




1、关于表引擎类型:
第一:MergeTree 表引擎主要用于海量数据分析,支持数据分区、存储有序、主键索引、稀疏索引、数据 TTL 等。MergeTree 支持所有 ClickHouse SQL 语法,但是有些功能与 MySQL 并不一致,比如在 MergeTree 中主键并不用于去重。
第二:为了解决 MergeTree 相同主键无法去重的问题,ClickHouse 提供了 ReplacingMergeTree 引擎,用来做去重。ReplacingMergeTree 确保数据最终被去重,但是无法保证查询过程中主键不重复。因为相同主键的数据可能被 shard 到不同的节点,但是 compaction 只能在一个节点中进行,而且optimize 的时机也不确定。
第三:CollapsingMergeTree 引擎要求在建表语句中指定一个标记列 Sign(插入的时候指定为 1,删除的时候指定为 -1),后台 Compaction 时会将主键相同、Sign 相反的行进行折叠,也即删除。来消除 ReplacingMergeTree 的限制。
第四:为了解决 CollapsingMergeTree 乱序写入情况下无法正常折叠问题,VersionedCollapsingMergeTree 表引擎在建表语句中新增了一列Version,用于在乱序情况下记录状态行与取消行的对应关系。主键相同,且 Version 相同、Sign 相反的行,在 Compaction 时会被删除。
第五:ClickHouse 通过 SummingMergeTree 来支持对主键列进行预先聚合。在后台 Compaction 时,会将主键相同的多行进行 sum 求和,然后使用一行数据取而代之,从而大幅度降低存储空间占用,提升聚合计算性能。
第六:AggregatingMergeTree 也是预先聚合引擎的一种,用于提升聚合计算的性能。与 SummingMergeTree 的区别在于:SummingMergeTree 对非主键列进行 sum 聚合,而 AggregatingMergeTree 则可以指定各种聚合函数。
MergeTree 的建表语法:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAUErEMAMLERLALLIZED|ALIAS expr],
省略...) ENGINE = MergeTree()
[PARTITION BY expr]
介绍其中几个关键选项:
1、PARTITION BY:分区键。指定表数据以何种标准进行分区。分区键既可以是单个列字段,也可以 通过元组的形式使用多个列字段,同时它也支持使用列表达式。
2、ORDER BY:排序键,用于指定在一个数据片段内,数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同。
3、PRIMARY KEY:主键。声明后会依照主键字段生成一级索引。默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用 ORDER BY 代为指定主键。
4、SETTINGS:index_granularity 选项表示索引的粒度,默认值为 8192。MergeTree 索引在默认情况下,每间隔 8192 行数据才生成一条索引。
5、SAMPLE BY:抽样表达式,用于声明数据以何种标准进行采样。
注意 settings 中的重要参数:
index_granularity 默认是 8192
index_granularity_bytes 默认 10M,需要通过enable_mixed_granularity_parts 来开启
2、ClickHouse 工作原理
MergeTree 表引擎的内部工作细节!最终就是告诉你:为什么 clickhouse 做查询分析,那么快?
