




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
MIT6.824分布式系统(2020春)及MapReduce
内容提要
1.6.824课程内容
2.Go programming language
3.分布式系统
4.MapReduce
5.分布式MapReduce
6.容错机制
7.课程MR实现思路
6.824是MIT(麻省理工)的一个
计算机课程(研究生)
,课程主题是分布式系统
。
1. 6.824课程内容
官网课程表
https://pdos.csail.mit.edu/6.824/schedule.html
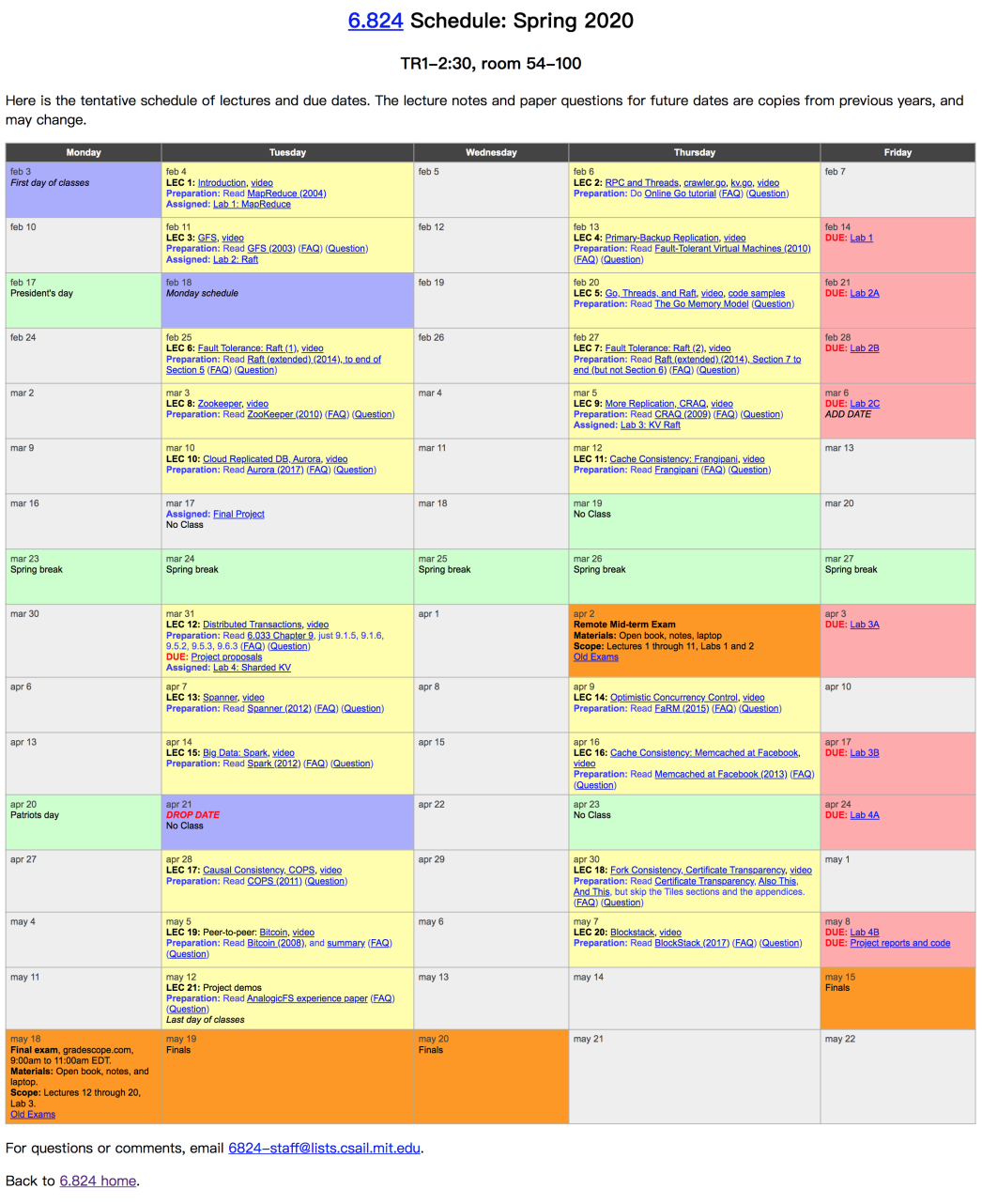
基本上每次课都需要读一篇分布式领域的论文。这里有一篇读论文的基本方法:How to Read a Paper
【文末有附图】。
http://web.mit.edu/6.829/www/currentsemester/papers/howtoread.pdf
本课程需要完成4个实验项目,分别是:
Lab 1
: 实现MapReduceLab 2
: 实现Raft
分布式共识算法Lab 3
: 基于Raft
实现一个Fault Tolerance
(容错机制)的Key-Value
存储服务Lab 4
: 实现一个可分片分区的Key-Value
存储服务
每个项目都附有完整的测试。
Go programming language
本课程的实验项目都是基于Go
语言的,需要快速了解Go的基本编程语法和数据结构,上手后遇到问题再查相关文档或手册,在线学习网站:
http://tour.golang.org/
也可以部署到本地:
