




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。

前言
https://www.yugabyte.com/
https://github.com/yugabyte/yugabyte-db
https://docs.yugabyte.com/
Spanner论文(中文版)点击文末阅读原文可以下载PDF
YugabyteDB是一个全球部署的分布式数据库,和国内的TiDB及国外的CockroachDB类似,也是受到Google Spanner论文启发,所以在很多地方这几个数据库存在不少相似之处。
与CockroachDB类似,YugabyteDB也主打全球分布式的事务数据库——不仅能把节点部署到全球各地,还能完整支持ACID事务,这是他最大的卖点。除此以外还有一些独特的特性,比如支持文档数据库接口。
系统架构
逻辑上,YugabyteDB采用两层架构:查询层和存储层。不过这个架构仅仅是逻辑上的,物理部署架构中,这两层都位于TServer进程中。这一点和TiDB不同。
YugabyteDB的查询层支持SQL和CQL两种API,其中CQL是兼容Cassandra的一种方言语法,对应于文档数据库的存储模型;而SQL API是直接基于PostgresQL修改的,能比较好地兼容PG语法,据官方说这样可以更方便地持续兼容PG新特性。
YugabyteDB的存储层,其中TServer负责存储tablet,每个tablet对应一个Raft Group,分布在三个不同的节点上,以此保证高可用。Master负责元数据管理,除了tablet的位置信息,还包括表结构等信息。Master本身也依靠Raft实现高可用。
