




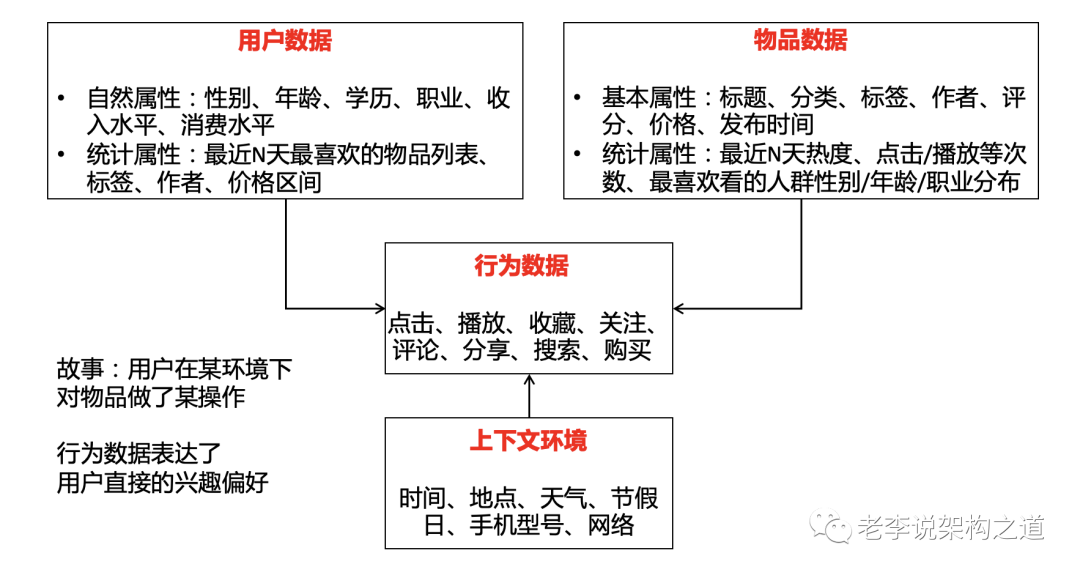
推荐系统数据分类
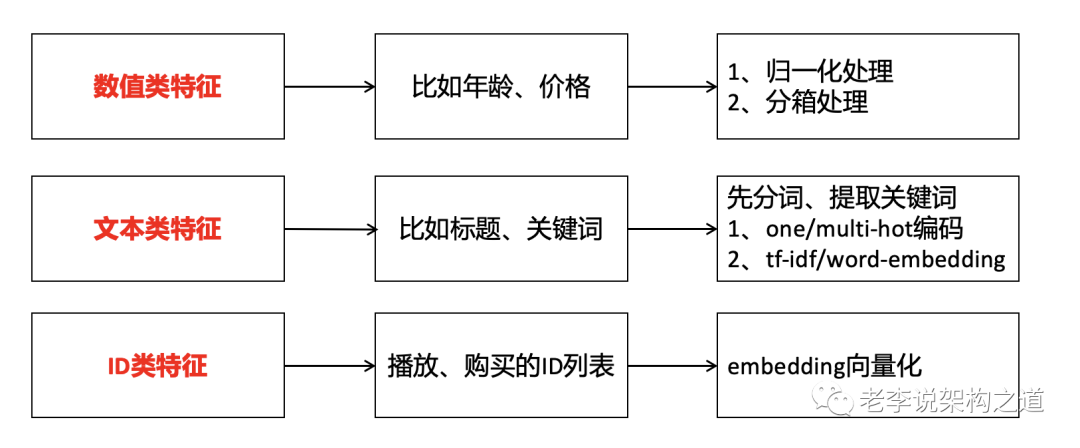
数据源的特征处理
问题背景:机器学习模型的输入,都需要是数值类型
特征工程:把原始特征经过筛选、转换、映射,得到可以输入给机器学习模型的数值类型;
怎样解决冷启动问题?
