




这篇文章会把我们生产环境中的source都简单讲解和做个小案例。
Avro类型的Source
监听Avro 端口来接收外部avro客户端的事件流。和netcat不同的是,avro-source接收到的是经过avro序列化后的数据,然后反序列化数据继续传输。所以,如果是avro-source的话,源数据必须是经过avro序列化后的数据。而netcat接收的是字符串格式。(针对Avro以后会有文章详讲)
利用Avro source可以实现多级流动、扇出流、扇入流等效果。另外,也可以接收通过flume提供的avro客户端发送的日志信息。
Arvo配置选项说明
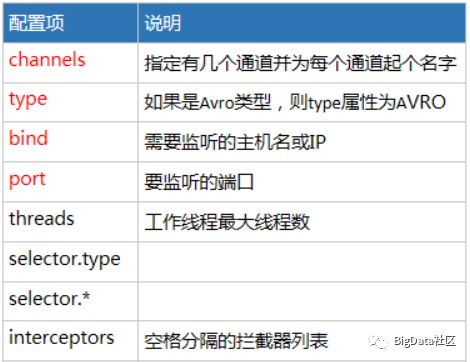
实现步骤:
1.修改配置文件,source的type属性为avro
2.根据指定的配置文件启动flume
格式代码,template-avro.conf为例子:
#配置Agent a1 的组件a1.sources=r1a1.channels=c1a1.sinks=s1#描述/配置a1的source1a1.sources.r1.type=avroa1.sources.r1.bind=0.0.0.0a1.sources.r1.port=44444#描述sinka1.sinks.s1.type=logger#描述内存channela1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transactionCapacity=100#位channel 绑定 source和sinka1.sources.r1.channels=c1a1.sinks.s1.channel=c1
2.Exec类型的Source
使用场景:
Exec Source可通过tail -f命令去tail住一个文件,然后实时同步日志到sink。但存在的问题是,当agent进程挂掉重启后,会有重复消费的问题。可以通过增加UUID来解决,或通过改进ExecSource来解决。
可以将命令产生的输出作为源
Exec Source 可配置选项说明
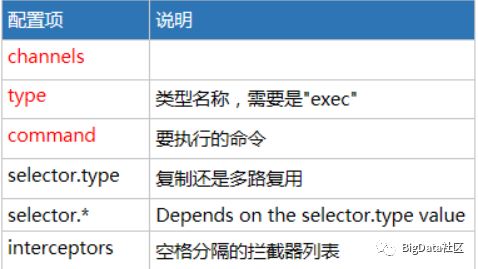
实现步骤:
1.修改配置文件,source的type属性为avro
配置代码:#配置Agent a1 的组件a1.sources=r1a1.channels=c1a1.sinks=s1#描述/配置a1的source1a1.sources.r1.type=execa1.sources.r1.command=ping 192.168.234.163#描述sinka1.sinks.s1.type=logger#描述内存channela1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transactionCapacity=100#位channel 绑定 source和sinka1.sources.r1.channels=c1a1.sinks.s1.channel=c1
2.进入到bin目录执行指令:
./flume-ng agent --conf …/conf --conf-file …/conf/template-exec.conf --name a1-Dflume.root.logger=INFO,console
3.Spooling Directory类型的 Source
使用场景:
Spooling Directory Source可监听一个目录,同步目录中的新文件到sink,被同步完的文件可被立即删除或被打上标记。适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步。如果需要实时监听追加内容的文件,可对SpoolDirectorySource进行改进。
将指定的文件加入到“自动搜集”目录中。flume会持续监听这个目录,把文件当做source来处理。
注意:一旦文件被放到“自动收集”目录中后,便不能修改,如果修改,flume会报错。此外,也不能有重名的文件,如果有,flume也会报错。
Spooling Source可配置项说明
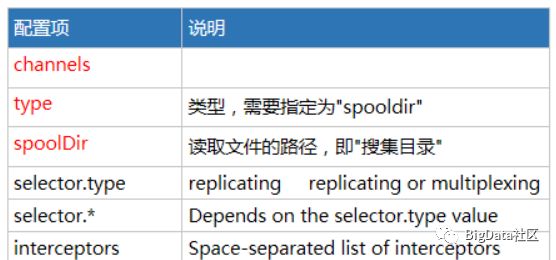
实现步骤:
1.配置示例:
#配置Agent a1 的组件a1.sources=r1a1.channels=c1a1.sinks=s1#描述/配置a1的source1a1.sources.r1.type=spooldira1.sources.r1.spoolDir=/home/work/data#描述sinka1.sinks.s1.type=logger#描述内存channela1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transactionCapacity=100#位channel 绑定 source和sinka1.sources.r1.channels=c1a1.sinks.s1.channel=c1
2.创建相关的文件夹
3.根据指定的配置文件,启动flume
4.向指定的文件目录下传送一个日志文件,发现flume的控制台打印相关的信息
此外,会发现被处理的文件,会追加一个后缀:completed,表示已处理完。
(重名文件包括已加后缀的文件)
4.NetCat Source
一个NetCat Source用来监听一个指定端口,并接收监听到的数据
NetCat Source可配置项说明
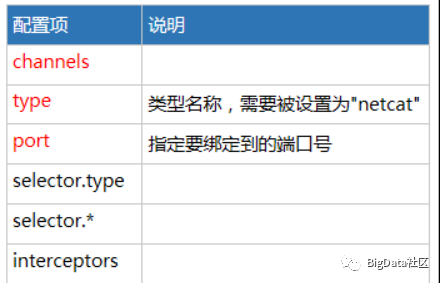
配置示例:
#配置Agent a1 的组件a1.sources=r1a1.channels=c1a1.sinks=s1#描述/配置a1的r1a1.sources.r1.type=netcata1.sources.r1.bind=0.0.0.0a1.sources.r1.port=44444#描述a1的s1a1.sinks.s1.type=logger#描述a1的c1a1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transactionCapacity=100#位channel 绑定 source和sinka1.sources.r1.channels=c1a1.sinks.s1.channel=c1
然后启动
5.Sequence Generator Source --序列发生源
一个简单的序列发生器,不断的产生事件,值是从0开始每次递增1。主要用来测试。
Seq Source可配置项说明
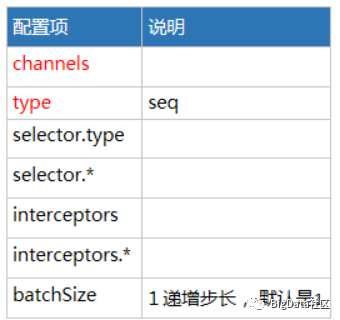
配置示例