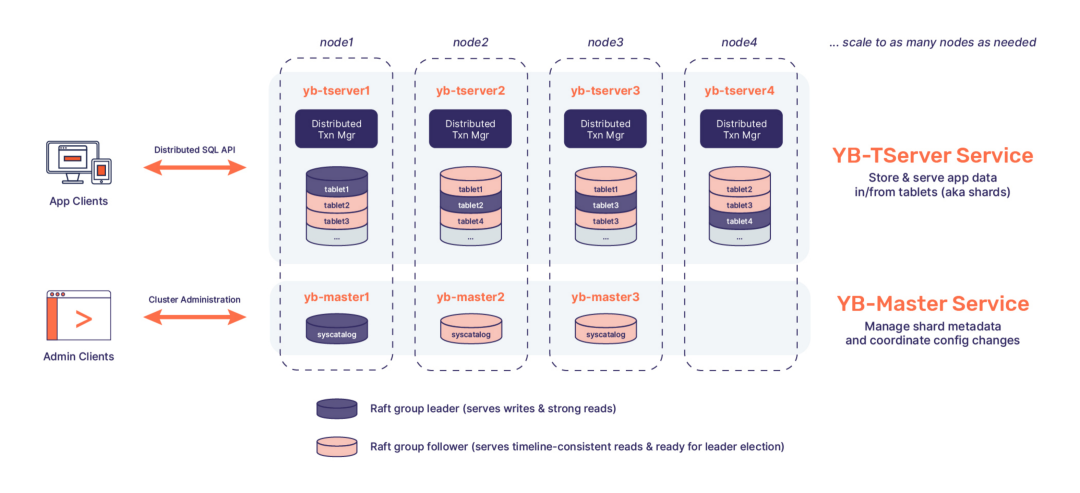
基于tablet的分布式存储
这一部分是HBase/Spanner精髓部分,CockroachDB/TiDB的做法几乎也是一模一样的。如下图,每张表被分成很多个tablet,tablet是数据分布的最小单元。通过在节点间搬运tablet以及tablet的分裂与合并,就可以实现几乎无上限的 scale out。每个tablet有多个副本,形成一个Raft Group,通过Raft协议保证数据的高可用和持久性,Group Leader负责处理所有的写入负载,其他Follower作为备份。
下图是一个例子:一张表被分成16个tablet,tablet的副本和Raft Group leader均匀分布在各个节点上,分别保证了数据的均衡和负载的均衡。
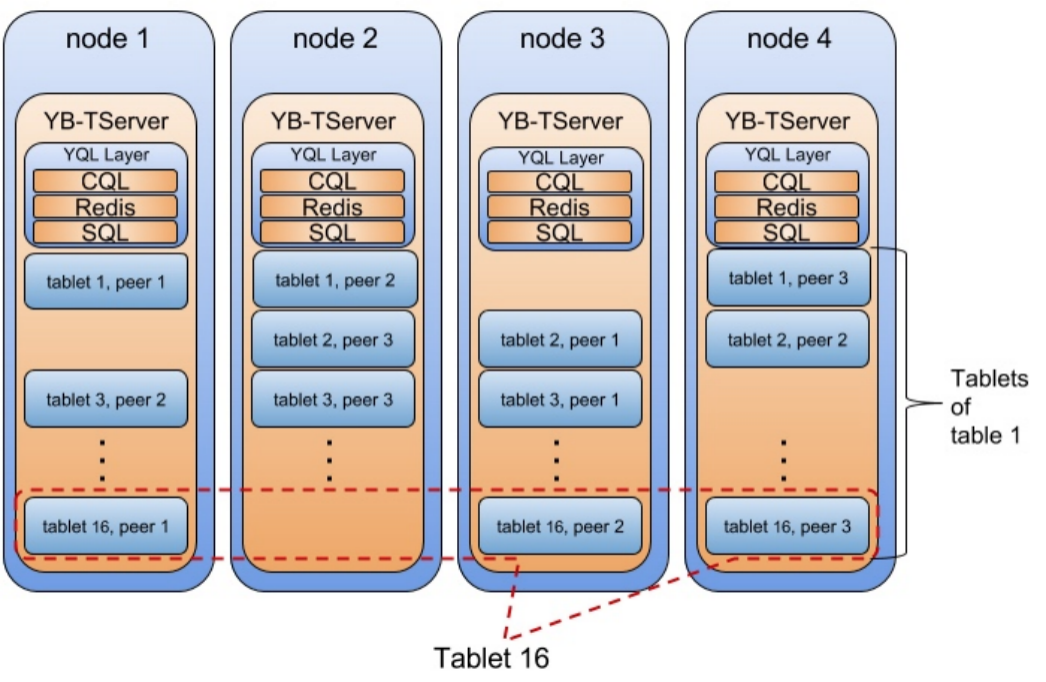
和其他产品一样,Master节点会负责协调tablet的搬运、分裂等操作,保证集群的负载均衡。这些操作是直接基于Raft Group实现的。
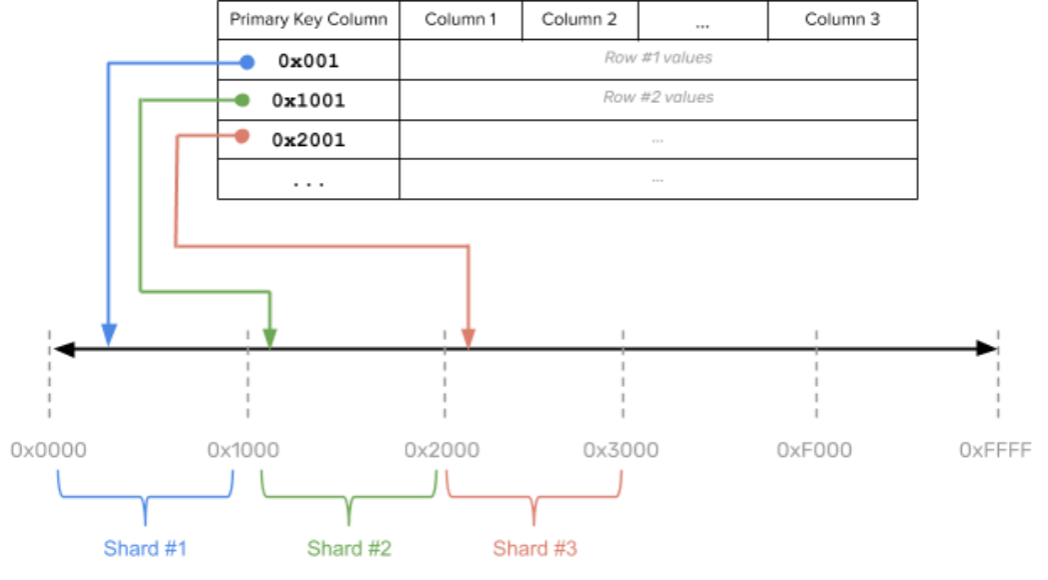
在数据分区或分片上,YugabyteDB当前支持两种数据分片方式:一致性hash分片和范围分片。
For every given key, there is exactly one tablet that owns it.
