




这是VDL系列的第二篇,本文主要讲述VDL的实现细节与高性能手段。虽然本文是围绕VDL进行阐述的,但阐述的诸多思想、问题、解决方案等,都与分布式系统有关,与存储有关。希望通过本文,让大家对VDL有更深入的了解,也对分布式系统的技术与本质有一定的了解。
VDL特性回顾

我们首先来回顾一下VDL特性,主要集中在高可用、高可靠,数据一致性、读写一致性与高性能,具体是:
-高可用性: VDL集群能在少部分节点异常情况下持续提供服务,公式为F=(N-1)/2;F为异常节点容忍数,N为部署的节点数。如N=3时,可以容忍1个节点异常,N=5时,可以容忍2个节点异常。
-数据可靠性:VDL使用多副本+实时刷盘机制保存数据,保证只要成功响应客户端的数据,不会因为数据同步、主从切换等原因,导致数据丢失。
-读写一致性:VDL提供线性一致性读,保证每次读到的数据是最新的,并且是已经commit(响应客户端)的数据。
-高性能:VDL使用多种技术手段,分别对存储模型、磁盘IO、主从同步链路等做了优化,提供高吞吐、低延时的分布式存储系统。这部分会在后面进行介绍。
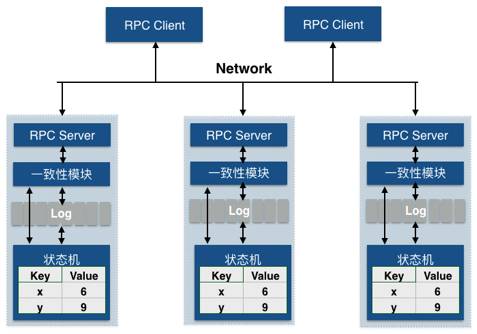
-多副本数据一致性: VDL使用Raft一致性算法,保证每个副本数据一致性。
那这些特性,在VDL是如何实现的呢?我们现在逐一介绍。
VDL的高可用与数据一致性
本章节主要讲述分布式系统的一些关键问题,我们不准备在这里介绍Raft算法的详细内容,有兴趣的同学可以翻翻Raft算法论文。Leader选举与切换时数据一致性
Raft是一个Leader-Based的算法,所以VDL也是一个Leader-Based的分布式系统。Leader-Based系统的高可用与Leader选举有关,Leader选举通常夹杂着数据一致性算法,所以这里一并介绍 。
我们以使用ZK选主的分布式系统为例,讨论一下选主的关键问题。
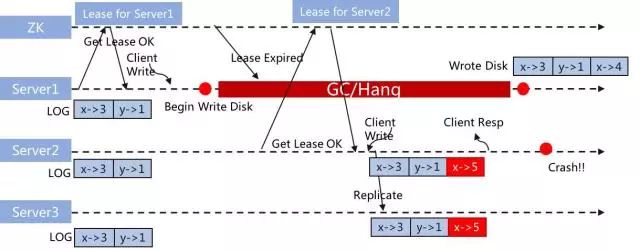
(注:X轴是时间维度)
如上图所示,Server1-3使用锁+租约(Lease)方式选主。Server1在Leader状态,由于GC/磁盘IO调用Hang住(这里有很多因素,如线上出现过的Raid阵列卡放电问题等等),导致Server1在写入数据时,Server2已经成为Leader,并且写入数据,而随后Server1的数据也正常写入。这个时候,就出现图中的状态,Server1写入了"x->4",而Server2写入了"x->5",而此时Server2 Crash了。现在有两个问题:
(1)现在选谁为Leader?
(2)如何保证数据一致性?