ClickHouse 从 OLAP 场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据 Sharding、数据Partitioning、TTL、主备复制等丰富功能。这些功能共同为 ClickHouse 极速的分析性能奠定了基础。
2.1 数据分区
关于表分区目录结构:MergeTree 表的分区目录物理结构:
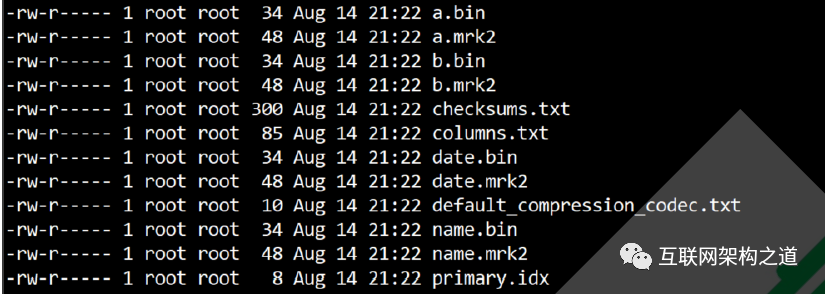
1、checksums.txt:校验文件。使用二进制格式存储。它保存了余下各类文件(primary.idx、count.txt等)的 size 大小及 size 的哈希值,用于快速校验文件的完整性和正确性。
2、columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息
3、count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数
4、primary.idx:一级索引文件,主键索引文件
5、xxx.bin:数据文件,使用压缩格式存储,默认为 LZ4 压缩格式,用于存储某一列的数据,每一列都对应一个该文件,如列 date 为 date.bin
6、xxx.mrk2:列字段标记文件,如果使用了自适应大小的索引间隔,则标记文件以 .mrk2 命名,否则以 .mrk 命名。它建立 primary.idx 稀疏索引与
xxx.bin 数据文件之间的映射关系,先通过主键索引找到数据的偏移量,然后去 xxx.bin 数据文件中找到真实数据
7、... 还有二级索引 和 分区键相关信息文件等等
2.2列式存储
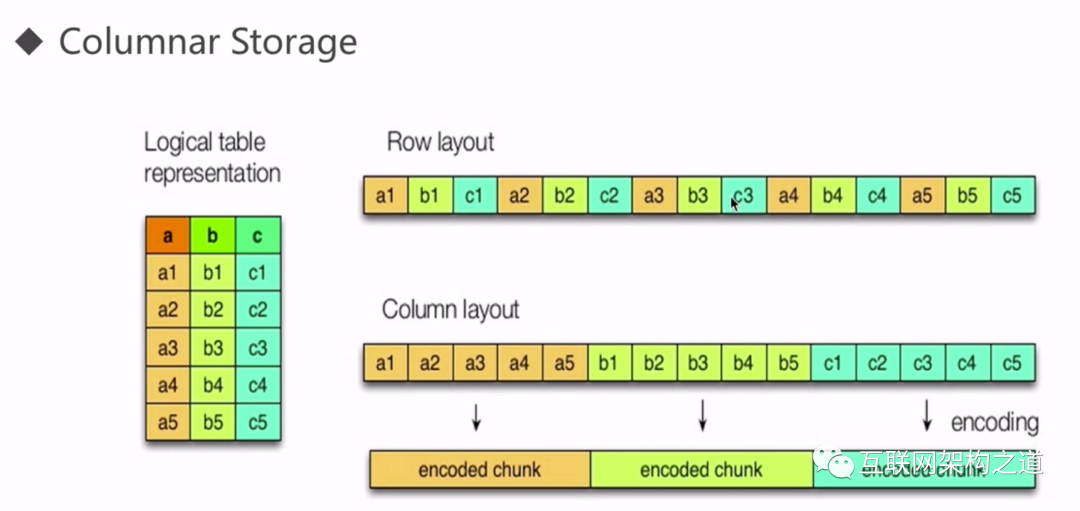
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
2.3一级索引
关于一级索引:MergeTree 的主键使用 PRIMARY KEY 定义,待主键定义之后,MergeTree 会依据 index_granularity 间隔(默认 8192 行),为数据表生成一级索引并保存至 primary.idx 文件内。一级索引是稀疏索引,意思就是说:每一段数据生成一条索引记录,而不是每一条数据都生成索引,如果是每一条数据都生成索引,则是稠密索引。稀疏索引的好处,就是少量的索引标记,就能记录大量的数据区间位置信息,比如不到 24414 条标记信息,就能为 2E 条数据提供索引(算法:200000000 8192)。在 ClickHouse 中,一级索引常驻内存。总的来说:一级索引和标记文件一一对齐,两个索引标记之间的数据,就是一个数据区间,在数据文件中,这个数据区间的所有数据,生成一个压缩数据块。
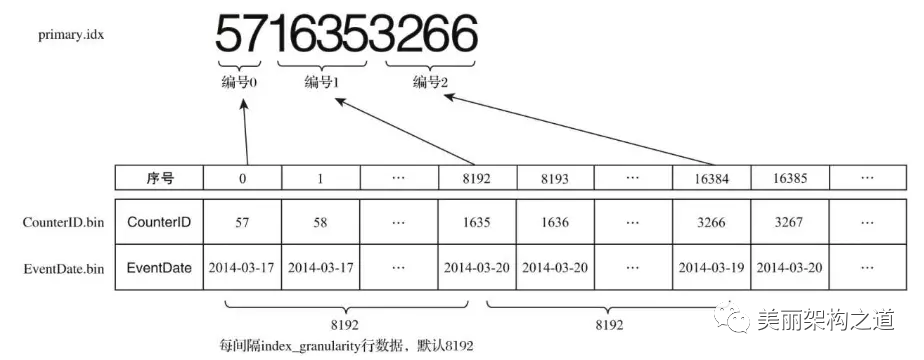
需要注意的是:ClickHouse 的主键索引与 MySQL 等数据库不同,它并不用于去重,即便 primary key 相同的行,也可以同时存在于数据库中。要想实
现去重效果,需要结合具体的表引擎 ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree 实现。
2.4、二级索引
关于二级索引:又称之为跳数索引。目的和一级索引一样,是为了减少待搜寻的数据的范围。跳数索引的默认是关闭的,需要通SET allow_experimental_data_skipping_indices = 1 来开启,索引生成粒度由 granularity 控制,如果生成了二级索引,则会在分区目录下生成额外
的:skp_idx_[Column].idx 与 skp_idx_[Column].mrk 文件。跳数索引的生成规则:按照特定规则每隔 granularity 个 index_granularity 条数据,就会
