




上一篇 《TiKV 源码解析系列文章(十四)Coprocessor 概览》讲到了 TiDB 为了最大化利用分布式计算能力,会尽量将 Selection 算子、聚合算子等算子下推到 TiKV 节点上。本文将继续介绍 Coprocessor 中表达式计算框架的源码架构,带大家看看 SQL 中的表达式是如何在 Coprocessor 中执行的。
什么是表达式
比如说我们用这个 SQL 作为例子:
SELECT (count * price) AS sum FROM orders WHERE order_id < 100
其中 order_id < 10
就是一个表达式,它有一个列输入参数: order_id
,输出:Bool
。
RPN 表达式
2 *(3 + 4)+ 5:
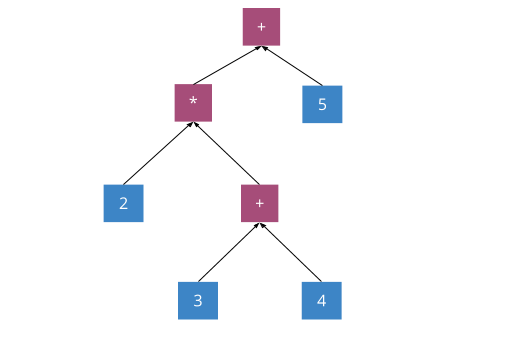
RPN:2 3 4 + * 5 +,这样我们无需括号就能无歧义地遍历这个表达式:
2 3 4 + * 5 +,我们从左到右遍历表达式,遇到值就压入栈中。直到
+操作符,栈中已经压入了
2 3 4。

+是二元操作符,需要从栈中弹出两个值
3 4,结果为
7,重新压入栈中:
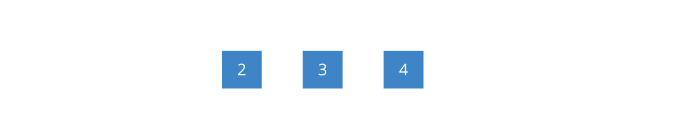

2 7。

*运算符,也需要弹出两个值
2 7,结果为
14压入栈中。

5。
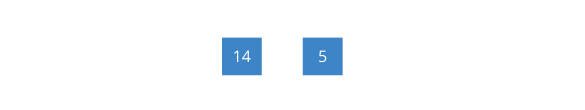
+运算符弹出
14 5,结果为
19,压入栈。

构建 RPN 表达式
order_id < 10下推为例,其下推的树状表达式如下图所示,其中
ColumnRef(2)表示列
order_id,
2表示
order_id列在该表结构中对应的 offset:


/// An expression in Reverse Polish notation, which is simply a list of RPN expression nodes.
///
/// You may want to build it using `RpnExpressionBuilder`.
#[derive(Debug, Clone)]
pub struct RpnExpression(Vec<RpnExpressionNode>);
/// A type for each node in the RPN expression list.
#[derive(Debug, Clone)]
pub enum RpnExpressionNode {
Represents a function call.
FnCall {
func_meta: RpnFnMeta,
args_len: usize,
field_type: FieldType,
implicit_args: Vec<ScalarValue>,
},
Represents a scalar constant value.
Constant {
value: ScalarValue,
field_type: FieldType,
},
Represents a reference to a column in the columns specified in evaluation.
ColumnRef { offset: usize },
}
执行 RPN 表达式
RpnExpressionNode::FnCall)不会被存入栈,我们定义了只包含值的
RpnStackNode储存中间值:
// A type for each node in the RPN evaluation stack. It can be one of a scalar value node or a
/// vector value node. The vector value node can be either an owned vector value or a reference.
#[derive(Debug)]
pub enum RpnStackNode<'a> {
Represents a scalar value. Comes from a constant node in expression list.
Scalar {
value: &'a ScalarValue,
field_type: &'a FieldType,
},
Represents a vector value. Comes from a column reference or evaluated result.
Vector {
value: RpnStackNodeVectorValue<'a>,
field_type: &'a FieldType,
},
}
op([]value, []value)而不是
op(value, value),从而减少分支并提高 Cache Locality。但运算数并不总是一个来自列的向量,还可能是用户直接指定的常量(例如
SELECT a+1中
a是向量,但
1只是标量)。因此,
RpnStackNode分两种:
标量:由 Constant
生成。向量:执行 ColumnRe f
生成,或是FnCall
调用返回的结果。
/// Represents a vector value node in the RPN stack.
///
/// It can be either an owned node or a reference node.
///
/// When node comes from a column reference, it is a reference node (both value and field_type
/// are references).
///
/// When nodes comes from an evaluated result, it is an owned node.
#[derive(Debug)]
pub enum RpnStackNodeVectorValue<'a> {
Generated {
physical_value: VectorValue,
logical_rows: Arc<[usize]>,
},
Ref {
physical_value: &'a VectorValue,
logical_rows: &'a [usize],
},
}
order_id < 100作为例子看看表达式是如何执行的。