显然在现有的条件下,是无法得到正确答案的。第一问题,谁拿到锁谁就为Leader,具有一定随机性;第二个问题,现有数据条件下,无法判断哪个数据是正确的。
VDL使用的是Raft算法,下面简单分析一下此算法是如何处理这个问题的。
在分布式领域,逻辑时钟(Logical Clock)是解决分布式时序问题的关键。ZAB、Paxos中叫Epoch,Raft叫Term。
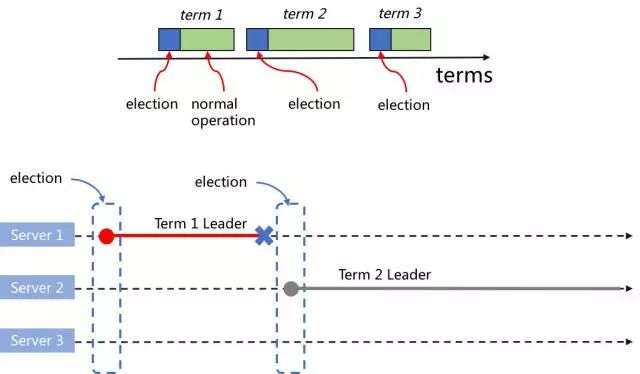
如上图所示,每个Leader是由选举产生,其任期是Term,在Raft算法中,Term是一个不断自增的自然数。
我们再回到刚刚的例子:
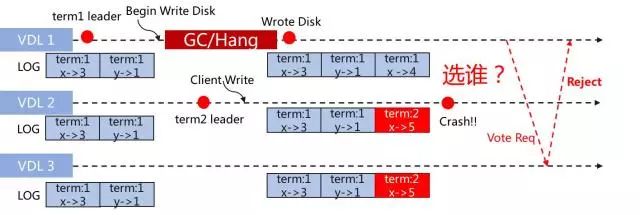
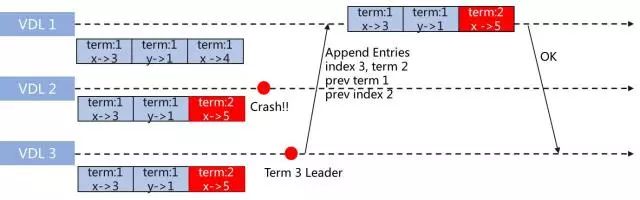
如上图所示,每条数据存储时,都带上Term。那么在选举时,选举算法会考虑节点的日志情况。按此例子,Server3必然会选为Leader,简单理解是因为Server3的Term比Server1的大。在Server3选为Leader后,会在复制时,根据复制算法,比较相同位置的数据是否一致,此例子中,第三条数据,Server1是"x->4",Server3是"x->5",显然不一致,而Server3的Term较大,则Server1的数据会被替换成"x->5",保证数据的一致性,如下图所示:
网络分区的处理
在VDL的每个节点,我们添加了一个Lease:
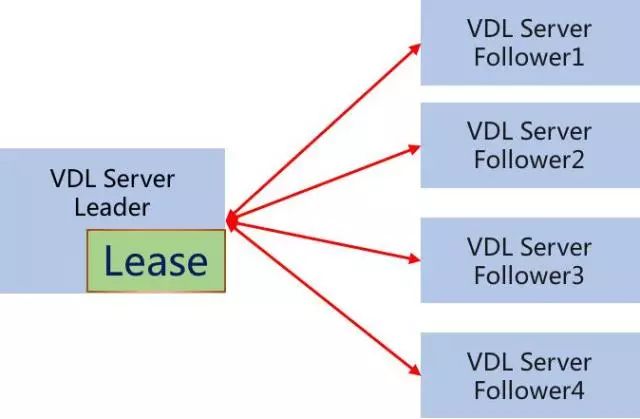
如上图所示,Leader的Lease用于自动降级为Follower:在Lease定义的时间内,若Leader判断当前没有多数派节点存活,则自动降为Follower。
Lease并不是万能的,Lease主要用于避免系统长期存在多主的情况,但系统还是有可能出现多主,比如Leader由于系统调用/GC/CPU/内存等原因Hang住,Lease降级不及时,而新主又被选举出来。(这也是分布式系统复杂的原因)
对于出现网络分区时,VDL是这样处理的:
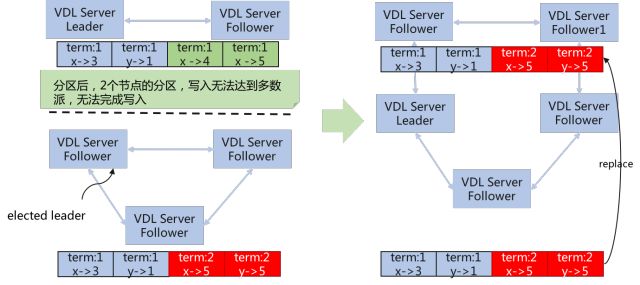
如上图所示,在集群写入"term:1,x->4"与"term:1,x->5"时,出现网络分区,这两个数据在上面两个节点写入成功,但由于没有写入多数派,这写入请求不会得到响应。在一段时间后,下面三台节点选出Leader,新的请求会路由到新Leader,新Leader能达到多数派从而写入成功。
在网络恢复后,根据Raft算法,会被"term:1,x->4"与"term:1,x->5"替换为"term:2,x->5"与"term:2,y->5",达到数据一致性。