$ go get golang.org/x/tour
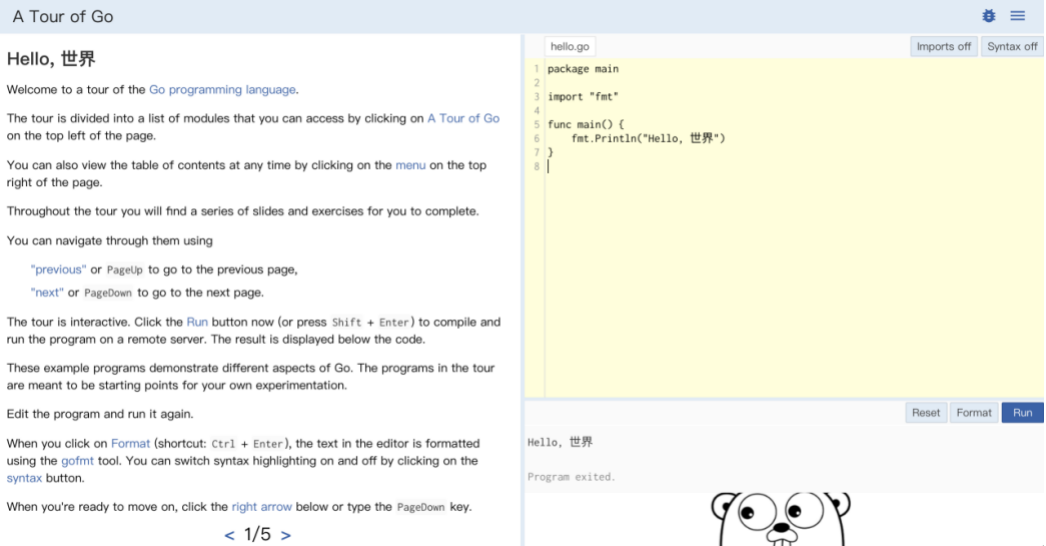
IDE,可以使用GoLand进行开发

Mac的话可以使用brew进行安装
# Go 1.15 (August 2020)
# Go 1.14 (February 2020)
$ go version
go version go1.14.7 darwin/amd64
分布式系统
分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。【百科】
因为分布式系统是部署在多台服务器上的,因此需要通过网络来进行通信
,但网络本质上是不可靠的,通过网络发送的消息可能会出现延迟、乱序甚至丢失,所以基于一个不可靠的通信通道来建立一个可靠的系统就需要解决各种状态不一致的问题。
让分布式系统中各个节点对某个值达成一致的算法叫作分布式共识算法
,这些算法中比较出名的有Paxos
、Raft
以及ZooKeeper使用的ZAB
等等。
MapReduce
课程的Lab 1
,是在单机上模拟出一个分布式环境,节点间使用RPC
进行通信,共同完成一个完整的MapReduce任务。
MapReduce是Google提出的一个用于并行处理大规模数据的编程模型,由map和reduce两个函数组成,在JDK8+的Stream里面看看类似的函数:
java.util.stream.Stream.java
/**
* Returns a stream consisting of the results of applying the given
* function to the elements of this stream.
