




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
Apache Atlas元数据管理入门
内容提要:
1.理解元数据
2.认识Apache Atlas
3.Apache Atlas架构原理
4.Apache Atlas2.1新特性
1. 理解元数据
元数据:描述数据的数据
,或者换种说法如下图,为其它数据提供信息的数据
。

比如在MySQL
中,元数据可参考官方文档说明:
https://dev.mysql.com/doc/refman/5.7/en/information-schema.html
简单一点查看几个元数据:
SELECT VERSION();
-- 5.7.28 MySQL服务器版本信息
SELECT DATABASE();
-- (NULL) 当前数据库名 (或者返回空)
SELECT USER();
-- zlxxtest@192.168.16.110
SHOW STATUS;
-- 服务器状态,默认根据Variable_name字典顺序排下来
-- 比如Aborted_clients...Binlog_cache_disk_use...Com_alter_db...Delayed_insert_threads...Flush_commands...Handler_commit...Innodb_buffer_pool_dump_status...Threads_running...
SHOW VARIABLES;
-- 服务器配置变量
-- version就是服务器配置变量的一部分 value是5.7.28
MySQL元数据信息存储在数据库information_schema
下面的有关表里面:
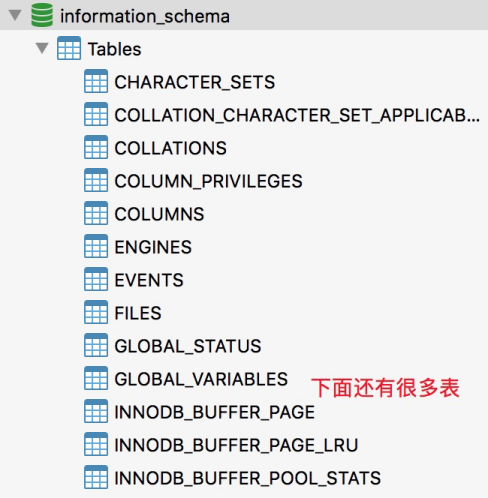
比如有哪些数据表
:
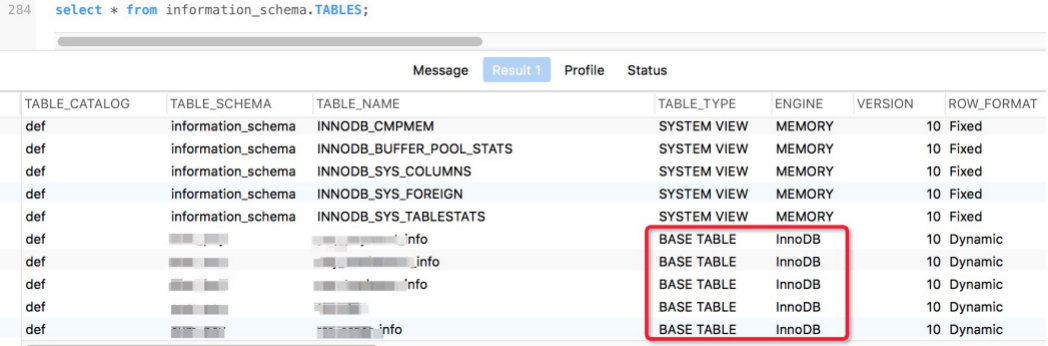
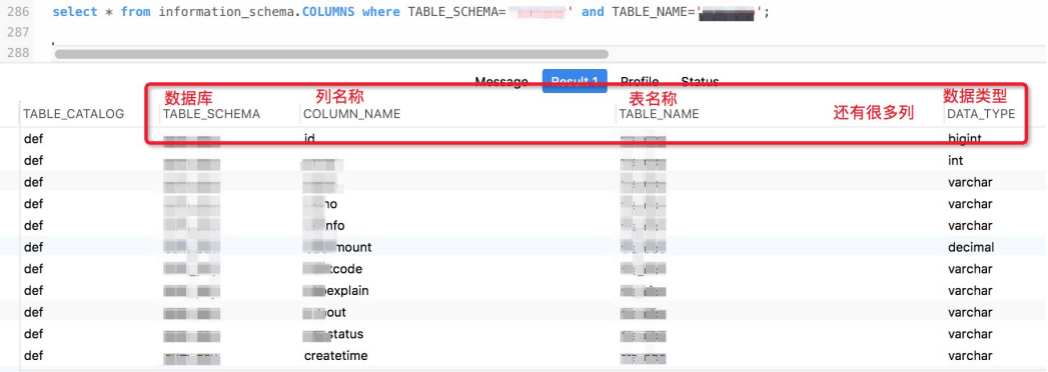
比如有哪些列
:
在Hive
