下图描述了Hive表的类型。
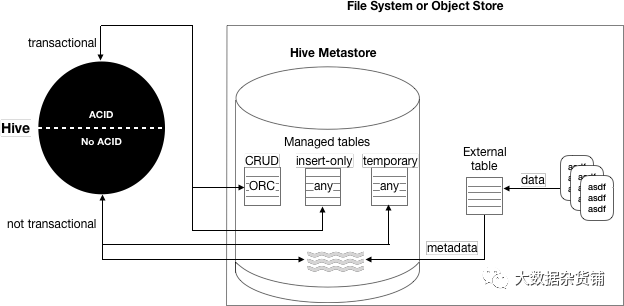
以下矩阵包括可以使用Hive创建的表的类型、是否支持ACID属性、所需的存储格式以及关键的SQL操作。
表类型 | ACID特性 | 文件格式 | 插入 | 更新/删除 |
|---|---|---|---|---|
托管表:CRUD事务 | 是 | ORC | 是 | 是 |
托管表:仅插入式事务 | 是 | 任意格式 | 是 | 没有 |
托管表:临时 | 没有 | 任意格式 | 是 | 没有 |
外部表 | 没有 | 任意格式 | 是 | 没有 |
虽然不能使用SQL UPDATE或DELETE语句删除某些类型的表中的数据,但是可以对任何类型的表使用DROP PARTITION来删除数据。
仅插入使用的表支持所有文件格式。
默认情况下,托管表的存储类型为“优化行列”(ORC)。如果在表创建的过程中未指定任何存储来接受默认的设置,或者指定了ORC存储,则将获得具有插入、更新和删除(CRUD)功能的ACID表。如果指定其他任何存储类型,例如text、CSV、AVRO或JSON,则将获得仅插入的ACID表。您不能更新或删除仅插入表中的列。
与用作联机分析处理(OLAP)系统相反,Hive旨在支持相对较低的事务率。您可以使用SHOW TRANSACTIONS命令列出未完成和中止的事务。
Hive 3中的事务表与非ACID表相当。Hive 3事务表中不需要桶或排序。桶化不会影响性能。这些表与原生云存储兼容。
Hive支持一个事务一个语句,该语句可以包含任意数量的行、分区或表。
Hive 3不支持以下外部表功能:
在外部表上运行DROP TABLE时,默认情况下,Hive仅删除元数据(Schema)。如果您希望DROP TABLE命令也删除外部表中的实际数据,就像DROP TABLE在托管表上所做的那样,则需要将external.table.purge属性设置 为true。
在Cloudera数据平台(CDP)公共云中,您可以在设置数据仓库期间指定托管表和外部表元数据在Hive仓库中的位置。例如:
hive.metastore.warehouse.external.dir = s3a://bucketName/warehouse/tablespace/external/hivehive.metastore.warehouse.dir=s3a://bucketName/warehouse/tablespace/managed/hive
在Cloudera Manager(CM)中,当您启动集群时,您接受默认值或指定Hive Metastore变量,hive.metastore.warehouse.dir和 hive.metastore.warehouse.external.dir确定Hive表的存储位置。托管表位于托管表空间中,只有Hive可以访问。默认情况下,Hive假定外部表位于外部表空间中。
要确定托管表或外部表的类型,可以运行DESCRIBE EXTENDED table_name命令。
下表和后续各节介绍了托管(事务)表与外部表之间的其他区别:
表类型 | 安全 | Spark访问 | 最佳化 |
|---|---|---|---|
托管表(事务) | 仅支持Ranger授权,无简单身份验证 | 是的,使用Hive Warehouse Connector | 统计及其他 |
外部表 | Ranger或简单身份验证 | 是的,直接文件访问 | 有限 |
• 创建CRUD事务表
当需要可更新、删除和合并的托管表时,可以创建具有ACID(原子性,一致性,隔离性和持久性)属性的CRUD事务表。默认情况下,表数据以优化行列(ORC)文件格式存储。
• 创建仅插入的事务表
如果不需要更新和删除功能,则可以使用任何存储格式创建事务表。这种类型的表具有ACID属性,是托管表,并且仅接受插入操作。仅插入表的存储格式不限于ORC。
• 创建,使用和删除外部表
您可以使用外部表(该表是Hive不能管理的表)将数据从文件系统上的文件导入Hive。与Hive托管表相反,外部表将其数据保留在Hive元存储之外。Hive Metastore仅存储外部表的架构元数据。Hive不管理或限制对实际外部数据的访问。
• 删除外部表和数据
在外部表上 运行DROP TABLE时,默认情况下,Hive仅删除元数据(模式)。如果您希望DROP TABLE命令也删除外部表中的实际数据,就像DROP TABLE在托管表上一样,则需要相应地配置表属性。
• 使用约束
您可以在Hive ACID表定义中使用DEFAULT,PRIMARY KEY,FOREIGN KEY和NOT NULL约束来提高数据的性能、准确性和可靠性。
• 确定表类型
您可以确定Hive表的类型,它是否具有ACID属性,存储格式(例如ORC)和其他信息。出于多种原因,了解表类型非常重要,例如了解如何在表中存储数据或从集群中完全删除数据。
如果数据可预测且易于定位,则Hive引擎和BI工具可以简化查询。Hive强制执行以下约束:
默认
确保存在一个值,该值在数据仓库卸载案例中很有用。
主键
使用唯一标识符标识表中的每一行。
外键
使用唯一标识符标识另一个表中的行。
非空
检查列值未设置为NULL。
优化器使用该信息做出明智的决策。例如,如果引擎知道某个值是主键,则它不会查找重复项。以下示例显示了约束的使用:
CREATE TABLE Persons (ID INT NOT NULL,Name STRING NOT NULL,Age INT,Creator STRING DEFAULT CURRENT_USER(),CreateDate DATE DEFAULT CURRENT_DATE(),PRIMARY KEY (ID) DISABLE NOVALIDATE);CREATE TABLE BusinessUnit (ID INT NOT NULL,Head INT NOT NULL,Creator STRING DEFAULT CURRENT_USER(),CreateDate DATE DEFAULT CURRENT_DATE(),PRIMARY KEY (ID) DISABLE NOVALIDATE,CONSTRAINT fk FOREIGN KEY (Head) REFERENCES Persons(ID) DISABLE NOVALIDATE);
1. 在Hive Shell中,获取对该表的扩展描述。
例如: DESCRIBE EXTENDED mydatabase.mytable;
2. 滚动到命令输出的底部以查看表类型。
...| Detailed Table Information | Table(tableName:t2, dbName:mydatabase, owner:hdfs, createTime:1538152187, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:a, type:int, comment:null), FieldSchema(name:b, type:int, comment:null)], ...