而如果旧Leader由于一些原因被Hang住,导致新Leader被选出后旧Leader还没降为Follower,则写入旧Leader的数据一直得不到响应,直到Lease将旧Leader降为Follower(Lease主要用于避免系统长期存在多主的情况)。
VDL的数据可靠性
简单地说,就是如何保证数据不丢失。VDL的数据不丢失是由 多数派 + 同步刷盘保证的。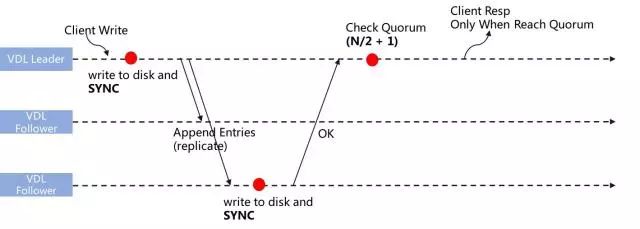
如图所示,VDL在写入数据时,成功响应客户端的只有一种情况:多数派节点写入成功,节点写入成功的定义是已同步刷盘。VDL允许少数节点出现数据不可恢复异常。
VDL的读写一致性
VDL提供的一致性是:线性一致性(也称强一致性),是目前工程能实现的最高一致性级别,保证每次读都能读到最新已提交的数据。线性一致性的保障,VDL需要做到三点,缺一不可: -读写的顺序:受Kafka客户端的制约,只能从Leader读写,读写顺序问题就变得比较简单了。
-Read Commit:从本文上面的一些例子可以看出,VDL节点里存储的数据,有一些可能是赃数据,要被替换的,有一些可能是正在同步复制但未ACK客户端的数据。VDL需要保证只有ACK客户端的数据,才能让读可见。如下图所示:
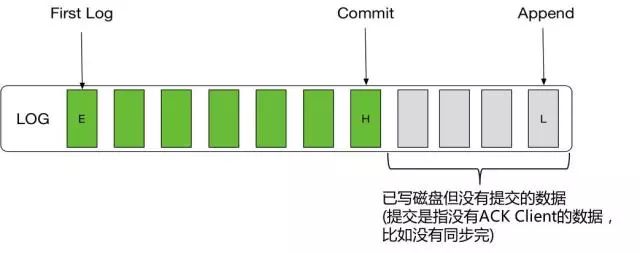
可见区间为E-H。
-Leader切换时可见性:这个在其它文章可能比较少提及,也是读写一致性的一个关键点。
在某一时刻,VDL可能会存在下面这种情况:
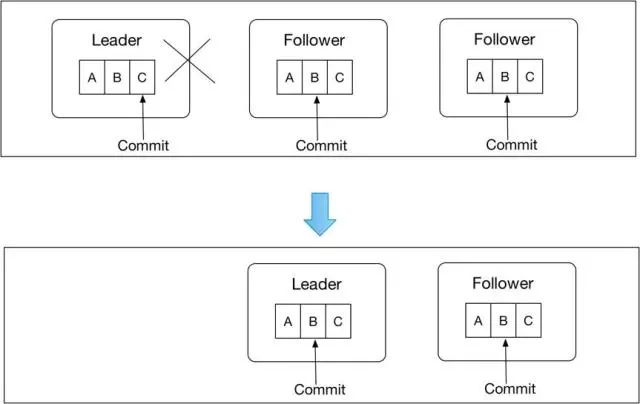
如上图,在Leader切换前,C是可见的,但在Leader切换后,C是不可见的,这里出现幻读。但在Raft算法中,C的Commit,必须在新Leader所在的Term成功提交一个Log,才能Commit。
在VDL里面,幻读这种现象是不允许的,所以需要特殊的手段进行处理:在Leader切换后,新的Leader需要Append No-Op Log,并让其Commit之后,才能对外提供服务。
VDL的性能优化解密
接下来,我们解密一下VDL在性能上做的优化。VDL复制流程优化
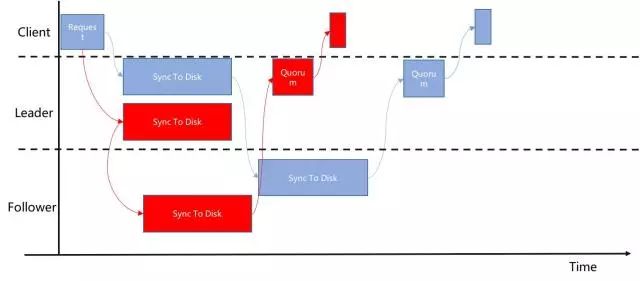
如图中蓝色所示,很多分布式系统,例如开了半同步的MySQL,一般都是Leader先写本地磁盘,然后复制到Follower,Follower落盘后,响应Leader,Leader完成复制,并响应客户端。假设写盘的Latency为L(IO),网络为L(rtt),则完成一次写入,理论上最少需要 L(总体) =L(IO) + L(IO) + L(rtt)。