中,有hivemetastore,元数据存储在可选的如MySQL数据库中:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.16.110:3306/hive_to_mysql?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
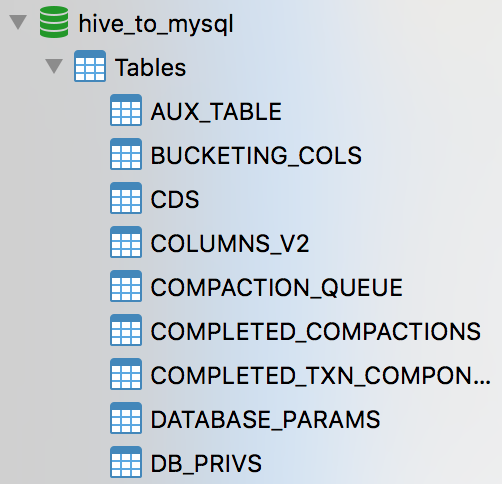
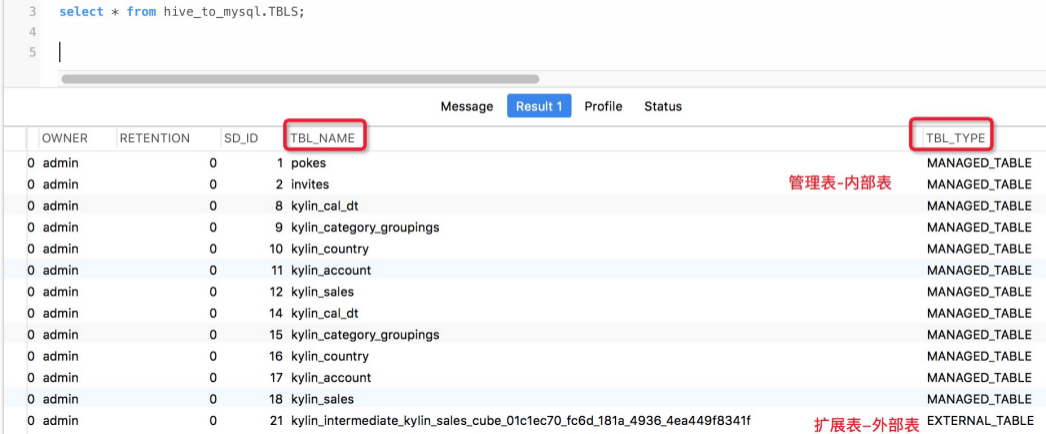
比如Hive中创建了哪些hive表
:
2. 认识Apache Atlas
之前有过一篇关于Atlas的文章分享【元数据管理之Apache Atlas简介】。
Apache Atlas是一组可扩展的核心基础治理服务——使企业能够有效地、高效地满足基于Hadoop生态的数据治理需求,并允许与整个企业数据生态系统集成
。Apache Atals为行业内个企业或组织提供开放的元数据管理和治理能力
,以构建其数据资产目录,对这些资产进行分类和治理,并为数据科学家、数据分析师、数据治理团队提供围绕这些数据资产的协作能力。
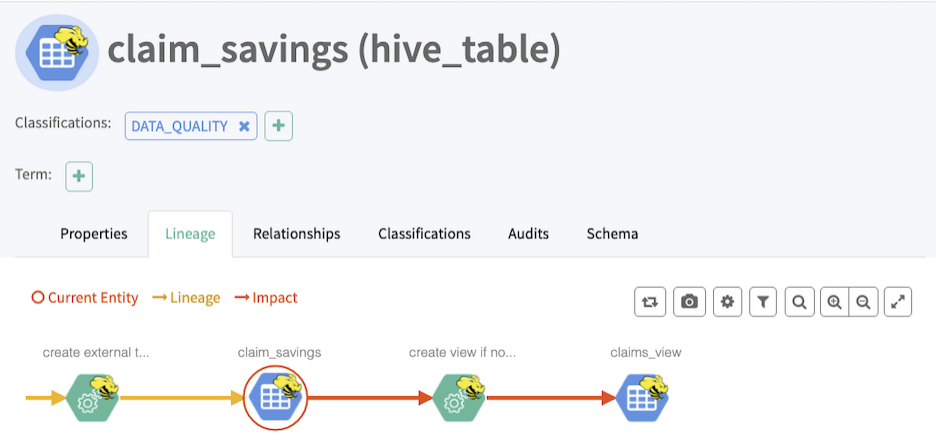
如Hive表与表之间的血缘关系
3. Atlas架构原理
https://atlas.apache.org/#/Architecture
官方图:
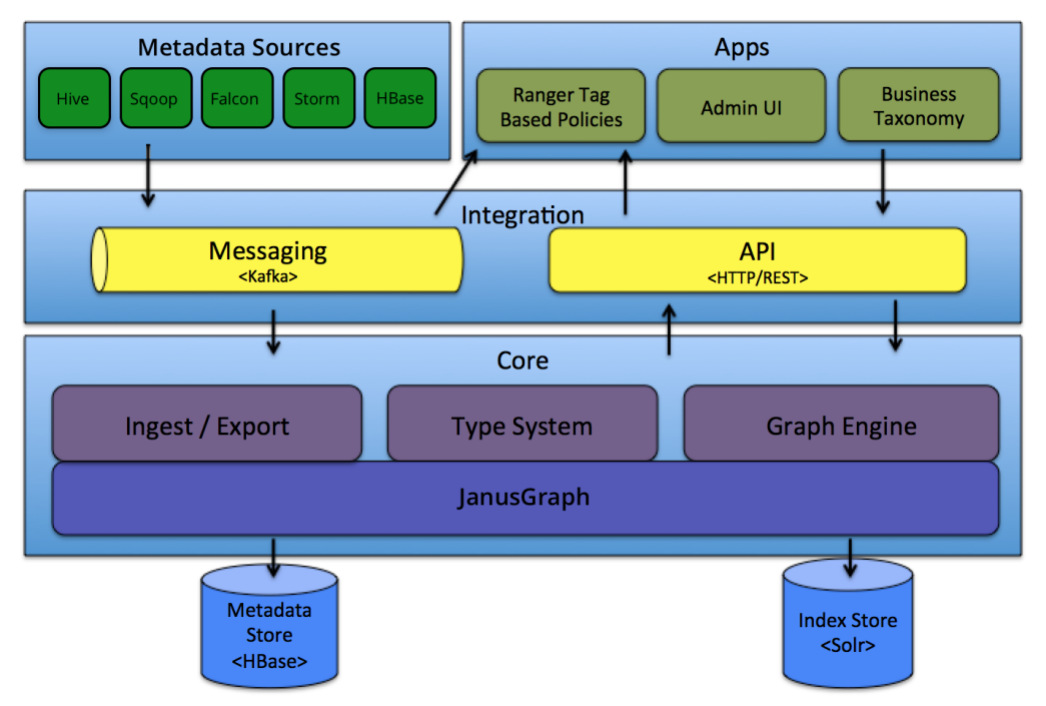
Atlas Core由三个核心组件组成
Type System:Atlas允许用户为他们想要管理的元数据对象定义模型。这个模型由称为“类型”的定义组成。 被称为“实体”的“类型”实例
用来表示被管理的实际元数据对象
。类型系统是允许用户定义和管理类型和实体的组件。由Atlas管理的所有开箱即用的元数据对象(比如Hive表)都使用类型建模并表示为实体。要在Atlas中存储新的元数据类型,需要理解类型系统组件的概念。有一个非常重要的点,Atlas中建模的通用性允许数据管理员和集成人员分别定义技术元数据
和业务元数据
。还可以使用Atlas的特性在这两者之间定义丰富的关系。Graph Engine:图形引擎,图模型,这种方法提供了很大的灵活性,并且能够有效地处理元数据对象之间的丰富关系。`图引擎组件负责在 Atlas类型系统的类型和实体
