




1. Spark概述
1. 什么是Spark?Spark作为Apache顶级的开源项目,是一个快速、通用的大规模数据处理引擎,和Hadoop的MapReduce计算框架类似,但是相对于MapReduce,Spark凭借其可伸缩、基于内存计算等特点,以及可以直接读写Hadoop上任何格式数据的优势,进行批处理时更加高效,并有更低的延迟。相对于“one stack to rule them all”的目标,实际上,Spark已经成为轻量级大数据快速处理的统一平台,各种不同的应用,如实时流处理、机器学习、交互式查询等,都可以通过Spark建立在不同的存储和运行系统上。
2. Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
3. Spark于2009年诞生于加州大学伯克利分校AMPLab。目前,已经成为Apache软件基金会旗下的顶级开源项目。相对于MapReduce上的批量计算、迭代型计算以及基于Hive的SQL查询,Spark可以带来上百倍的性能提升。目前Spark的生态系统日趋完善,Spark SQL的发布、Hive on Spark项目的启动以及大量大数据公司对Spark全栈的支持,让Spark的数据分析范式更加丰富。
伯克利数据分析栈(DBAS)图:
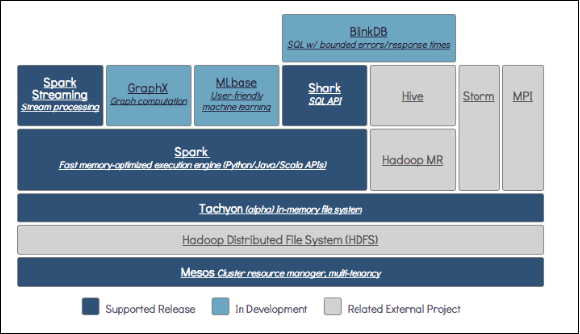
2. Spark大数据处理框架
相较于国内外较多的大数据处理框架,Spark以其低延时的出色表现,正在成为继Hadoop的MapReduce之后,新的、最具影响的大数据框架之一。以Spark为核心的整个生态圈,最底层为分布式存储系统HDFS、Amazon S3、Mesos,或者其他格式的存储系统(如HBase);资源管理采用Mesos、YARN等集群资源管理模式,或者Spark自带的独立运行模式,以及本地运行模式。在Spark大数据处理框架中,Spark为上层多种应用提供服务。例如,Spark SQL提供SQL查询服务,性能比Hive快3~50倍;MLlib提供机器学习服务;GraphX提供图计算服务;Spark Streaming将流式计算分解成一系列短小的批处理计算,并且提供高可靠和吞吐量服务。值得说明的是,无论是Spark SQL、Spark Streaming、GraphX还是MLlib,都可以使用Spark核心API处理问题,它们的方法几乎是通用的,处理的数据也可以共享,不仅减少了学习成本,而且其数据无缝集成大大提高了灵活性。
框架中核心组件图:
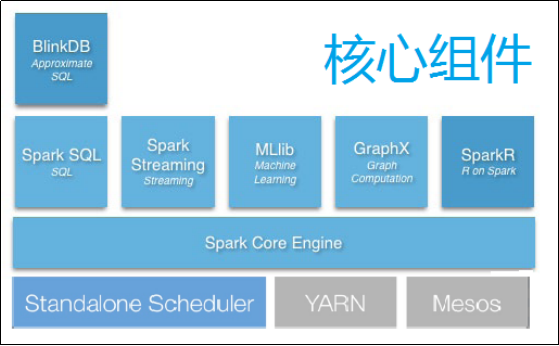
3. Spark之于Hadoop
更准确地说,Spark是一个计算框架,而Hadoop中包含计算框架MapReduce和分布式文件系统HDFS,Hadoop更广泛地说还包括在其生态系统上的其他系统,如Hbase、Hive等。Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储层,可融入Hadoop的生态系统,以弥补缺失MapReduce的不足。
Spark与Hadoop在数据中间数据处理区别:
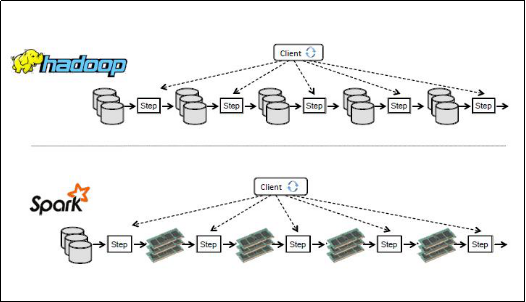
Spark相比Hadoop MapReduce的优势如下:
1. 中间结果输出
基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。出于任务管道承接的考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果。
Spark将执行模型抽象为通用的有向无环图执行计划(DAG),这可以将多Stage的任务串联或者并行执行,而无须将Stage中间结果输出到HDFS中。类似的引擎包括Dryad、Tez。
2. 数据格式和内存布局
由于MapReduce Schema on Read处理方式会引起较大的处理开销。Spark抽象出分布式内存存储结构弹性分布式数据集RDD,进行数据的存储。RDD能支持粗粒度写操作,但对于读取操作,RDD可以精确到每条记录,这使得RDD可以用来作为分布式索引。Spark的特性是能够控制数据在不同节点上的分区,用户可以自定义分区策略,如Hash分区等。Shark和Spark SQL在Spark的基础之上实现了列存储和列存储压缩。
3. 执行策略
MapReduce在数据Shuffle之前花费了大量的时间来排序,Spark则可减轻上述问题带来的开销。因为Spark任务在Shuffle中不是所有情景都需要排序,所以支持基于Hash的分布式聚合,调度中采用更为通用的任务执行计划图(DAG),每一轮次的输出结果在内存缓存。
4. 任务调度的开销
传统的MapReduce系统,如Hadoop,是为了运行长达数小时的批量作业而设计的,在某些极端情况下,提交一个任务的延迟非常高。Spark采用了事件驱动的类库AKKA来启动任务,通过线程池复用线程来避免进程或线程启动和切换开销。
