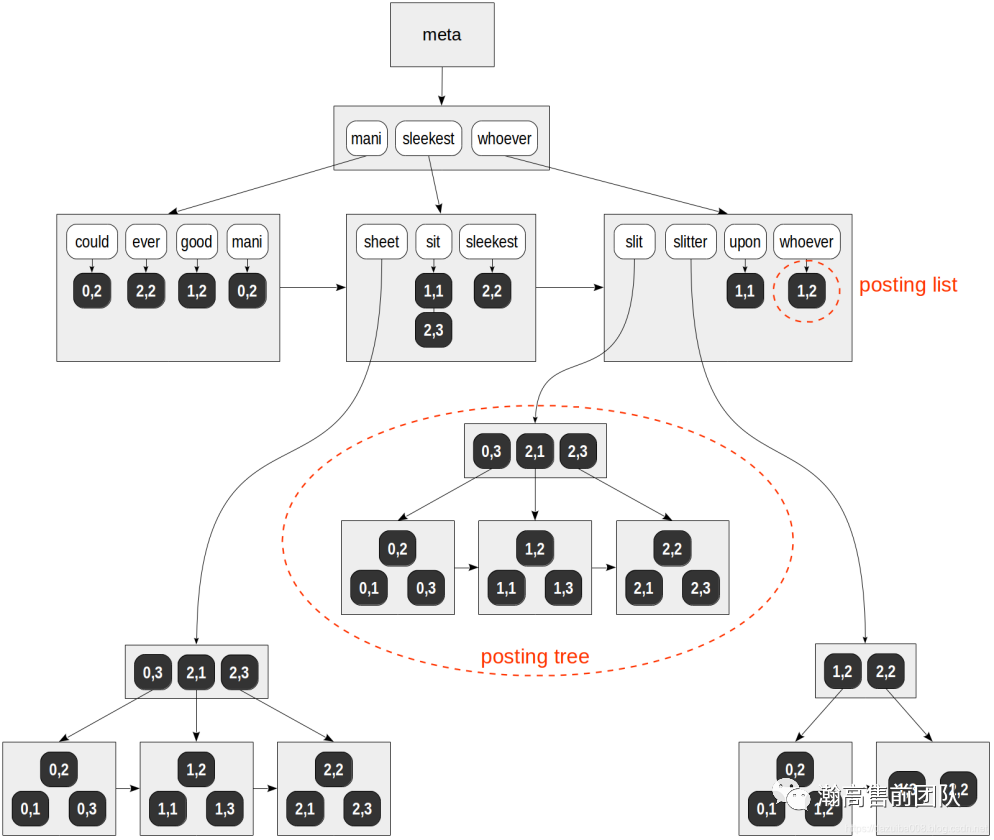
4.2 RUM索引
5 基于词库的解决方案
#Step1:Downloadswget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2#Step2:在pg的安装目录下创建文件夹swcs,解压tar xvjf scws-1.2.3.tar.bz2#step3:安装/configure --prefix=/usr/local/scws ; make ; make install#Step4:下载解压词典cd /usr/local/scws/etcwget http://www.xunsearch.com/scws/down/scws-dict-chs-gbk.tar.bz2wget http://www.xunsearch.com/scws/down/scws-dict-chs-utf8.tar.bz2tar xvjf scws-dict-chs-gbk.tar.bz2tar xvjf scws-dict-chs-utf8.tar.bz2
#Step1:在pg的安装目录下打开文件夹scwscd scws#Step2:把压缩包上传到该目录里面,然后解压unzip zhparser-master.zip#Step3:进入到解压的目录cd zhparser-master#Step4:进行安装SCWS_HOME=/usr/local make&&make install
#可以在瀚高的安装目录或者root/pg_jieba。#Step1:Downloadsgit clone https://github.com/jaiminpan/pg_jieba#Step2:Compilecdpg_jiebaUSE_PGXS=1 makeUSE_PGXS=1 make install# if got error when doing "USE_PGXS=1 make install"# try "sudo USE_PGXS=1 make install"
6 基于二元分词的解决方案
6.1 使用步骤
CREATE TABLE test_rum(id int, message text);CREATE INDEX rumidx ON test_rum USING rum(message rum_text_ops);
INSERT INTO test_rum VALUES (1,'我在青岛');INSERT INTO test_rum VALUES (2,'我在济南大明湖');
set enable_seqscan=OFF;select * from test_rum WHERE message % '青岛';select * from test_rum WHERE message % '我在青岛';