VDL对此复制流程进行优化,如图中红色所示,Leader的写盘与Follower的同步改为并行流程,由上图所示,则完成一次写入,理论上最少需要 L(总体) = L(IO) + L(rtt)。减少了一个磁盘IO时间。
IO读写分离模型
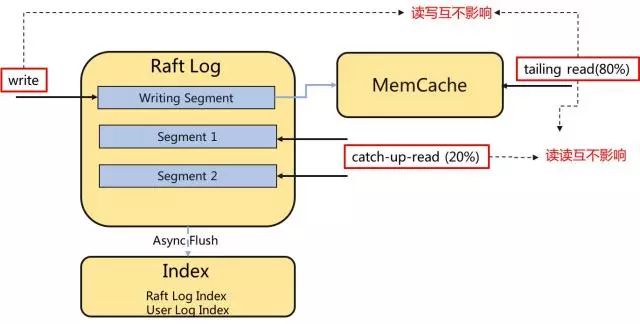
我们把客户端的操作,分为三部分:
1.写入:顺序写入Raft Log文件,产生顺序写入IO。
2.Tailing Read:在尾端消费,正常情况下,80%的读取操作应该由Tailing Read完成。
3.Catchup Read:从中间消费,单客户端会产生顺序读IO,多客户端Catchup Read会产生随机读IO。
我们希望在正常的情况下,读(Tailing Read)与写互不影响,写是顺序写入磁盘,而读则直接命令内存。我们为Tailing Read专门维护了一段内存,而不依赖于Page Cache,避免系统在极端情况下的页置换对VDL带来较大影响,保证极端情况下这80%的Tailing Read能正常运行。
另外,在读读的情况下,VDL也是互不影响的。Tailing Read命中内存,而Catchup Read则从文件中读取。
在写与频繁地Catchup Read,在使用机械磁盘的情况下,性能波动会比较大。解决这种情况可以有:1) 使用SSD 2) 或者将冷热数据分磁盘存储,减少读写的IO冲突。
Log合并
正常情况下,Raft Log与用户数据是两种数据,那么一次写入,就需要写两份数据,两次IO。
VDL在设计时,把Raft Log与用户数据合并,这样只需一份数据与一次IO就完成数据的写入。
同样Index数据也一样,将Raft Log的Index与用户数据的Index合并。
Batch + Pipeline
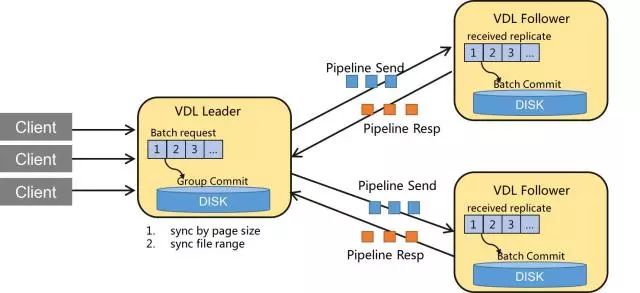
-Batch: 是存储类系统中最常见的技术手段,最直观的理解就是将多个数据打包在一起,将整个数据处理流程中最耗时的环节均摊在多个消息上。VDL中的Batch,包括请求处理层的Batch与写磁盘的Batch。
-Pipeline: Pipeline是并发编程中常见的一种设计思路,直观看起来就是: 一个任务发起者,在上一个任务尚未完成前,可以继续发起下一个任务。VDL中,Client与Leader、Leader与Follower都是Pipeline方式处理的。
Overlapped File I/O Model
VDL在写盘上,同样做了优化。物理存储设备, 无论是SATA/SAS还是SSD盘,其IOPS都是有限的,而通常我们主流存储设备的带宽是足够的,所以很多时候我们要解决的问题其实是:用相同的IOPS,实现更高的IO吞吐的能力。