YugabyteDB currently supports two ways of sharding data - hash (aka consistent hash) sharding and range sharding.
哈希方式是将key哈希映射到2个字节的空间中(即0x0000
到0xFFFF
),这个空间又被划分成多个子范围,比如下图的例子中被划分为16个子范围([0x0000, 0x1000), [0x1000, 0x2000), … , [0xF000, 0xFFFF]
),每个子范围的key落在一个tablet中。理论上说最多可能有64K个tablet,这对实际使用足够了。
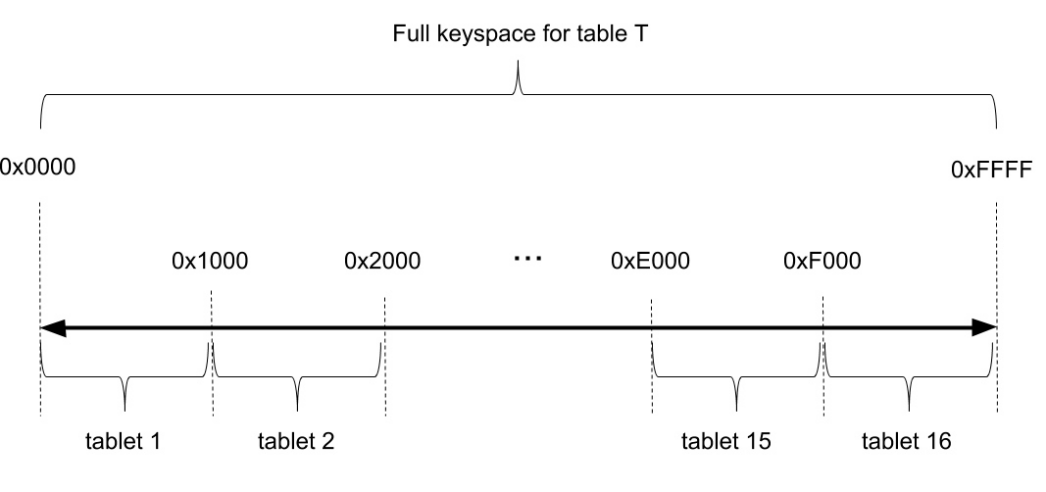
哈希的好处是插入数据(尤其是从尾部append数据)时不会出现热点;坏处是对于小范围的范围扫描(例如pk BETWEEN 1 AND 10)性能会比较吃亏。
Hash-sharded tables
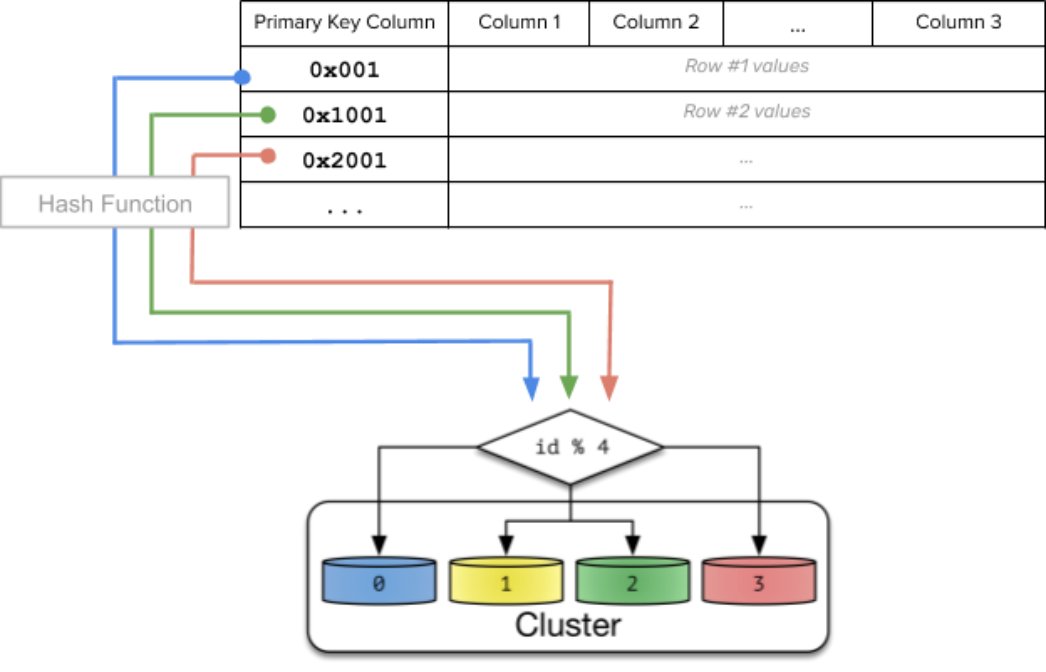
hash分片创建表示例:
-- hash的字段:customer_id
CREATE TABLE customers (
customer_id bpchar NOT NULL,
company_name character varying(40) NOT NULL,
contact_name character varying(30),
contact_title character varying(30),
address character varying(60),
city character varying(15),
region character varying(15),
postal_code character varying(10),
country character varying(15),
phone character varying(24),
fax character varying(24),
PRIMARY KEY (customer_id HASH)
) SPLIT INTO 16 TABLETS;
Range-sharded tables
-- 范围分区的字段:customer_id ASC
CREATE TABLE customers (
customer_id bpchar NOT NULL,