以及底层图持久化模型
之间进行转换。除了管理图对象之外,图引擎还为元数据对象创建适当的索引
,以便有效地搜索到它们。正如上图所示,Atlas使用JanusGraph
存储元数据对象。Ingest Export:采集或摄取/导出,Ingest组件允许将元数据添加到Atlas。类似地,导出组件Export将Atlas检测到的元数据变更公开为事件。使用者可以使用这些变更事件实时响应元数据变更。
Integration层,集成各种元数据来源,如上图,在Atlas中有两种方式来管理元数据
API(HTTP/REST),通过REST API对Atlas类型和实体进行创建、更新、删除、查询、发现和管理。 Messaging(Kafka),除了API,用户还可以选择使用基于Kafka的消息接口与Atlas集成。这对于将元数据对象与Atlas进行通信非常有用,对于使用Atlas中的元数据变更事件来构建应用程序也非常有用。如果希望 与Atlas进行更松散耦合的集成,从而实现更好的可伸缩性、可靠性
等,那么消息传递接口就特别有用。Atlas使用Apache Kafka作为消息通知服务器,用于hooks和元数据通知事件的下游使用者
之间的通信。事件是由hooks和Atlas写入不同的Kafka主题中。
Metadata sources,元数据来源
:
Atlas支持与许多开箱即用的元数据源
集成。将来还会添加更多的元数据源集成。目前,Atlas支持从以下来源摄取(采集)和管理元数据:HBase
、Hive
、Sqoop
、Storm
、Kafka
。集成
意味着两件事:
存在Atlas本地定义的元数据模型,以表示这些组件的对象。 Atlas提供了从这些组件中摄取元数据对象的组件(在某些情况下以实时或批处理方式)。
Apps,上层应用(Atlas Admin UI等):
Atlas管理的元数据被各种应用使用,以满足更多的治理需求。