6.2 操作符
select * from test_rum WHERE message % '青岛 | 济南';select * from test_rum WHERE message % '济南 & 大明湖';
select * from test_rum WHERE message LIKE '青岛';select * from test_rum WHERE message LIKE '%青岛';
A 测试用例
【基于SCWS分词的全文检索测试用例】
create extension zhparser;
create text search configuration chinese (PARSER = zhparser);
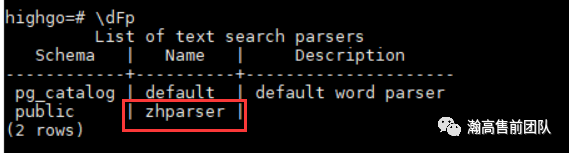
\dFp
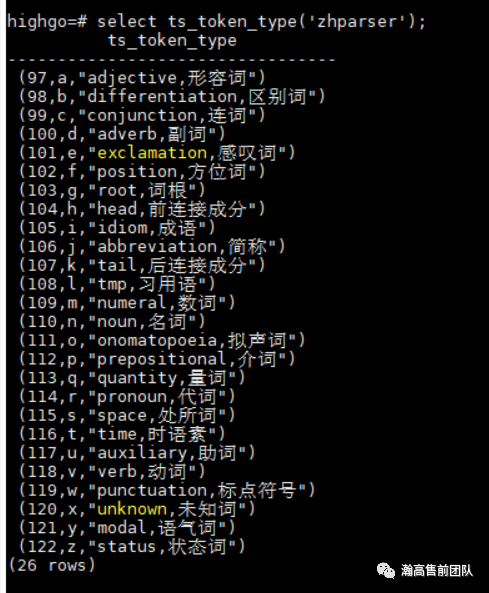
select ts_token_type('zhparser');
alter text search configuration chinese add mapping for n,v,a,i,e,l with simple;
create table gin_zhparser_test (id integer, title varchar(50),content text, primary key(id), tsv_content tsvector);
insert into gin_zhparser_test values(generate_series(1,100000),'《丑小鸭》', '一只只小鸭子都从蛋壳里钻出来了,就剩下一个特别大的蛋。过了好几天,这个蛋才慢慢裂开,钻出一只又大又丑的鸭子。他的毛灰灰的,嘴巴大大的,身子瘦瘦的,大家都叫他“丑小鸭”。 丑小鸭来到世界上,除了鸭妈妈,谁都欺负他。哥哥、姐姐咬他,公鸡啄他,连养鸭的小姑娘也讨厌他。丑小鸭感到非常孤单,就钻出篱笆,离开了家。 丑小鸭来到树林里,小鸟讥笑他,猎狗追赶他。他白天只好躲起来,到了晚上才敢出来找吃的。 秋天到了,树叶黄了,丑小鸭来到湖边的芦苇里,悄悄地过日子。一天傍晚,一群天鹅从空中飞过。丑小鸭望着洁白美丽的天鹅,又惊奇又羡慕。 天越来越冷,湖面结了厚厚的冰。丑小鸭趴在冰上冻僵了。幸亏一位农夫看见了,把他带回家。 一天,丑小鸭出来散步,看见丁香开花了,知道春天来了。他扑扑翅膀,向湖边飞去,忽然看见镜子似的湖面上,映出一个漂亮的影子,雪白的羽毛,长长的脖子,美丽极了。这难道是自己的影子?啊,原来我不是丑小鸭,是一只漂亮的天鹅呀! );。
explain analyze select * from gin_zhparser_test where content like '%迎接%美好生活%';