company_name character varying(40) NOT NULL,
contact_name character varying(30),
contact_title character varying(30),
address character varying(60),
city character varying(15),
region character varying(15),
postal_code character varying(10),
country character varying(15),
phone character varying(24),
fax character varying(24),
PRIMARY KEY (customer_id ASC)
) SPLIT AT ((1000), (2000), (3000), ... );
基于 RocksDB 的本地存储
每个TServer节点上的本地存储称为DocDB。和TiDB/CockroachDB一样,YugabyteDB也用RocksDB来做本地存储。这一层需要将关系型tuple以及文档编码为key-value保存到RocksDB 中,下图是对文档数据的编码方式,其中有不少是为了兼容Cassandra设计的,我们忽略这些,主要关注以下几个部分:
key中包含:
16-bit hash:依靠这个值才能做到哈希分区 主键数据(对应图中hash/range columns) column ID:因为每个tuple有多个列,每个列在这里需要用一个key-value来表示 hybrid timestamp:用于MVCC的时间戳
value中包含: column的值
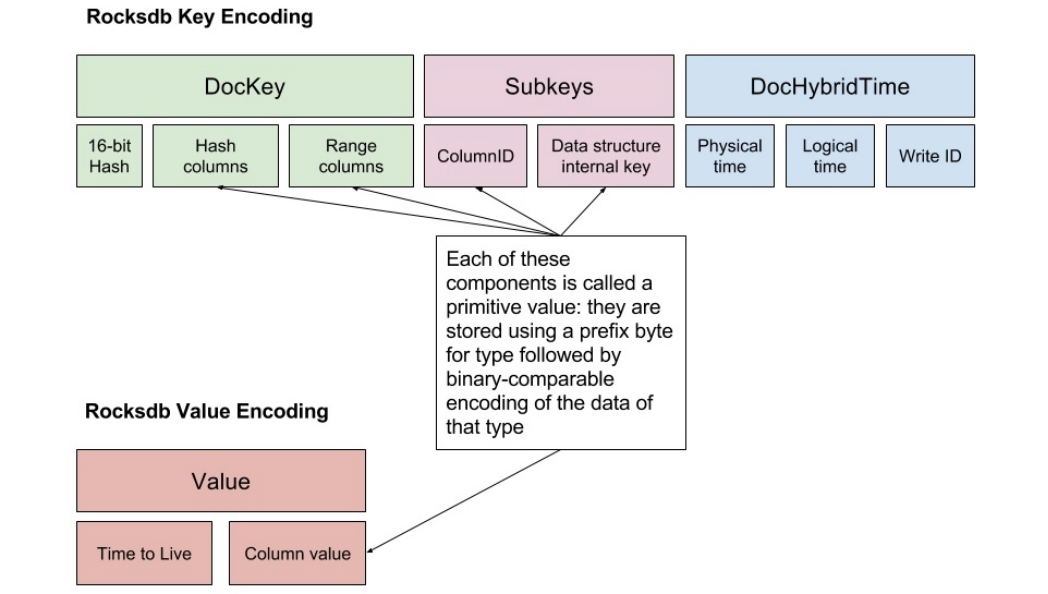
如果撇开文档模型,key-value的设计很像CockroachDB:每个cell(一行中的一列数据)对应一个key-value。而TiDB是每个tuple打包成一个key-value。个人比较偏好TiDB的做法。
分布式事务:2PC & MVCC
和TiDB/CockroachDB一样,YugabyteDB也采用了MVCC结合2PC的事务实现。
时间戳
时间戳是分布式事务的关键选型之一。YugabyteDB和CockroachDB一样选择的是 Hybrid Logical Clock (HLC)。