ColumnRef,我们取出输入 Selection 算子的数据中对应 offset 的列的向量数据,并将向量压入栈:

Constant,转化为标量然后压入栈:
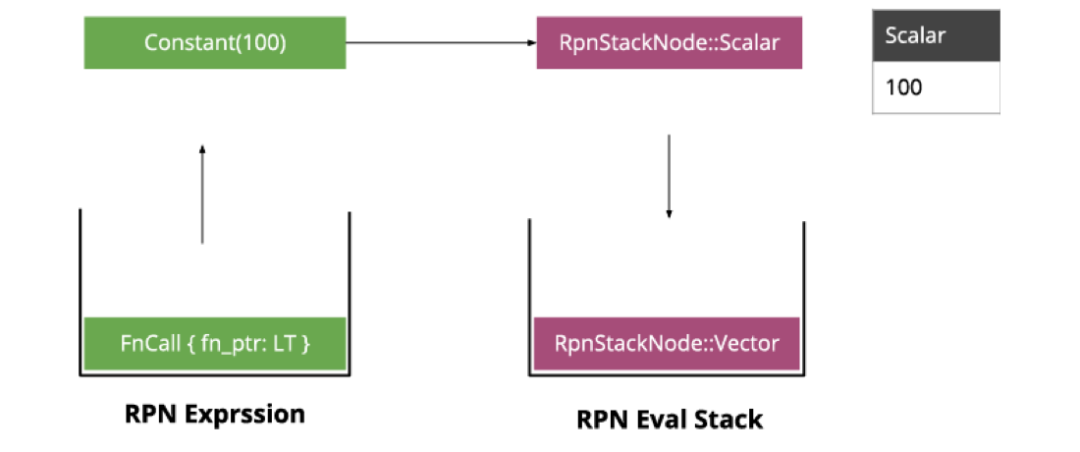
LT运算符,它需要两个入参,因此我们从栈中弹出两个值作为参数调用
LT,
LT会生成一个新的向量,将结果压入栈:
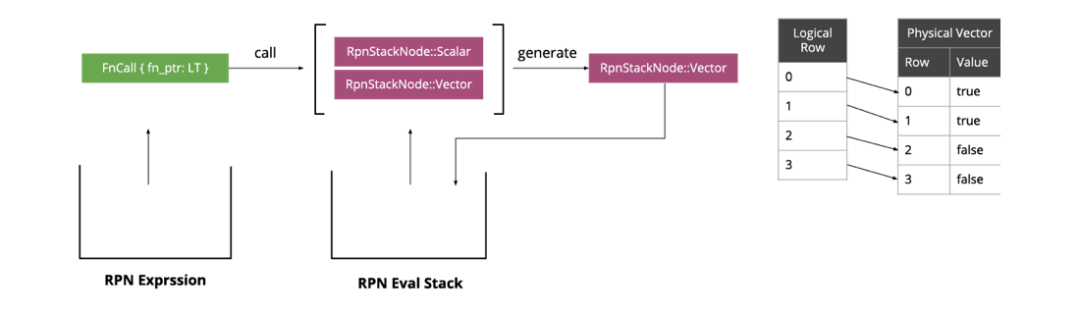