Atlas Admin UI:这个组件是一个web应用,允许数据管理员和数据科学家通过图形界面的形式发现和标注元数据。这里最重要的是搜索界面和类似SQL的查询语言,可用于查询Atlas管理的元数据类型和对象。Admin UI上的各个功能是使用Atlas的REST API来构建的。 Tag Based Policies,基于标签的策略:Apache Ranger是Hadoop生态系统的高级安全管理解决方案,与各种Hadoop组件进行了广泛集成。通过与Atlas集成,Ranger允许安全管理员定义元数据驱动的安全策略,以实现有效的治理。Ranger会消费来自Atlas元数据变更事件的消息通知。
https://ranger.apache.org/
Apache Ranger is a framework to enable, monitor and manage comprehensive data security across the Hadoop platform.
4. Apache Atlas2.1新特性
新特性
快速搜索
:提供更简单的搜索体验与类型推断业务元数据
:支持使用附加属性扩充实体类型,并使用这些属性搜索实体标签
:能够在实体上添加/删除标签,并使用标签搜索实体自定义属性
:能够添加特定于实体实例的自定义属性。即未在实体定义或业务元数据中定义的属性实体清除
:添加了REST API来清除被删除的实体
功能增强
搜索
:能够通过多个分类找到实体性能
:血缘检索和分类传播方面的改进
消息通知
能够处理来自多个Kafka主题通知的能力 引入shell实体来记录通知中对不存在实体的引用
Hive Hook
通过 hive_process_execution
实体来执行跟踪过程通过 hive_db_ddl
和hive_table_ddl
实体捕获DDL操作
Spark
添加模型以捕获Spark实体、流程和关系
AWS S3:引入了更新的模型来捕获AWS S3实体和关系
ADLS-Gen2:引入了捕获Azure数据湖Gen2实体和关系的模型
依赖关系:JanusGraph 0.5.1、Tinkerpop 3.4.6、Spring Framework 4.3.20
授权:更新以涵盖新功能,如:业务元数据、标签、清除
UI:多个UI改进,包括测试版UI
其它JIRAS列表(略)
猜你喜欢

点一下,代码无 Bug

