





这是本博客系列的第2部分。您可以在此处阅读第1部分:数字化转型是从边缘到洞察力的数据之旅
该博客系列跟踪了互联汽车制造商的制造、运营和销售数据,这些数据经历了大型制造公司在当前技术领先水平上通常经历的阶段和转换。第一个博客介绍了一个模拟互联汽车制造公司,即电动汽车公司(ECC),以说明贯穿数据生命周期的制造数据路径。为此,ECC利用Cloudera数据平台(CDP)来预测事件,并在全球范围的工厂中自上而下地查看汽车的制造过程。
在上一个博客中完成了“数据收集”步骤之后,ECC在数据生命周期中的下一步就是“数据丰富化”。ECC将丰富收集到的数据,并将在以后的数据生命周期中将其用于分析和模型创建。以下是数据生命周期中的所有步骤,并且生命周期中的每个步骤都将由专门的博客文章支持(见图1):
数据收集 –边缘处的数据摄取和监控(边缘是工业传感器还是车辆陈列室中的人员)
数据丰富–数据管道处理、聚合和管理,以准备数据进行进一步分析
报告–提供业务洞察力(销售分析和预测、预算编制为例)
服务–控制和运行基本业务操作 (经销商操作、生产监控)
预测分析–基于AI和机器学习的预测分析(预测维护,基于需求的库存优化为例)
安全与治理–在整个数据生命周期中的一组集成的安全,管理和治理技术
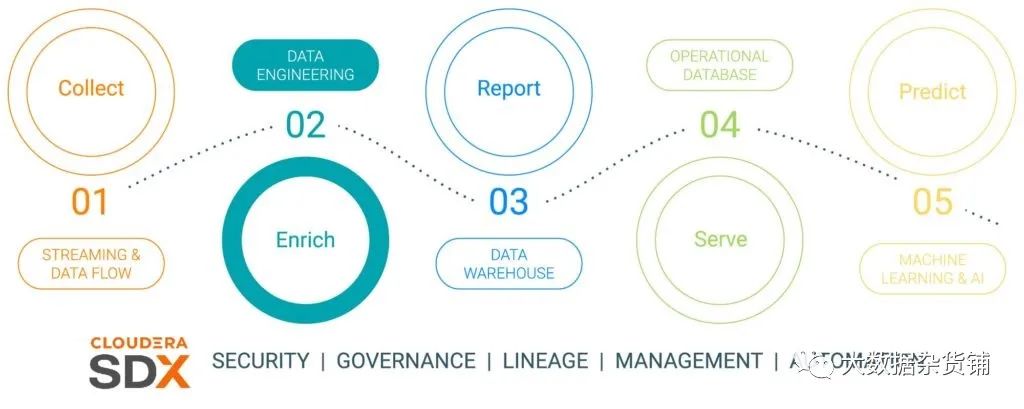
图1企业数据生命周期
数据丰富的挑战
ECC需要对与制造、经销商运营和车辆运输有关的所有数据有一个全面的了解和深入了解。他们还需要快速识别数据问题,例如操作传感器分离出数据,其中可能包括由于计划外的机器停机或突然启动而导致的虚假温度峰值。例如,在分析过程中不应考虑与维护人员在进行例行检查时从酸洗池中卸下传感器时与过程无关的数据。
此外,ECC面临以下数据挑战,要成功地通过其供应链转移电动机制造,就必须解决这些挑战。这些数据挑战包括:
从不同来源检索各种格式的数据:数据工程管道要求从各种来源以许多不同的格式引入数据。无论数据是来自生产线上的传感器,支持制造操作的传感器,还是控制供应链的ERP数据,都必须将它们汇总在一起以进行进一步分析。
过滤掉冗余或不相关的数据:删除重复或无效数据,并确保剩余数据的准确性,是准备将数据进一步用于高级预测分析的关键步骤。
识别效率低下的流程的能力:ECC要求能够查看哪些数据流程占用了最多的时间和资源,从而可以轻松地针对性能不佳的部分进行定位,从而加快整个流程。
能够从单个窗格监视所有流程:ECC需要一个集中式系统,该系统允许他们监视所有正在进行的数据流程,以及在保持透明度的同时扩展其当前基础结构的途径。
精心策划的高质量数据集是任何高级分析计划的骨干。为此,必须使用数据工程框架来建立在数据生命周期中移动、操纵和管理不同车辆部件的数据所需的所有管道和管道。
使用Cloudera数据工程构建管道
丰富和讨论数据之前,我们在第一个博客中将从工厂收集的IT和OT数据流进行清理、操作和修改。可以从印在电动机上的QR码捕获工厂ID,机器ID,时间戳,零件号和序列号。当电动机组装到连接的车辆中时,将捕获诸如模型类型,VIN和基本车辆成本之类的数据。
售出车辆后,将分别记录销售信息,例如客户名称、联系信息、最终销售价格和客户位置。此数据对于联系客户进行任何潜在的召回或有针对性的预防性维护至关重要。还存储了地理位置数据,这将有助于将客户位置映射到纬度和经度,以更好地了解这些电机在汽车中出售后的位置。