update gin_zhparser_testset tsv_content = to_tsvector('chinese', coalesce(content,''));
Create index idx_gin_test on gin_zhparser_test using gin(tsv_content);
explain analyze select * from gin_zhparser_test where tsv_content @@ plainto_tsquery('迎接美好生活');

create extension pg_jieba;
create table pg_jieba_test (id integer, title varchar(50),content text, primary key(id), tsv_content tsvector);
insert into pg_jieba_test values((generate_series(1,100000),'《丑小鸭》', '一只只小鸭子都从蛋壳里钻出来了,就剩下一个特别大的蛋。过了好几天,这个蛋才慢慢裂开,钻出一只又大又丑的鸭子。他的毛灰灰的,嘴巴大大的,身子瘦瘦的,大家都叫他“丑小鸭”。丑小鸭来到世界上,除了鸭妈妈,谁都欺负他。哥哥、姐姐咬他,公鸡啄他,连养鸭的小姑娘也讨厌他。丑小鸭感到非常孤单,就钻出篱笆,离开了家。丑小鸭来到树林里,小鸟讥笑他,猎狗追赶他。他白天只好躲起来,到了晚上才敢出来找吃的。秋天到了,树叶黄了,丑小鸭来到湖边的芦苇里,悄悄地过日子。一天傍晚,一群天鹅从空中飞过。丑小鸭望着洁白美丽的天鹅,又惊奇又羡慕。天越来越冷,湖面结了厚厚的冰。丑小鸭趴在冰上冻僵了。幸亏一位农夫看见了,把他带回家。一天,丑小鸭出来散步,看见丁香开花了,知道春天来了。他扑扑翅膀,向湖边飞去,忽然看见镜子似的湖面上,映出一个漂亮的影子,雪白的羽毛,长长的脖子,美丽极了。这难道是自己的影子?啊,原来我不是丑小鸭,是一只漂亮的天鹅呀!');
explain analyze select * from pg_jieba_test where content like '%迎接美好生活%';

update pg_jieba_test set tsv_content = to_tsvector('jiebacfg', coalesce(content,''));
create index idx_pgjieba_test on pg_jieba_test using gin(tsv_content);
explain analyze select * from pg_jieba_test where tsv_content @@ plainto_tsquery '迎接美好生活';

【基于二元分词的全文检索测试用例】
CREATE TABLE rum_test(id int, message text);
insert into rum_tes values((generate_series(1,100000), '《丑小鸭》 一只只小鸭子都从蛋壳里钻出来了,就剩下一个特别大的蛋。过了好几天,这个蛋才慢慢裂开,钻出一只又大又丑的鸭子。他的毛灰灰的,嘴巴大大的,身子瘦瘦的,大家都叫他“丑小鸭”。丑小鸭来到世界上,除了鸭妈妈,谁都欺负他。哥哥、姐姐咬他,公鸡啄他,连养鸭的小姑娘也讨厌他。丑小鸭感到非常孤单,就钻出篱笆,离开了家。丑小鸭来到树林里,小鸟讥笑他,猎狗追赶他。他白天只好躲起来,到了晚上才敢出来找吃的。秋天到了,树叶黄了,丑小鸭来到湖边的芦苇里,悄悄地过日子。一天傍晚,一群天鹅从空中飞过。丑小鸭望着洁白美丽的天鹅,又惊奇又羡慕。天越来越冷,湖面结了厚厚的冰。丑小鸭趴在冰上冻僵了。幸亏一位农夫看见了,把他带回家。一天,丑小鸭出来散步,看见丁香开花了,知道春天来了。他扑扑翅膀,向湖边飞去,忽然看见镜子似的湖面上,映出一个漂亮的影子,雪白的羽毛,长长的脖子,美丽极了。这难道是自己的影子?啊,原来我不是丑小鸭,是一只漂亮的天鹅呀!');
explain analyze select * from rum_test where message like '%迎接美好生活%';

CREATE INDEX idx_rumtest ON rum_test USING zhfts (message zhfts_text_ops);
explain analyze select * from rum_test where message % '迎接美好生活';


文章转载自瀚高数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