物品冷启动:新加入系统的物品,因缺少行为数据而无法被扩散推荐;
在注重时效性的场景是问题,比如新闻类应用
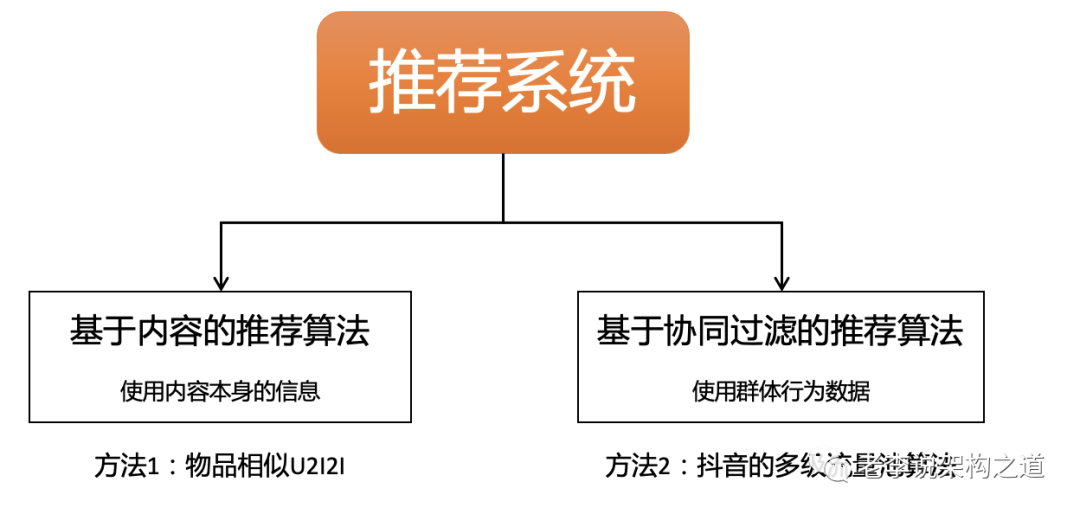
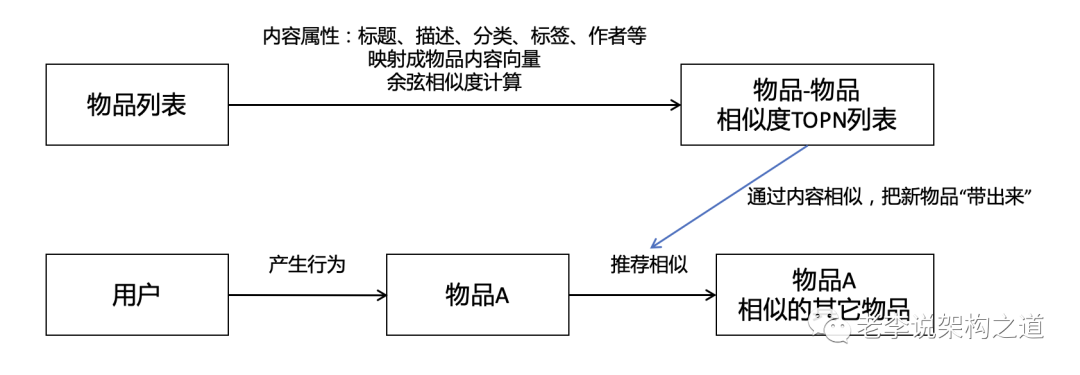
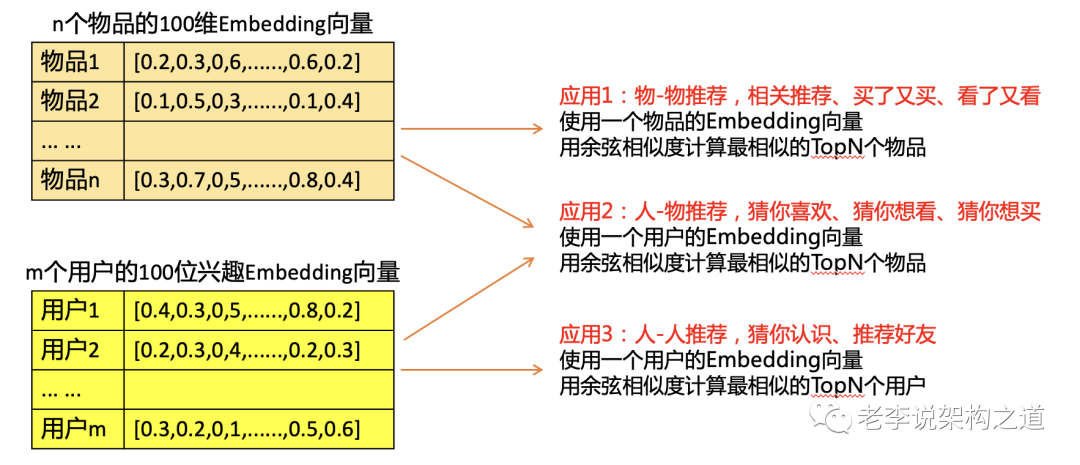
1、基于物品相似算法的U 2 I 2 I,类似功能:看了还看、相关推荐
2、抖音内容推荐算法,多级流量池机制,实质上是基于行为方法的试探

Embedding技术:
Embedding是什么东西?