ECC将使用Cloudera数据工程(CDE)来解决上述数据挑战(见图2)。然后,CDE会将数据提供给Cloudera Data Warehouse(CDW),在此处将其提供给高级分析和商业智能报告。CDE步骤概述如下。
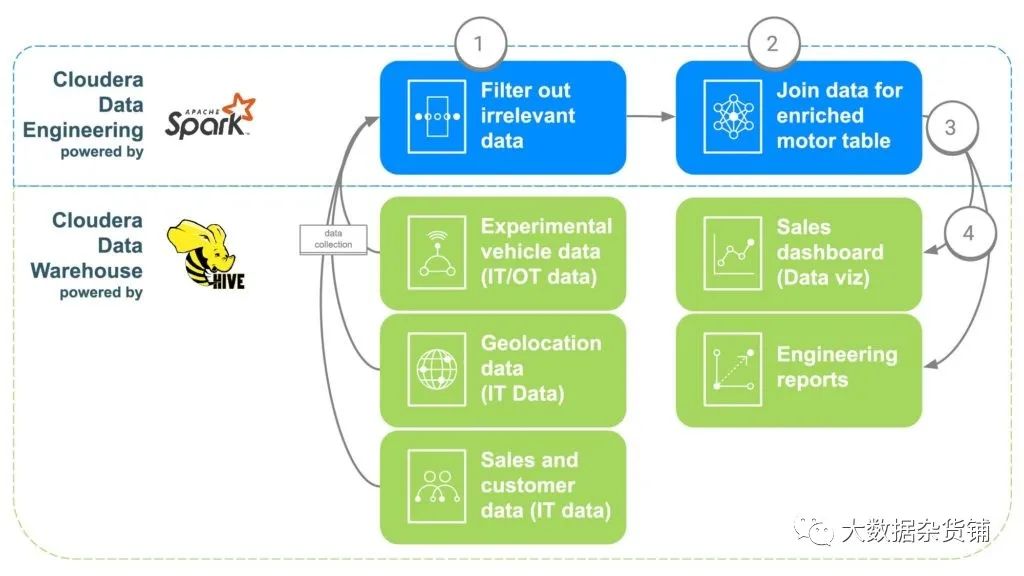
图2 ECC数据丰富管道
步骤1:过滤和分离数据
使用CDE的第一步是创建一个PySpark作业,该作业将从步骤1的各种“原始”数据中获取数据。这是一个机会,可以过滤掉任何不相关的数据,例如16岁以下的客户,因为16岁通常是最低驾驶年龄。重复的数据和其他不相关的数据也可以被过滤或分离出来。
步骤2:合并数据
为了合并所有数据,CDE会将公共链接关联在一起。首先,将汽车销售数据绑定到购买汽车的客户中,以获取客户元数据,例如联系信息、年龄、薪水等。然后,将使用地理位置数据来为客户获取更精确的位置信息,这将有助于以后映射电动机。零件安装数据将用于识别客户汽车中安装的每个电动机的序列号。最后,工厂数据将对齐以匹配电动机的序列号,该序列号将标识哪个工厂、机器以及何时创建每个特定的电动机。
步骤3:将数据发送到Cloudera数据仓库
一旦将所有数据汇总到一个扩展表中,一个简单的Apache Spark命令便会将数据写入Cloudera Data Warehouse中的新表中。这将使任何想要访问数据以进行其他分析的数据科学家都可以访问该数据。
步骤4:生成数据可视化仪表板和报告
将数据全部集中在一个地方,现在就可以创建报告,使员工可以做出更明智的决策,并开放不存在的功能。可以制作热图来跟踪电动机的位置,并将任何问题与潜在的地理位置相关联,例如由于极冷或高温导致的故障。如果某个工厂在某个时间范围内出现问题,此数据还可以用来精确跟踪可能影响哪些客户,从而轻松地跟踪可能需要召回或进行预防性维护的客户。
结论
Cloudera Data Engineering使ECC能够建立可与制造和零件数据,客户使用类型,环境条件,销售信息等相关的管道,以提高客户满意度和车辆可靠性。ECC通过跟踪与电机制造相关的数据并通过以下方式受益,从而实现了其目标并解决了其挑战:
ECC通过编排和自动化数据管道来快速实现价值,以从各种数据源安全透明地交付精选的高质量数据集。
ECC能够识别相关数据并过滤掉任何冗余和重复的数据。
ECC能够从一个窗格中实现数据管道监控,同时能够通过可视化故障排除被提醒尽早发现问题,从而在业务受到影响之前快速解决问题。
下一个博客将深入研究Reporting,该博客将展示ECC工程师如何针对这些选定的数据在CDW中运行临时查询,以及如何将数据与企业数据仓库中的其他相关源结合起来。CDW有助于将所有数据整合在一起,并提供了一个内置的数据可视化工具,可将查询结果转换为仪表板。请继续关注下一个!
更多资源
要查看所有这些操作,请单击下面的相关链接以了解更多数据丰富信息:
视频 –如果您想查看和了解其构建方式,请参阅链接中的视频。
教程–如果您希望按照自己的节奏进行操作,请查看详细的演练,其中包括屏幕截图和逐行说明,以了解如何进行设置和执行。
聚会-如果你想与专家Cloudera的直接对话,请加入虚拟聚会看现场直播演示。最后会有时间进行直接问答。
用户–要查看特定于用户的更多技术内容,请单击链接。
原文作者:Tui Leauanae
原文链接:https://blog.cloudera.com/next-stop-building-a-data-pipeline-from-edge-to-insight/