* @return the new stream
*/
<R> Stream<R> map(Function<? super T, ? extends R> mapper)
/**
* reduction on the
* elements of this stream, using an
* associative accumulation
* function, and returns an describing the reduced value,
* if any. This is equivalent to:
* boolean foundAny = false;
* T result = null;
* for (T element : this stream) {
* if (!foundAny) {
* foundAny = true;
* result = element;
* }
* else
* result = accumulator.apply(result, element);
* }
* return foundAny ? Optional.of(result) : Optional.empty();
* }
*
* but is not constrained to execute sequentially.
*/
Optional<T> reduce(BinaryOperator<T> accumulator);
map是接收一个数据集作为输入,然后对数据集中的每一个数据进行某种变换 Transformation
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream()
.map(i -> i * i)
.forEach(System.out::println);
// 对数据集中的每个数据求平方
1
4
9
16
25
reduce同样接收一个数据集作为输入,将数据集中的所有数据进行聚合
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream()
.reduce((i, j) -> i + j)
.ifPresent(System.out::println);
// 对数据集中所有数据进行求和
15
使用map进行平方运算,再使用reduce对平方运算后的值进行求和
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream()
.map(i -> i * i)
.reduce((i, j) -> i + j)
.ifPresent(System.out::println);
// 对数据集中的每个数据进行平方后求和
55
使用伪代码来表示map和reduce的输入输出:
map (k1, v1) --> list(k2, v2)
reduce (k2, list(v2)) --> list(k3, v3)
Hadoop-MapReduce
中的map和reduce(MR1 API): 包:org.apache.hadoop.mapred
// public interface Mapper
void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter)
throws IOException;
// public interface Reducer
void reduce(K2 key, Iterator<V2> values,
OutputCollector<K3, V3> output, Reporter reporter)
throws IOException;
map函数的输入是一对Key/Value,函数内部将这对Key/Value进行某种处理变换,然后输出一个新的Key/Value集合。reduce函数的输入是map函数的输出,将同一个Key对应的Value集合聚合起来,最终输出一个新的集合。
wordcount示例:
// 读取文件内容,每遇到一个单词,就生成一个
// <单词,1>(这里的1表示单词出现次数)
map(String documentName, String content):
for each word in content:
GenerateIntermediate(word, "1");
// 根据同一个Key(单词)将所有的Value(出现次数)构造一个集合
// 传入reduce
// reduce将统计单词的出现次数
reduce(String word, Iterator count):
int totalCount = 0;
for each x in count:
totalCount += AsInt(x);
Generate(AsString(totalCount))
分布式MapReduce
在分布式环境中,一个完整的MapReduce任务可能运行在几百上千台服务器上面,这样才能发挥出MapReduce最强大的性能。其中一台服务器运行着Master用于调度任务
,而其他服务器则运行着Worker
执行Map和Reduce任务处理数据。
Map任务的输出保存在服务器的文件系统中,并将这些文件的位置告知Master,然后Master负责将这些文件位置转发给Worker,最后Worker通过网络调用获取文件内容并执行Reduce任务输出最终结果。
容错机制
执行任务的机器越多越复杂,机器故障、网络故障等等,需要有容错机制来保障最终计算结果的正确性。
Worker故障
Master会与每个Worker维持一个心跳
,如果超过指定时间没有收到某个 Worker的心跳,就将该Worker标记为故障。故障Worker已完成的Map任务则会被重置并重新分配给其他Worker,已完成的Map任务之所以需要重新分配,是因为 Map任务的输出文件是保存在Worker所在机器本地的,因此Worker故障时这些文件可能也无法获取。但Reduce任务的输出是保存在另外的全局文件系统的,因此不需要重新执行。而已分配到故障Worker但还未完成的任务,无论是Map还是Reduce任务,都需要标记为未执行并重新分配。Master故障
Master会周期性地保存系统状态,比如记录已完成和未完成的任务。因此当Master出现故障时,可以启动一个新的Master,读取上一次的系统状态并继续执行任务。
