




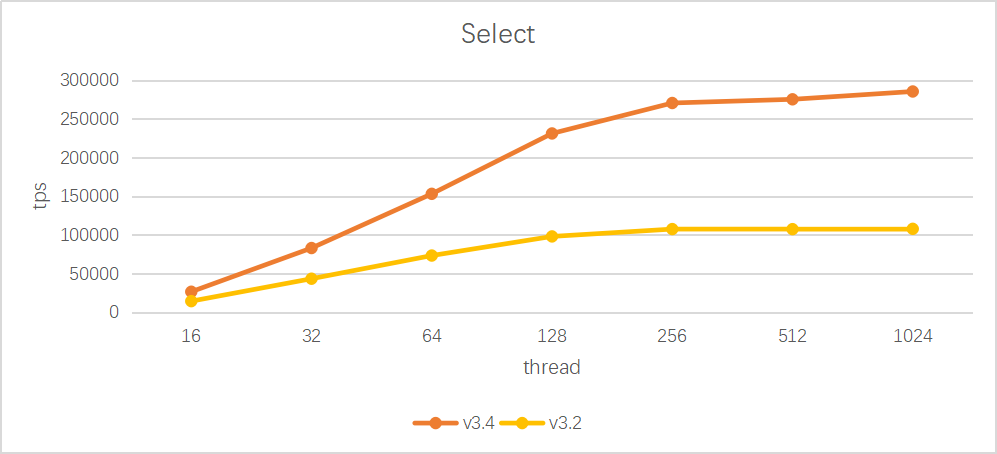
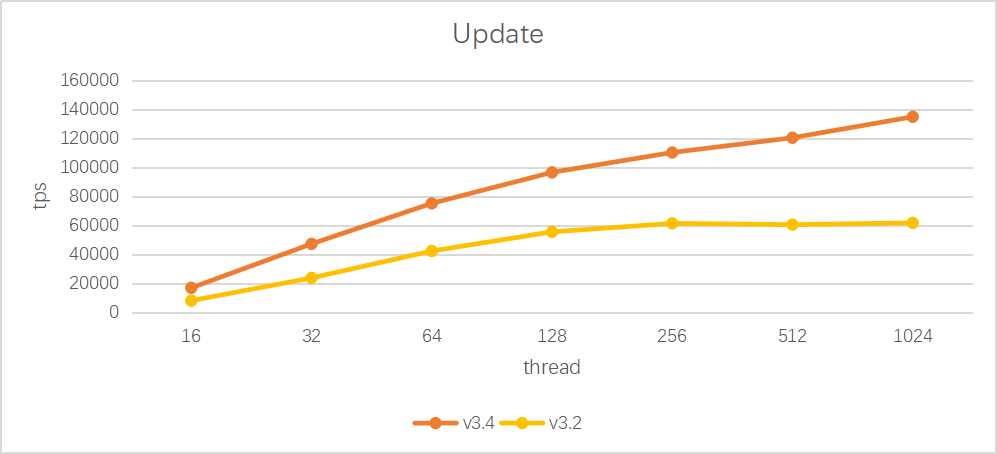
分布式交易场景性能大幅提升
Improved 2PC Algorithm
Latch-less Memory Model
Improved Raft Algorithm
Improved Full-text Search Algorithm
存储引擎
事务Auto-commit下推优化,将事务二阶段提交简化为一阶段提交,提升事务性能
事务一致性确认机制
实现多层级内存池和无锁内存模型
全并发同步,提升副本数据同步性能
提供增量数据归档、同步能力
通过开启日志的全量模式和时间模式,可以实现按天,或指定时间对增量数据进行抽取,转换和归档,并将增量数据导入到其它ODS系统。
全文索引支持数组类型
全文索引支持 $or 和 $not 操作
全文索引性能大幅提升
访问计划增加自动过期清理,并实现对 $in 操作的参数化缓存能力
插入数据支持重复键替代
索引支持 not null 约束
优化事务监控性能,实现无锁事务监控机制,减少事务监控管理对外部业务的性能影响
SQL引擎
优化高可用能力,实现SQL引擎横向扩容
算子下推存储节点,精确计算,提升网络带宽利用率
事务Auto-commit下推存储引擎,简化事务二阶段提交为一阶段提交,提升事务性能
支持NO TRANSACTION模式,提升初始化数据场景性能
优化DDL操作,包括rename table,modify field,add primary key、index等操作
全面兼容 MariaDB 语法
大对象引擎
提供S3兼容的对象存储接口
大对象存储支持按时间序进行自动分区,提升对大对象的存取和管理能力,可以快速按时间进行归档和清理
大对象过滤支持过滤条件和精准匹配
易用性
支持指定节点的重新选举能力
提供 SQL 语法查询数据库当前状态与监控信息
提供性能监控和慢查询分析能力
易用性进一步提高,巨杉工具矩阵正式推出
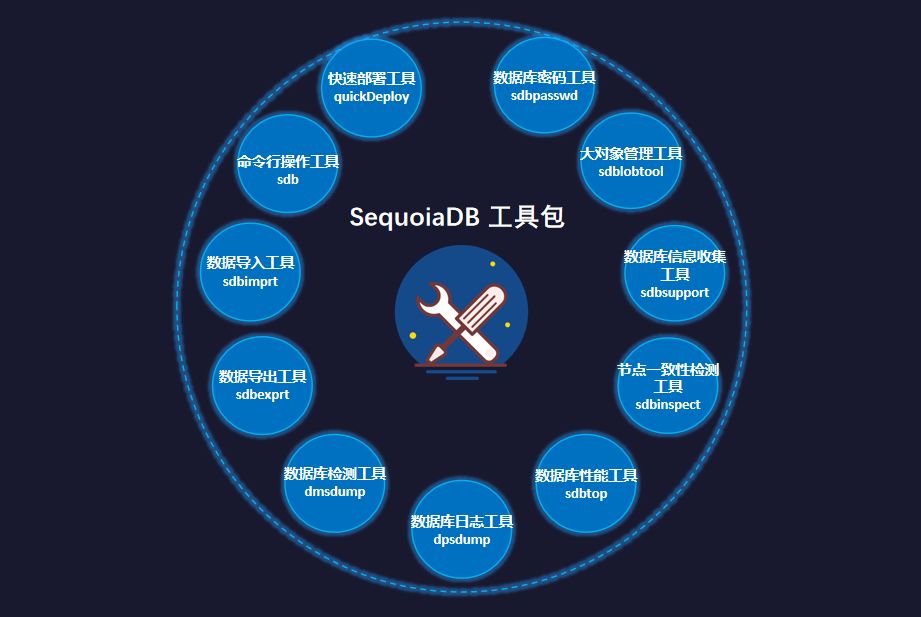
SequoiaDB 工具矩阵示意图
 前往巨杉数据库官网下载中心体验 SequoiaDB V3.4
前往巨杉数据库官网下载中心体验 SequoiaDB V3.4
http://download.sequoiadb.com/cn/
巨杉Tech | 基于Kafka+Spark+SequoiaDB实时处理架构快速实战
巨杉Tech | SparkSQL+SequoiaDB 性能调优策略
巨杉Tech | 使用 etlAlchemy 工具迁移数据实战
巨杉Tech | SequoiaDB 巨杉数据库高可用容灾测试
巨杉Tech | 使用 SequoiaDB + Docker + Nodejs 搭建 Web 服务器
巨杉学习笔记 | SequoiaDB MySQL导入导出工具使用实战