直观上看,是一个数组,元素是小数数字,比如:[0.3, 0.5]因为有2个元素,也叫2维Embedding;
物理意义上,每个小数代表一个兴趣强度,比如数组第一个元素代表“喜剧”,第二个代表“动作”用户Embedding:[0.8, 0.3],含义是这个人喜欢0.8强度的喜剧,喜欢0.3强度的动作电影Embedding:[0.4, 0.6],含义是:这个电影0.4的强度是喜剧片,0.6的强度是动作片余弦函数([0.8, 0.3], [0.4, 0.6])就能算出来这个人喜欢这个电影的程度这是可解释的embedding但一般情况下,是用机器学习得到用户/物品的Embedding这时候每个数值没法解释代表什么“兴趣”虽然没法解释,这样的“兴趣向量”却可以大量使用也叫作latent factor、隐因子、隐含兴趣向量。
怎样使用Embedding?
怎样使用数据生成Embedding?
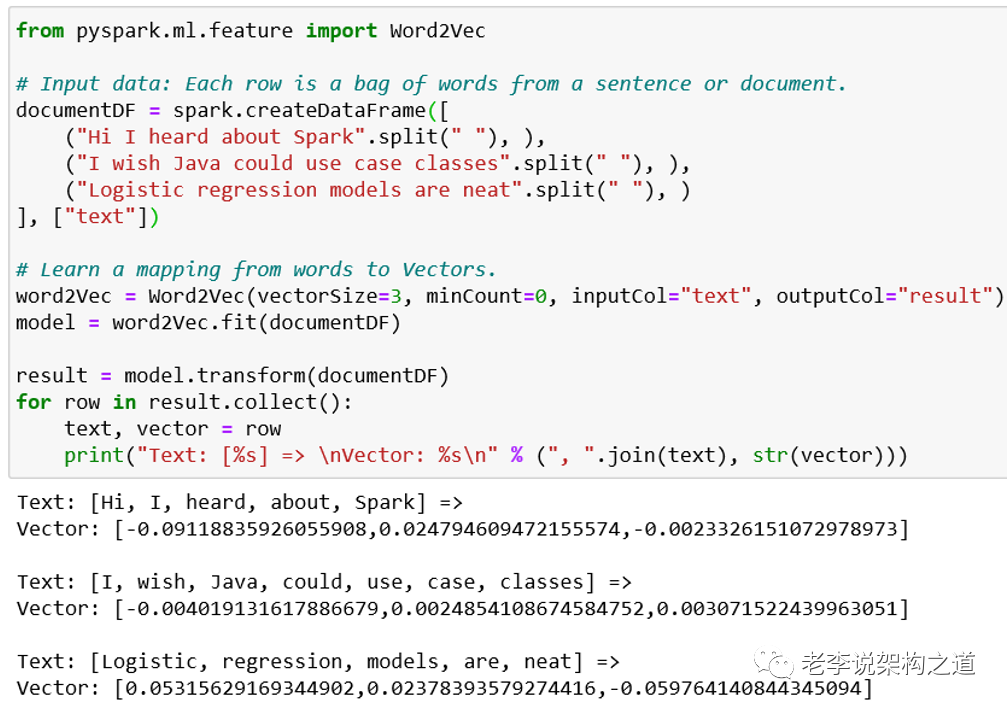
1、基于内容word2vec的Embedding
2、协同过滤矩阵分解的方法

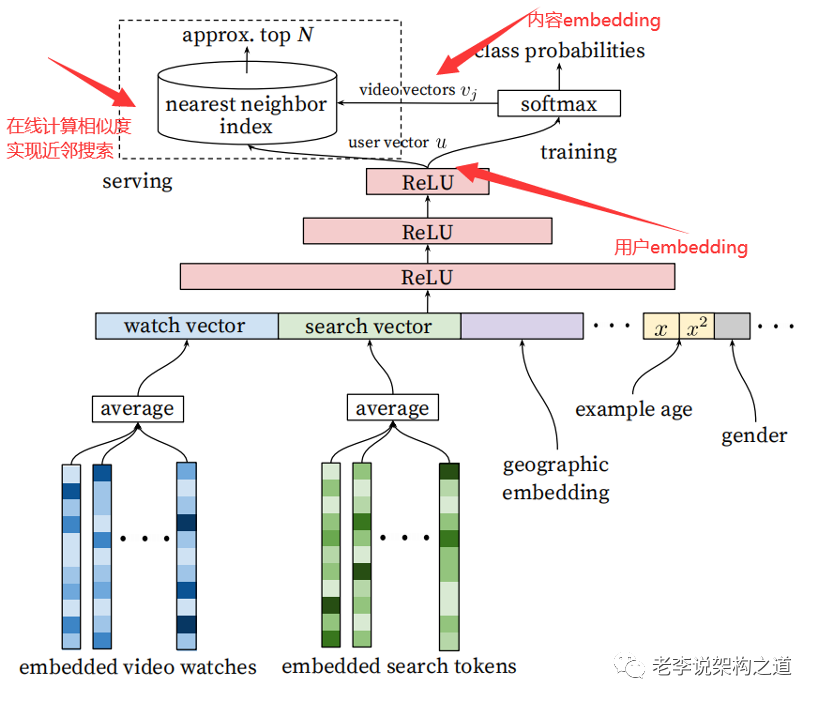
3、DNN深度学习的方法
使用Embedding的技术难题?
Embedding的快速近邻搜索是一个技术难题
对一个电影embedding,怎样在100W的其它电影Embedding中,搜出Top10最相似的电影?