• 表定义
• 列名
• 资料类型
• 中央模式存储库中的注释
非ACID
如果表属性不包含任何与ACID相关的属性,则此属性为true 。例如,该表不包含此类属性 transactional=true或insert_only=true。
ACID
如果表属性确实包含一个或多个ACID属性,则此属性为true。
完全的ACID
此属性为true,如果表属性包含 transactional=true但不是 insert_only=true。
仅插入的ACID
表属性包含insert_only=true。
| ACID | 位置属性 | 注释 | 行动 | 注释 |
|---|---|---|---|---|
Non-ACID | 是 | 是 | 迁移到CDP,例如从HDP或CDH群集 | 表存储为外部 |
非ACID,ACID,完整ACID,仅插入ACID | 是 | 没有 | 表位置为空 | 表存储在子目录中 metastore.warehouse.external.dir |
表要求 | 客户端符合要求 | 托管表 | ACID表类型 | 结果 | 行动 |
|---|---|---|---|---|---|
客户端可以写入任何类型的ACID表 | 没有 | 是 | 是 | 创建表失败 | |
客户端可以写入完整的ACID表 | 没有 | 是 | insert_only = true | 创建表失败 | |
客户端可以写入仅插入的ACID表 | 没有 | 是 | insert_only = true | 创建表失败 |
Spark has no access to table `mytable`. Clients can access this table only ifthey have the following capabilities: CONNECTORREAD,HIVEFULLACIDREAD, HIVEFULLACIDWRITE,HIVEMANAGESTATS, HIVECACHEINVALIDATE, ...
读写操作
• 写入多个分区
• 在单个SELECT语句中使用多个insert子句
仅插入表中的原子性和隔离性
CREATE TABLE tm (a int, b int) TBLPROPERTIES('transactional'='true', 'transactional_properties'='insert_only')
INSERT INTO tm VALUES(1,1);INSERT INTO tm VALUES(2,2); FailsINSERT INTO tm VALUES(3,3);
tm___ delta_0000001_0000001_0000└── 000000_0___ delta_0000002_0000002_0000 //Fails└── 000000_0___ delta_0000003_0000003_0000└── 000000_0
CRUD表中的原子性和隔离
CREATE TABLE acidtbl (a INT, b STRING);
+----------------------------------------------------+| createtab_stmt |+----------------------------------------------------+| CREATE TABLE `acidtbl`( || `a` int, || `b` string) || ROW FORMAT SERDE || 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' || STORED AS INPUTFORMAT || 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' || OUTPUTFORMAT || 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' || LOCATION || 's3://myserver.com:8020/warehouse/tablespace/managed/hive/acidtbl' || TBLPROPERTIES ( || 'bucketing_version'='2', || 'transactional'='true', || 'transactional_properties'='default', || 'transient_lastDdlTime'='1555090610') |+----------------------------------------------------+
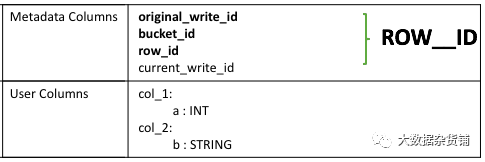
• 映射到创建行的事务的写ID
• 创建行的物理写入器的存储区ID(具有若干位信息的位支持整数)
• 行ID,在将行写入数据文件时对行进行编号
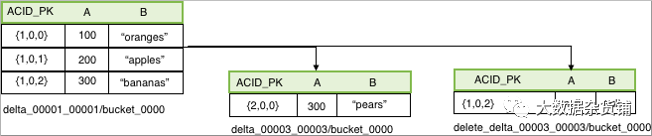
创建操作
INSERT INTO acidtbl (a,b) VALUES (100, "oranges"), (200, "apples"), (300, "bananas")
此操作将生成目录和文件delta_00001_00001 / bucket_0000,它们具有以下数据:
ROW_ID | a | b |
|---|---|---|
{1,0,0} | 100 | "oranges" |
{1,0.1} | 200 | "apples" |
{1,0,2} | 300 | "bananas" |
删除操作
DELETE FROM acidTbl where a = 200;
| ROW_ID | a | b |
|---|---|---|
{1,0,1} | null | nul |
更新操作
UPDATE acidTbl SET b = "pears" where a = 300;