LogStore是VDL的核心部分,也是我们完全自主实现的存储引擎,其中的文件IO处理,我们采用Memory Mapped File + overlapped sync_file_range的方式,经过测试是我们主流存储机型上最理想的IO模型。另外一点就是为了避免刷盘时刷文件元数据的开销,VDL的Log文件使用的是预分配的方式,这样我们可以通过sync_file_range来刷盘,而不更新元数据。
性能部分小结
VDL使用数据复制链路优化、分离存储模型、Batch + Pipeline、Overlapped File I/O Model等方式,将VDL打造成高吞吐、低延时的分布式日志存储系统。 在binlog灰度环境,在追存量数据场景,单queue性能在130k/tps,latency在35ms左右,平时(增量场景)是10k/tps, latency在1-2ms。
(灰度环境:Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz * 24, 600G SAS,32G内存,千兆网)
在单线程同步发送的压测场景,使用相同的硬件环境,相同的客户端:
(1)VDL的单写场景性能是Kafka的130-140%
(2)VDL的单读场景性能是Kafka的106-111%;
(3)在读写混合场景下,VDL写性能是Kafka的133-152%,读性能是Kafka的108-109%。
本文总结
本文介绍内容大概分为两大点: -围绕分布式系统的关键问题,对VDL的实现细节进行剖析:
(1) Leader如何切换;
(2) 切换时如何保证数据一致性;
(3)网络分区如何处理;
(4) 如何保证数据不丢;
(5) 读写线性一致性的关键。
- 围绕如何达到高性能,对VDL的设计与优化进行剖析:
(1)优化主从复制链路;
(2) 读写分离模型;
(3) Log合并;
(4) Batch && Pipeline;
(5)Overlapped File I/O Model。
我们还在持续优化VDL,在技术上,我们思考的问题包括:Follower读与Follower一致性读;数据冷热分离存储;在产品形态上,我们思考包括 MQ方向、Binlog方向、K/V方向等。
下一篇预告
分布式系统,在正常的情况下,还是比较简单的。异常情况才是分布式系统的难点,包括节点异常,磁盘IO异常,网络延时/丢包、网络分区等等。下一篇文章我们将介绍VDL是如何在这些异常、或者异常组合的情况下,保证VDL稳定正常。
推荐阅读
VDL:唯品会强一致、高可用、高性能分布式日志存储介绍(产品篇)

唯品会大数据平台优化

唯品会双十一大促技术保障实践
“唯技术”一档专为唯品技术人发声的公众号
欢迎投稿!!
只要是技术相关的文章尽管砸过来!