#配置Agent a1 的组件a1.sources=r1a1.sinks=s1a1.channels=c1#描述/配置a1的source1a1.sources.r1.type=seq#描述sinka1.sinks.s1.type=logger#描述内存channela1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transactionCapacity=100#位channel 绑定 source和sinka1.sources.r1.channels=c1a1.sinks.s1.channel=c1
6.Taildir Source
使用场景:
Taildir Source可实时监控一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题。
使用时建议用1.8.0版本的flume,1.8.0版本中解决了Taildir Source一个可能会丢数据的bug。
agent配置:
# source的名字agent.sources = s1# channels的名字agent.channels = c1# sink的名字agent.sinks = r1# 指定source使用的channelagent.sources.s1.channels = c1# 指定sink使用的channelagent.sinks.r1.channel = c1######## source相关配置 ######### source类型agent.sources.s1.type = TAILDIR# 元数据位置agent.sources.s1.positionFile = Users/wangpei/tempData/flume/taildir_position.json# 监控的目录agent.sources.s1.filegroups = f1agent.sources.s1.filegroups.f1=/Users/wangpei/tempData/flume/data/.*logagent.sources.s1.fileHeader = true######## channel相关配置 ######### channel类型agent.channels.c1.type = file# 数据存放路径agent.channels.c1.dataDirs = Users/wangpei/tempData/flume/filechannle/dataDirs# 检查点路径agent.channels.c1.checkpointDir = Users/wangpei/tempData/flume/filechannle/checkpointDir# channel中最多缓存多少agent.channels.c1.capacity = 1000# channel一次最多吐给sink多少agent.channels.c1.transactionCapacity = 100######## sink相关配置 ######### sink类型agent.sinks.r1.type = org.apache.flume.sink.kafka.KafkaSink# brokers地址agent.sinks.r1.kafka.bootstrap.servers = localhost:9092# topicagent.sinks.r1.kafka.topic = testTopic3# 压缩agent.sinks.r1.kafka.producer.compression.type = snappy
记录每个文件消费位置的元数据
#配置agent.sources.s1.positionFile = Users/wangpei/tempData/flume/taildir_position.json#内容[{"inode":6028358,"pos":144,"file":"/Users/wangpei/tempData/flume/data/test.log"},{"inode":6028612,"pos":20,"file":"/Users/wangpei/tempData/flume/data/test_a.log"}]可以看到,在taildir_position.json文件中,通过json数组的方式,记录了每个文件最新的消费位置,每消费一次便去更新这个文件。
7.HTTP source
此Source接受HTTP的GET和POST请求作为Flume的事件。其中GET方式应该只用于试验。
如果想让flume正确解析Http协议信息,比如解析出请求头、请求体等信息,需要提供一个可插拔的"处理器"来将请求转换为事件对象,这个处理器必须实现HTTPSourceHandler接口。
这个处理器接受一个 HttpServletRequest对象,并返回一个Flume Envent对象集合。
flume提供了一些常用的Handler(处理器):
JSONHandler
可以处理JSON格式的数据,并支持UTF-8 UTF-16 UTF-32字符集
该handler接受Evnet数组,并根据请求头中指定的编码将其转换为Flume Event
如果没有指定编码,默认编码为UTF-8.
BlobHandler
BlobHandler是一种将请求中上传文件信息转化为event的处理器。
参数说明,加!为必须属性:
!handler – The FQCN of this class: org.apache.flume.sink.solr.morphline.BlobHandler
handler.maxBlobLength 100000000 The maximum number of bytes to read and buffer for a given request
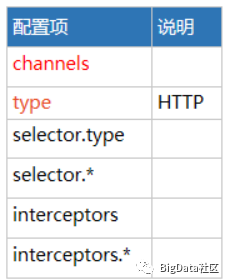
1.配置示例:
#配置Agent a1 的组件a1.sources=r1a1.sinks=s1a1.channels=c1#描述/配置a1的source1a1.sources.r1.type=httpa1.sources.r1.port=8888#描述sinka1.sinks.s1.type=logger#描述内存channela1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transactionCapacity=100#位channel 绑定 source和sinka1.sources.r1.channels=c1a1.sinks.s1.channel=c1
2.执行启动命令
3.执行curl 命令,模拟一次http的Post请求
curl -X POST -d ‘[{“headers”:{“a”:“a1”,“b”:“b1”},“body”:“hello http-flume”}]’ http://0.0.0.0:8890
注:这种格式是固定的,因为我们用的是flume自身提供的Json格式的Handler。此外,需要包含header 和body两关键字,这样,handler在解析时才能拿到对应的数据。
以上就是今天的所有内容啦。希望能在你学习的路上帮到你,要是觉得还不错请识别以下二维码关注或转发吧,感谢支持!

