




这一节谈谈MapReduce的工作原理,也是作为MapReduce学习阶段的汇总,还有数据本地化的一个过程。
map端流程
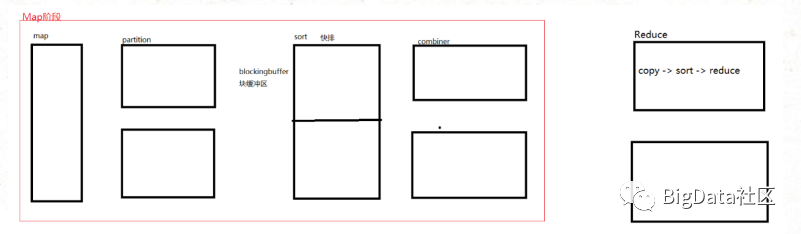
map---->partition(blockingbuffer块缓冲区)--->sort(快速排序) --->combiner --->shuffle --->
Reduce端过程
Reducer ---->copy ->sort ->Reducer
MR全流程
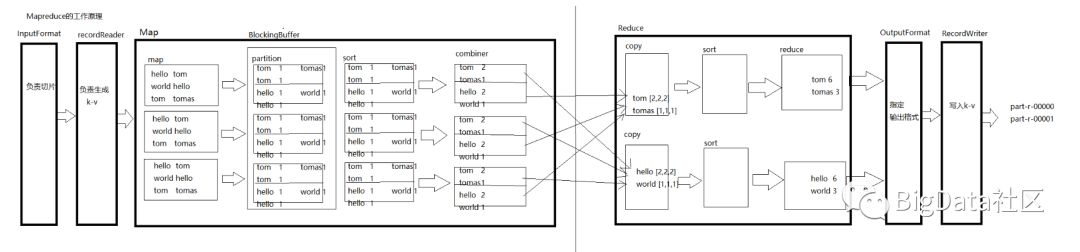
IntputFormat-->redcordReader-->map-->
partition-->sort-->combiner-->sopy-->sort-->reduce-->
OutputFormat-->redcordWriter
数据本地化过程图解
300M数据,MR逻辑切割(数据本地化过程)
数据本地化最重要的是文件必须可切割
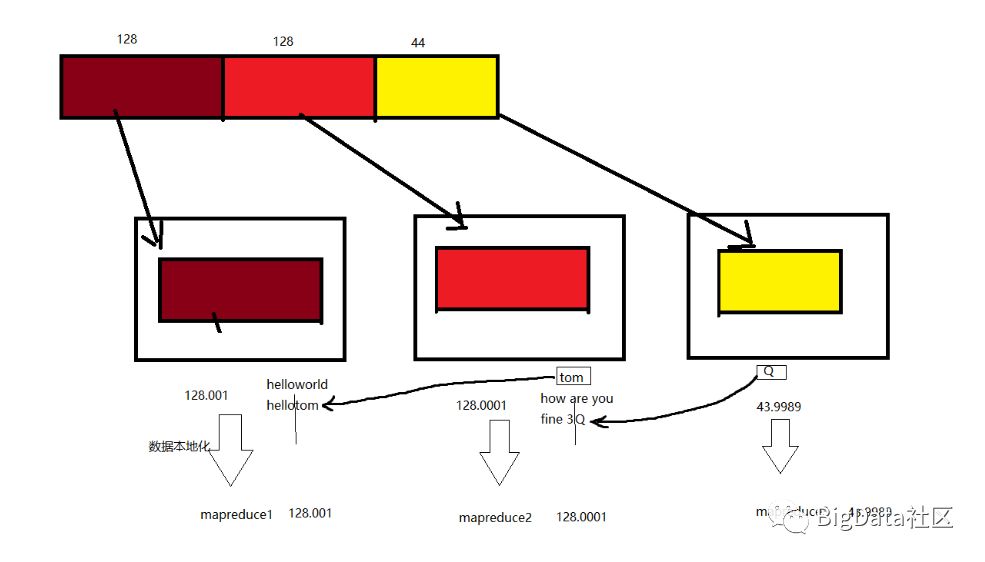
什么是数据本地化?
首先需要知道,hadoop数据本地化是指的map任务,reduce任务并不具备数据本地化特征。
通常输入的数据首先将会分片split,每个分片上构建一个map任务,由该任务执行执行用户自定义的map函数,从而处理分片中的每条记录。
那么切片的大小一般是趋向一个HDFS的block块的大小。为什么最佳的分片大小是趋向HDFS块的大小呢?是因为这样能够确保单节点上最大输入块的大小,如果分片跨越两个数据块,没有一个HDFS能够同时存储这两块数据,因此需要通过网络传输将部分数据传输到map任务节点上。这样明显比使用本地数据的map效率更低。
注意,map任务执行后的结果并没有写到HDFS中,而是作为中间结果存储到本地硬盘,那为什么没有存储到HDFS呢?因为,该中间结果会被reduce处理后产生最终结果后,该中间数据会被删除,如果存储到HDFS中,他会进行备份,这样明显没有意义。如果map将中间结果传输到reduce过程中出现了错误,Hadoop会在另一个节点上重新执行map产生中间结果。
那么为什么reduce没有数据本地化的特点呢?对于单个reduce任务来说,他的输入通常是所有mapper经过排序输出,这些输出通过网络传输到reduce节点,数据在reduce节点合并然后由reduce函数进行处理。最终结果输出到HDFS上。当多个有reduce任务的时候,map会针对输出进行分区partition,也就是为每个reduce构建一个分区,分区是由用户指定的partition函数,一般是默认的哈希函数进行分区,效率很高。
数据本地化好处:
1.防止数据倾斜
2.减少网络间传输
以上就是今天的所有内容啦。希望能在你学习的路上帮到你,要是觉得还不错请识别以下二维码关注或转发吧,感谢支持!

推荐阅读:
