




最近,很多用户将他们的SQL Server升级到了最新版本的SQL Server2019。升级后,他们期望SQL Server的性能会提高,但是说实话,他们没有看到任何区别。下面将展示RowStore中批处理模式的简单示例。

行存储中的批处理模式
SQL Server 2019现在在RowStore中支持批处理模式,以前只能通过很少的黑客攻击或使用列存储索引来实现。但是,在SQL Server 2019中,现在批处理模式可用于查询,甚至没有列存储索引。
较新的批处理模式与传统的行模式操作之间的最大区别是聚合查询的性能。传统的行执行模式过程是逐行执行的,而批处理执行模式则通过将数据分组为批来处理数据。典型的批处理是几百行。通常,每批处理的行数在64到912行之间,但是同样,如果Microsoft发布新补丁或对该算法进行更新,则可以轻松更改此数字。
让我们看一个简单的示例,我们可以在行存储中获取批处理模式。

简单的例子
首先,我将构建一个包含大量数据的表。请注意,此演示在表中确实需要很多行,否则,它将发现传统的行模式使用效率很高。
在下面的示例中,我使用的是AdventureWorks数据库,但是您可以使用具有很多行的任何数据库。
USE AdventureWorks2017
GO
-- Create New Table
CREATE TABLE [dbo].[MySalesOrderDetail](
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
) ON [PRIMARY]
GO
-- Create clustered index
CREATE CLUSTERED INDEX [CL_MySalesOrderDetail] ON [dbo].[MySalesOrderDetail]
( [SalesOrderDetailID])
GO
-- Create Sample Data Table
-- WARNING: This Query may run upto 2-10 minutes based on your systems resources
INSERT INTO [dbo].[MySalesOrderDetail]
SELECT [SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber],
[OrderQty],[ProductID],[SpecialOfferID],[UnitPrice],
[UnitPriceDiscount],[LineTotal],[rowguid],[ModifiedDate]
FROM Sales.SalesOrderDetail S1
GO 50
现在,让我们运行以下脚本,将数据库的兼容性级别保持为140,这表示SQL Server 2017。
-- 2017
ALTER DATABASE [AdventureWorks2017] SET COMPATIBILITY_LEVEL = 140
GO
-- Comparing Regular Index with ColumnStore Index
USE AdventureWorks2017
GO
SET STATISTICS IO, TIME ON
GO
-- Select Table with regular Index
SELECT ProductID, SUM(UnitPrice) SumUnitPrice, AVG(UnitPrice) AvgUnitPrice,
SUM(OrderQty) SumOrderQty, AVG(OrderQty) AvgOrderQty
FROM [dbo].[MySalesOrderDetail]
GROUP BY ProductID
ORDER BY ProductID
GO
检查查询的执行计划。
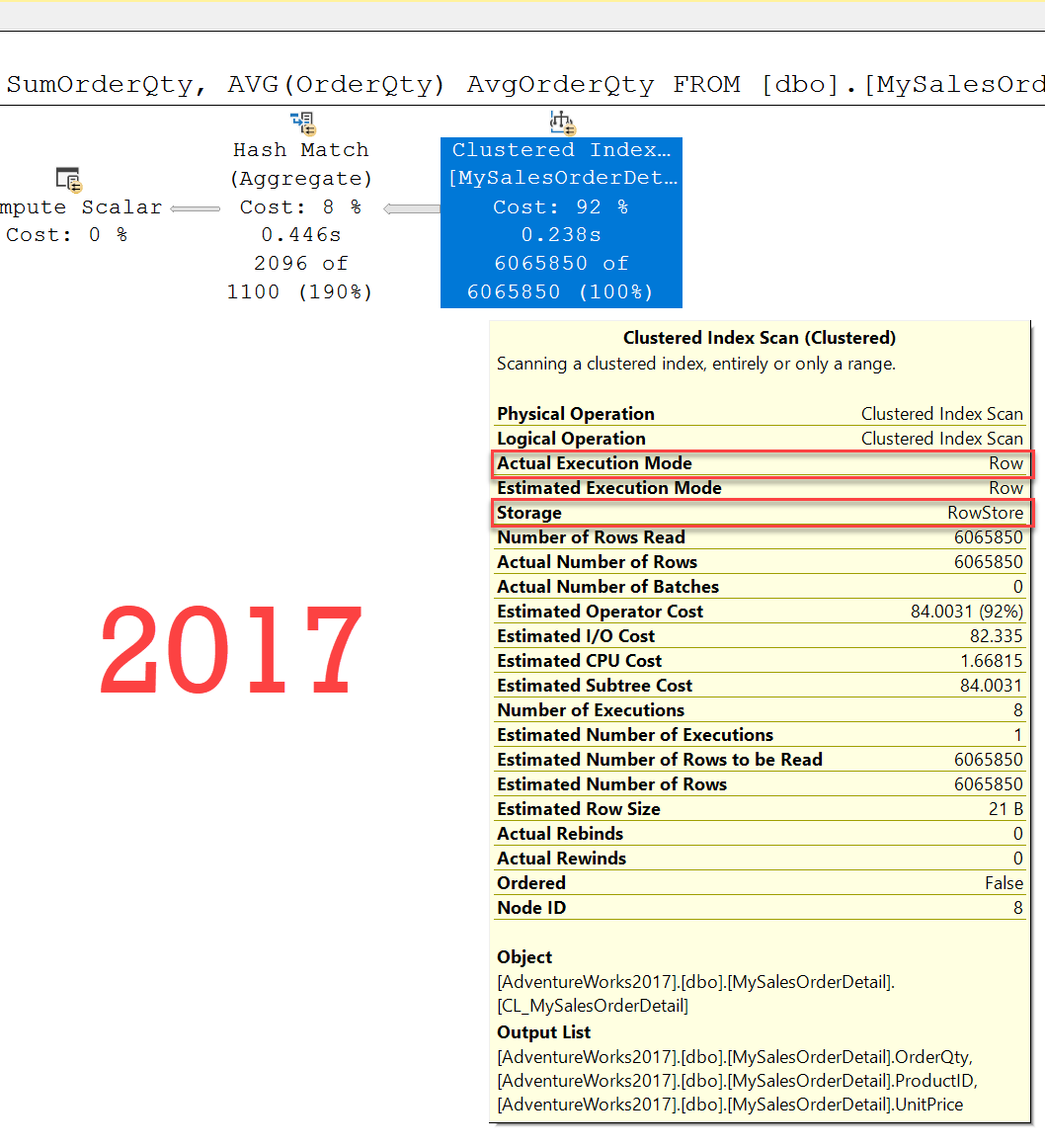
现在让我们运行以下脚本,将数据库的兼容性级别保持为150,这表示SQL Server 2019。
-- 2019
ALTER DATABASE [AdventureWorks2017] SET COMPATIBILITY_LEVEL = 150
GO
-- Comparing Regular Index with ColumnStore Index
USE AdventureWorks2017
GO
SET STATISTICS IO, TIME ON
GO
-- Select Table with regular Index
SELECT ProductID, SUM(UnitPrice) SumUnitPrice, AVG(UnitPrice) AvgUnitPrice,
SUM(OrderQty) SumOrderQty, AVG(OrderQty) AvgOrderQty
FROM [dbo].[MySalesOrderDetail]
GROUP BY ProductID
ORDER BY ProductID
GO
检查查询的执行计划。
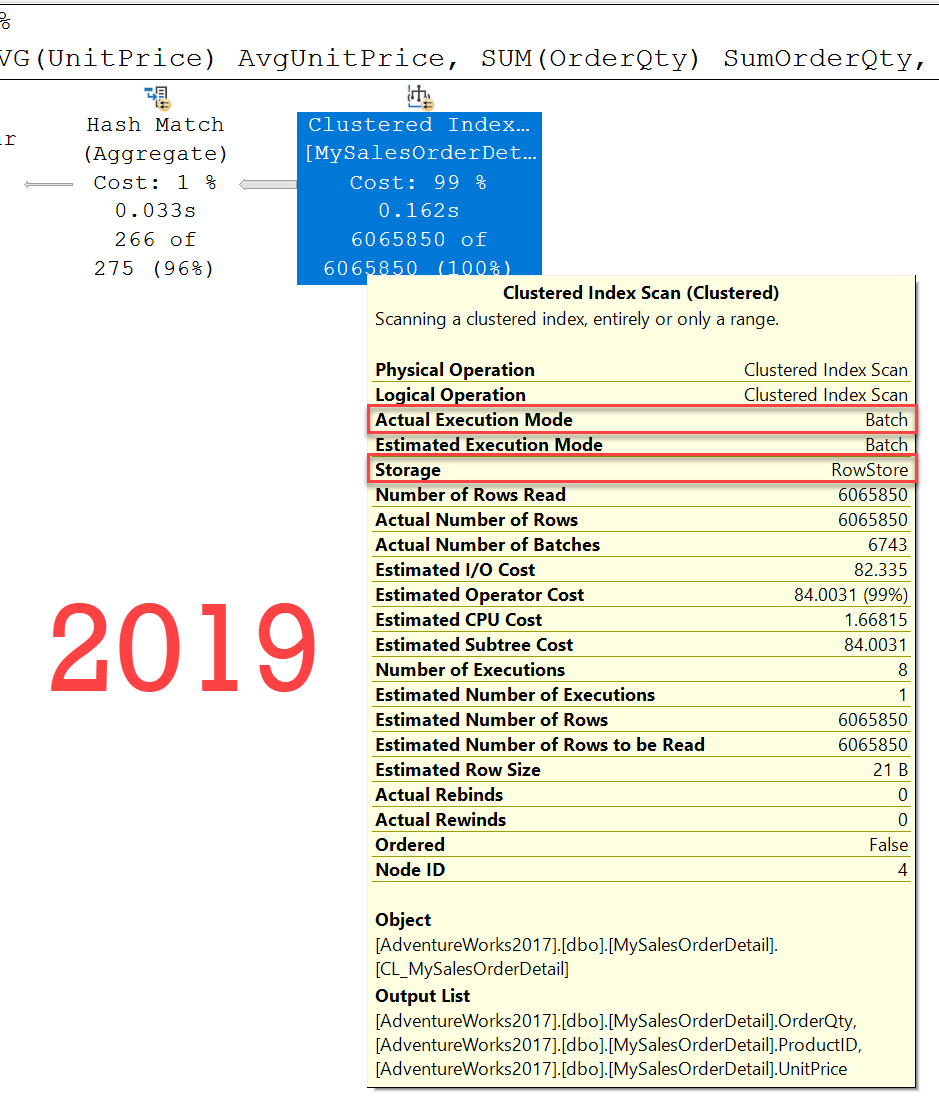
我已经对各种查询进行了性能测试,并且发现无论何时为查询触发批处理模式,总体性能都会提高20%到30%。若要获取批处理模式,您只需在SQL Server 2019上以最新的兼容性级别运行查询。
最后修改时间:2019-11-20 11:59:52
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
