





在本期中,我们将讨论如何执行“获取/扫描”操作以及如何使用PySpark SQL。之后,我们将讨论批量操作,然后再讨论一些故障排除错误。在这里阅读第一个博客。
Get/Scan操作
使用目录
在此示例中,让我们加载在第1部分的“放置操作”中创建的表“ tblEmployee”。我使用相同的目录来加载该表。
from pyspark.sql import SparkSessionspark = SparkSession \.builder \.appName("SampleApplication") \.getOrCreate()tableCatalog = ''.join("""{"table":{"namespace":"default", "name":"tblEmployee", "tableCoder":"PrimitiveType"},"rowkey":"key","columns":{"key":{"cf":"rowkey", "col":"key", "type":"int"},"empId":{"cf":"personal","col":"empId","type":"string"},"empName":{"cf":"personal", "col":"empName", "type":"string"},"empState":{"cf":"personal", "col":"empState", "type":"string"}}}""".split())table = spark.read.format("org.apache.hadoop.hbase.spark") \.options(catalog=tableCatalog) \.option("hbase.spark.use.hbasecontext", False) \.load()table.show()
执行table.show()将为您提供:

此外,您可以编辑目录,在其中可以省略一些不需要的列。例如,如果只需要“ tblEmployee”表的“ key”和“ empName”列,则可以在下面创建目录。如果您用上面的示例替换上面示例中的目录,table.show()将显示仅包含这两列的PySpark Dataframe。
tableCatalog = ''.join("""{"table":{"namespace":"default", "name":"tblEmployee", "tableCoder":"PrimitiveType"},"rowkey":"key","columns":{"key":{"cf":"rowkey", "col":"key", "type":"int"},"empName":{"cf":"personal", "col":"empName", "type":"string"}}}""".split())
执行table.show()将为您提供:

您可以对目录本身进行有限的过滤,执行获取和扫描操作的最佳方法是通过PySpark SQL,这将在后面讨论。
使用hbase.columns.mapping
同样,我们可以使用hbase.columns.mapping将HBase表加载到PySpark数据帧中。让我们尝试使用此方法加载“ tblEmployee”
从pyspark.sql导入SparkSession
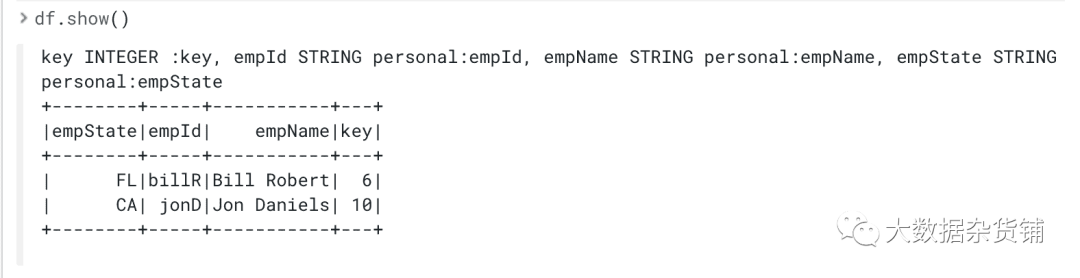
spark = SparkSession \.builder \.appName("SampleApplication") \.getOrCreate()df = spark.read.format("org.apache.hadoop.hbase.spark") \.option("hbase.columns.mapping","key INTEGER :key, empId STRING personal:empId, empName STRING personal:empName, empWeight FLOAT personal:empWeight") \.option("hbase.table", "tblEmployee") \.option("hbase.spark.use.hbasecontext", False) \.load()df.show()
执行df.show()将为您提供:
使用PySpark的Spark SQL
使用PySpark SQL是在Python中执行HBase读取操作的最简单、最佳方法。使用PySpark SQL,可以创建一个临时表,该表将直接在HBase表上运行SQL查询。但是,要执行此操作,我们需要在从HBase加载的PySpark数据框上创建视图。让我们从上面的“ hbase.column.mappings”示例中加载的数据帧开始。此代码段显示了如何定义视图并在该视图上运行查询。
df.createOrReplaceTempView("personView")result = spark.sql("SELECT * FROM personView") # SQL Queryresult.show()
执行result.show()将为您提供:

使用视图的最大优势之一是查询将反映HBase表中的更新数据,因此不必每次都重新定义和重新加载df即可获取更新值。视图本质上是针对依赖HBase的最新数据的用例。
如果您执行读取操作并在不使用View的情况下显示结果,则结果不会自动更新,因此您应该再次load()以获得最新结果。
下面是一个演示此示例。首先,将2行添加到HBase表中,并将该表加载到PySpark DataFrame中并显示在工作台中。然后,我们再写2行并再次运行查询,工作台将显示所有4行。
from pyspark.sql import Rowfrom pyspark.sql import SparkSessionspark = SparkSession \.builder \.appName("PySparkSQLExample") \.getOrCreate()
# 目录
tableCatalog = ''.join("""{"table":{"namespace":"default", "name":"tblEmployee", "tableCoder":"PrimitiveType"},"rowkey":"key","columns":{"key":{"cf":"rowkey", "col":"key", "type":"int"},"empId":{"cf":"personal","col":"empId","type":"string"},"empName":{"cf":"personal", "col":"empName", "type":"string"},"empState":{"cf":"personal", "col":"empState", "type":"string"}}}""".split())
#添加前2行
employee = [(10, 'jonD', 'Jon Daniels', 'CA'), (6, 'billR', 'Bill Robert', 'FL')]employeeRDD = spark.sparkContext.parallelize(employee)employeeMap = employeeRDD.map(lambda x: Row(key=int(x[0]), empId=x[1], empName=x[2], empState=x[3]))employeeDF = spark.createDataFrame(employeeMap)employeeDF.write.format("org.apache.hadoop.hbase.spark") \.options(catalog=tableCatalog, newTable=5) \.option("hbase.spark.use.hbasecontext", False) \.save()df = spark.read.format("org.apache.hadoop.hbase.spark") \.options(catalog=tableCatalog) \.option("hbase.spark.use.hbasecontext", False) \.load()df.createOrReplaceTempView("sampleView")result = spark.sql("SELECT * FROM sampleView")print("The PySpark DataFrame with only the first 2 rows")result.show()
#再添加2行
employee = [(11, 'bobG', 'Bob Graham', 'TX'), (12, 'manasC', 'Manas Chakka', 'GA')]employeeRDD = spark.sparkContext.parallelize(employee)employeeMap = employeeRDD.map(lambda x: Row(key=int(x[0]), empId=x[1], empName=x[2], empState=x[3]))employeeDF = spark.createDataFrame(employeeMap)employeeDF.write.format("org.apache.hadoop.hbase.spark") \.options(catalog=tableCatalog, newTable=5) \.option("hbase.spark.use.hbasecontext", False) \.save()# Notice here I didn't reload "df" before doing result.show() againprint("The PySpark Dataframe immediately after writing 2 more rows")result.show()
这是此代码示例的输出:

批量操作
使用PySpark时,您可能会遇到性能限制,可以通过并行操作来缓解这些限制。HBase通过批量操作实现了这一点,并且使用Scala和Java编写的Spark程序支持HBase。有关使用Scala或Java进行这些操作的更多信息,请查看此链接https://hbase.apache.org/book.html#_basic_spark。
但是,PySpark对这些操作的支持受到限制。通过访问JVM,可以创建HBase配置和Java HBase上下文对象。下面是显示如何创建这些对象的示例。

当前,存在通过这些Java对象支持批量操作的未解决问题。
https://issues.apache.org/jira/browse/HBASE-24829
故障排除
—辅助节点中的Python版本与驱动程序不同
例外:worker中的Python版本与驱动程序3.6中的版本不同,PySpark无法使用其他次要版本运行
如果未设置环境变量PYSPARK_PYTHON和PYSPARK_DRIVER_PYTHON或不正确,则会发生此错误。请参考上面的配置步骤,并确保在群集的每个节点上都安装了Python,并将环境变量正确设置为正确的路径。
— Py4J错误
AttributeError:“ SparkContext”对象没有属性“ _get_object_id”
尝试通过JVM显式访问某些Java Scala对象时,即“ sparkContext._jvm”,可能会出现此错误。已提交JIRA来解决此类问题,但请参考本文中提到的受支持的方法来访问HBase表
https://issues.apache.org/jira/browse/HBASE-24828
—找不到数据源“ org.apache.hbase.spark”
java.lang.ClassNotFoundException:无法找到数据源:org.apache.hadoop.hbase.spark。请在http://spark.apache.org/third-party-projects.html中找到软件包。
如果Spark驱动程序和执行程序看不到jar,则会出现此错误。确保根据选择的部署(CDSW与spark-shell submit)为运行时提供正确的jar。
结论
PySpark现在可用于转换和访问HBase中的数据。对于那些只喜欢使用Python的人,这里以及使用PySpark和Apache HBase,第1部分中提到的方法将使您轻松使用PySpark和HBase。
查看这些链接以开始使用CDP DH集群,并在CDSW中自己尝试以下示例:Cloudera Data Hub Cloudera Data Science Workbench(CDSW)作为PySpark更高级用法的一部分,请单击此处以了解第3部分,以了解PySpark模型的方式可以与HBase数据一起构建,评分和提供服务。
原文作者:Manas Chakka
原文链接:https://blog.cloudera.com/building-a-machine-learning-application-with-cloudera-data-science-workbench-and-operational-database-part-2-querying-loading-data/