生成一条跳数索引。比如 minmax 跳数索引,生成的是:granularity 个 index_granularity 条数据内的最大值最小值生成一条索引,如果将来需要针对构建二级索引的这个字段求最大值最小值,则可以帮助提高效率。跳数索引一共支持四种类型:minmax(最大最小)、set(去重集合)、ngrambf_v1(ngram分词布隆索引) 和 tokenbf_v1(标点符号分词布隆索引),一张数据表支持同时声明多个跳数索引。
关于跳数索引支持的多种类型的区别:
1、minmax:以 index_granularity 为单位,存储指定表达式计算后的 min、max 值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
2、set(max_rows):以index granularity为单位,存储指定表达式的 distinct value 集合,用于快速判断等值查询是否命中该块,减少IO。
3、ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将 string 进行 ngram 分词后,构建bloom filter,能够优化 等值、like、in 等查询条件。
4tokenbf_v1(size_of_bloom_filter_in_bytes,number_of_hash_functions, random_seed):与 ngrambf_v1 类似,区别是不使用 ngram进行分词,而是通过标点符号进行词语分割。
5、bloom_filter([false_positive]):对指定列构建 bloom filter,用于加速 等值、like、in 等查询条件的执行。
2.5. 数据压缩
关于数据压缩:ClickHouse 的数据存储文件 column.bin 中存储是一列的数据,由于一列是相同类型的数据,所以方便高效压缩。在进行压缩的时候,注意:一个压缩数据块由头信息和压缩数据两部分组成,头信息固定使用 9 位字节表示,具体由 1 个 UInt8(1字节)整型和 2 个 UInt32(4字节)整型
组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小。每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在
64KB~1MB,其上下限分别由 min_compress_block_size(默认65536=64KB)与 max_compress_block_size(默认1048576=1M)参数指定。
具体压缩规则:原理的说法:每 8192 条记录,其实就是一条一级索引 一个索引区间 压缩成一个数据块。自适应压缩.
2.6数据标记
关于数据标记:数据标记文件也与 .bin 文件一一对应。即每一个列字段 [Column].bin 文件都有一个与之对应的 [Column].mrk2 数据标记文件,用于记录数据在 .bin 文件中的偏移量信息。一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息。它们分别表示在此段数据区间内,在对应的 .bin 压缩文件中,压缩数据块的起始偏移量;以及将该数据压缩块解压后,其未压缩数据的起始偏移量。每一行标记数据都表示了一个片段的数据
(默认8192行)在 .bin 压缩文件中的读取位置信息。标记数据与一级索引数据不同,它并不能常驻内存,而是使用 LRU(最近最少使用)缓存策略加快
其取用速度。
总结数据读取流程:先根据一级索引,找到标记文件中的对应数据压缩块信息(压缩块在 .bin 文件中的起始偏移量和未压缩之前该条数据的是偏移量)然后从 .bin 文件中,把压缩块加载到内存,解压缩之后执行读取。建立了主键索引到数据文件的映射.
后面会讲一些案例分析,敬请期待……