解决思路如下:
1、离线暴力搜索
对100W的每个embedding,离线使用for循环挨个计算余弦相似度,产出TOP 10的电影将(电影ID、相似TOP10的电影ID列表)存入Redis在线使用;
2、离线LSH降低准确度的相似搜索
原理是先把Embedding分成很多桶,然后在桶或桶的附近搜索,可以极大加快搜索速度;
3、在线搜索,满足50MS以下的百万、千万的近邻搜索
常用facebook开源的faiss近邻搜索库,可以流式往里面添加Embedding,然后ms级别搜索近邻使用的原理为降维、聚类、索引树等方法;
怎样实现AB实验:
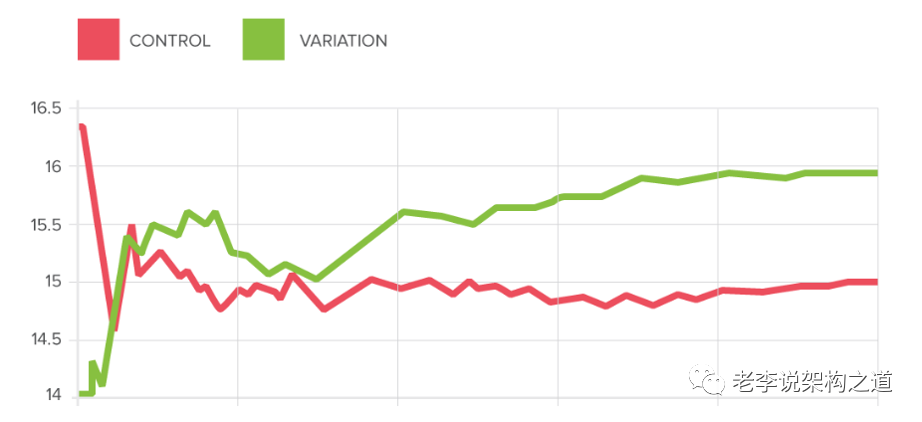
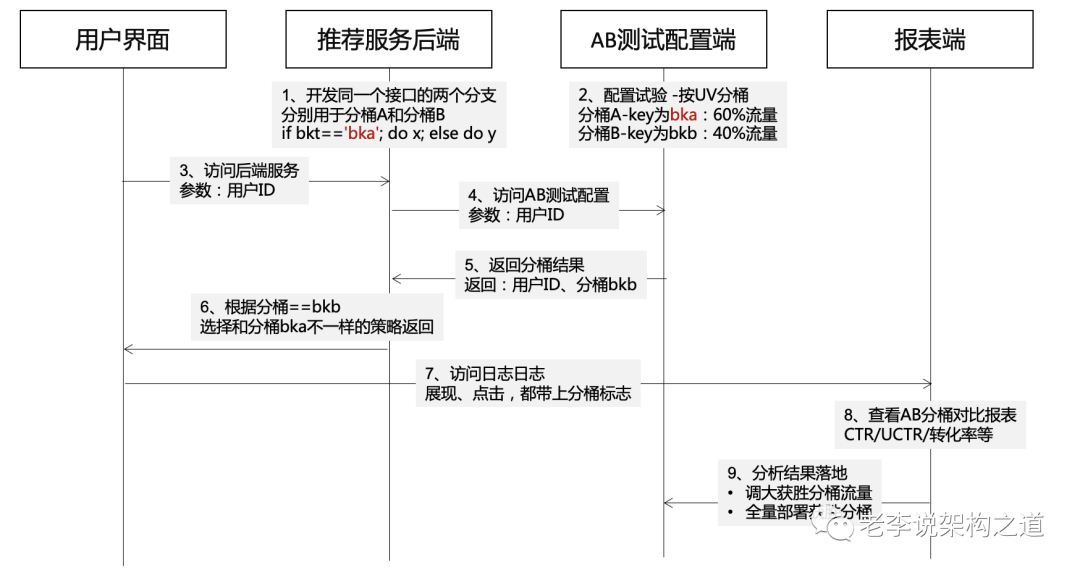
AB测试中的常见错误:
不要同时运行太多测试:
要确定测试的优先级,一起测试太多的元素很难确定哪个元素对测试的成功或失败影响最大。
实验的流量大小:
流量样本的数量过小,实验结论不能使人信服
测试持续时间不能太短:
运行测试时间过短会导致测试失败或产生不重要的结果
无法遵循迭代过程:
A B测试是一个迭代过程,每个测试都基于先前测试的结果,不管当前成功或失败,都不要停止继续AB测试;
开发环境简单说一下:
编辑器:jupyter notebook、pycharm
Python环境:
anaconda、numpy/pandas/matplotlib、sklearn、tensorflow、pyspark、flask