课程MR实现思路
文档:
https://pdos.csail.mit.edu/6.824/labs/lab-mr.html
MapReduce论文:
http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf
会介绍环境准备,比如macOS brew install go
等。
思路:
实现单Worker进程且单文件输入,即只启动单个Worker进程,且Master进程启动时只传入一个文本文件。首先Worker向Master请求得到一个map任务,处理完之后再次请求得到一个reduce任务,最后输出结果文件。 实现单Worker进程且多文件输入,即Master启动时传入所有的文本文件。这里要注意Master向Worker派发任务时,要确认所有的map任务已经完成后才可以开始派发reduce任务。 实现多Worker进程且多文件输入,此时会有多个Worker进程同时与Master通信的情况,所以需要对Master的共享状态做好同步,可以打开测试脚本中的RACE=-race来检测程序是否有并发问题。 实现Worker任务处理超时或者进程崩溃退出的情况,所以需要在派发任务时记录时间,如超过规定时间任务还未完成,则应该将任务派发给另一个Worker进程。
单Worker进程的测试步骤:
# 单Worker进程测试步骤
go build --buildmode=plugin ../mrapps/wc.go
# 生成正确的处理结果,最后一个文件名参数改成pg-*.txt即可将所有文本作为输入
go run mrsequential.go wc.so pg-being_ernest.txt
sort mr-out-0 > mr-correct-wc.txt
rm -f mr-out*
# 启动master进程,最后一个文件名参数需与上一步的参数保持一致
go run mrmaster.go pg-being_ernest.txt
# 在一个新的命令行窗口启动worker进程,并生成处理结果
go run mrworker.go wc.so
sort mr-out* | grep . > mr-wc-all
# 比较两个处理结果,如果输出PASS则说明实现正确
cmp mr-wc-all mr-correct-wc.txt && echo PASS
# 删除临时文件
rm -f mr-*
Getting started
初始化实验环境
$ git clone git://g.csail.mit.edu/6.824-golabs-2020 6.824
Cloning into '6.824'...
...
Resolving deltas: 100% (122/122), done.
src/main/mrsequential.go
提供了一个简单的mapreduce实现;还提供了单词计数mrapps/wc.go
,简单运行起来:
$ cd 6.824/
$ ls
Makefile src
$ cd src/main
$ go build -buildmode=plugin ../mrapps/wc.go
$ rm mr-out*
rm: mr-out*: No such file or directory
$ go run mrsequential.go wc.so pg*.txt
$ more mr-out-0
A 509
ABOUT 2
ACT 8
ACTRESS 1
ACTUAL 8
ADLER 1
ADVENTURE 12
...
mrapps/wc.go
源码:
package main
//
// a word-count application "plugin" for MapReduce.
//
// go build -buildmode=plugin wc.go
//
import "../mr"
import "unicode"
import "strings"
import "strconv"
//
// The map function is called once for each file of input. The first
// argument is the name of the input file, and the second is the
// file's complete contents. You should ignore the input file name,
// and look only at the contents argument. The return value is a slice
// of key/value pairs.
//
func Map(filename string, contents string) []mr.KeyValue {
// function to detect word separators.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// split contents into an array of words.
words := strings.FieldsFunc(contents, ff)
kva := []mr.KeyValue{}
for _, w := range words {
kv := mr.KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}
//
// The reduce function is called once for each key generated by the
// map tasks, with a list of all the values created for that key by
// any map task.
//
func Reduce(key string, values []string) string {
// return the number of occurrences of this word.
return strconv.Itoa(len(values))
}
附图:如何阅读


bilibili视频地址:
https://www.bilibili.com/video/av87684880?zw