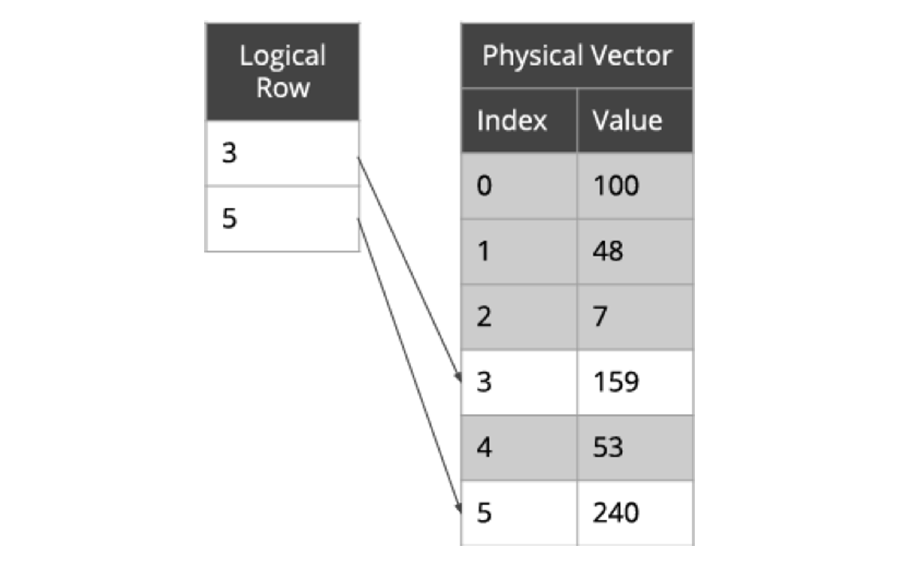
实现 RPN 表达式函数
FnCall)是比较繁琐的。比如对于二元操作符加法, 它既可以接受其中一元输入常量,也可以接受来自列数据的向量。一种解决方法是将标量都重复填充为向量,这样所有函数运算都是向量参数,但这个方法会有额外的标量拷贝开销。为了避免这个开销,Coprocessor 直接实现了向量与标量的运算,
rpn_expr_codegen提供了过程宏
#[rpn_fn],我们只需定义标量逻辑,过程宏将自动生成剩下带有向量的逻辑。
#[rpn_fn]
#[inline]
pub fn int_plus_int(
lhs: &Option<Int>,
rhs: &Option<Int>,
) -> Result<Option<Int>> {
if let (Some(lhs), Some(rhs)) = (arg0, arg1) {
lhs.checked_add(*rhs)
.ok_or_else(|| Error::overflow("BIGINT", &format!("({} + {})", lhs, rhs)).into())
.map(Some)
} else {
Ok(None)
}
}
#[rpn_fn]宏会分析这个操作符定义的参数数量和类型,自动生成既可以处理标量也可以处理向量的
int_plus_int_fn_meta(),这个函数将可以放进
FnCall被用于表达式计算:
pub fn int_plus_int_fn_meta(
_ctx: &mut EvalContext,
output_rows: usize,
args: &[RpnStackNode<'_>],
_extra: &mut RpnFnCallExtra<'_>,
) -> Result<VectorValue>
{
assert!(args.len() >= 2);
let lhs = args[0];
let rhs = args[1];
let mut result: Vec<Int> = Vec::with_capacity(output_rows);
match lhs {
RpnStackNode::Scalar { value: ScalarValue::Int(lhs) , .. } => {
match rhs {
RpnStackNode::Scalar { value: ScalarValue::Int(rhs) , .. } => {
let value = int_plus_int(lhs, rhs);
result.push(result);
}
RpnStackNode::Vector { value: VectorValue::Int(rhs_vector) , .. } => {
for rhs_row in rhs_vector.logical_rows() {
let rhs = rhs_vector.physical_value[rhs_row];
let value = int_plus_int(lhs, rhs);
result.push(result);
}
}
_ => panic!("invalid expression")
}
}
RpnStackNode::Vector { value: VectorValue::Int(lhs_vector) , .. } => {
match rhs {
RpnStackNode::Scalar { value: ScalarValue::Int(rhs) , .. } => {
for lhs in lhs_vector {
let value = int_plus_int(lhs, rhs);
result.push(result);
}
}
RpnStackNode::Vector { value: VectorValue::Int(rhs_vector) , .. } => {
for (lhs, rhs) in lhs_vector.logical_rows().iter().zip(rhs_vector.logical_rows()) {
let lhs = lhs_vector.physical_value[lhs_row];
let rhs = rhs_vector.physical_value[rhs_row];
let value = int_plus_int(lhs, rhs);
result.push(result);
}
}
_ => panic!("invalid expression")
}
}
_ => panic!("invalid expression")
}
result
}
小结
💡文中划线部分均有跳转,点击【阅读原文】查看原版文章
TiKV 源码解析系列文章
TiKV 是一个开源的分布式事务 Key-Value 数据库,支持跨行 ACID 事务,同时实现了自动水平伸缩、数据强一致性、跨数据中心高可用和云原生等重要特性。作为一个基础组件,TiKV 可作为构建其它系统的基石。目前,TiKV 已用于支持分布式 HTAP 数据库—— TiDB 中,负责存储数据,并已被多个行业的领先企业应用在实际生产环境。2019 年 5 月,CNCF 的 TOC(技术监督委员会)投票决定接受 TiKV 晋级为孵化项目。
· 源码地址:https://github.com/tikv/tikv
· 更多信息:https://tikv.org

最后修改时间:2019-11-19 09:21:42
文章转载自PingCAP,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