HLC将时间戳分成物理(高位)和逻辑(低位)两部分,物理部分对应UNIX时间戳,逻辑部分对应Lamport时钟。在同一毫秒以内,物理时钟不变,而逻辑时钟就和 Lamport时钟一样处理——每当发生信息交换(RPC)就需要更新时间戳,从而确保操作与操作之间能够形成一个偏序
关系;当下一个毫秒到来时,逻辑时钟部分归零。
HLC的正确性其实是由Logical Clock来保证的:在每个毫秒引入了一个额外的增量,不会破坏Logical Clock的正确性。但是,物理部分的存在将原本无意义的时间戳赋予了物理意义,提高了实用性。
另一种方案是引入中心授时节点(TSO),也就是TiDB使用的方案。TSO方案要求所有事务必须从TSO获取时间戳,实现相对简单,但引入了更多的网络RPC,而且 TSO过于关键——短时间的不可用也是极为危险的。
HLC的实现中有一些很tricky的地方,比如文档中提到的Safe timestamp assignment for a read request。对于同一事务中的多次read,问题还要更复杂,有兴趣的读者可以看CockroachDB团队的这篇博客Living Without Atomic Clocks。
https://docs.yugabyte.com/latest/architecture/transactions/single-row-transactions/#safe-timestamp-assignment-for-a-read-request
https://www.cockroachlabs.com/blog/living-without-atomic-clocks/Cloud Spanner:TrueTime 和外部一致性
https://cloud.google.com/spanner/docs/true-time-external-consistency
事务提交
YugabyteDB的分布式事务同样是基于2PC的。做法接近CockroachDB。事务提交过程中,会在DocDB存储里面写入一些临时的记录(provisional records),包括以下三种类型:
Primary provisional records:还未提交完成的数据,多了一个事务ID,也扮演锁的角色 Transaction metadata:事务状态所在的tablet ID。因为事务状态表很特殊,不是按照hash key分片的,所以需要在这里记录一下它的位置。 Reverse Index:所有本事务中的primary provisional records,便于恢复使用
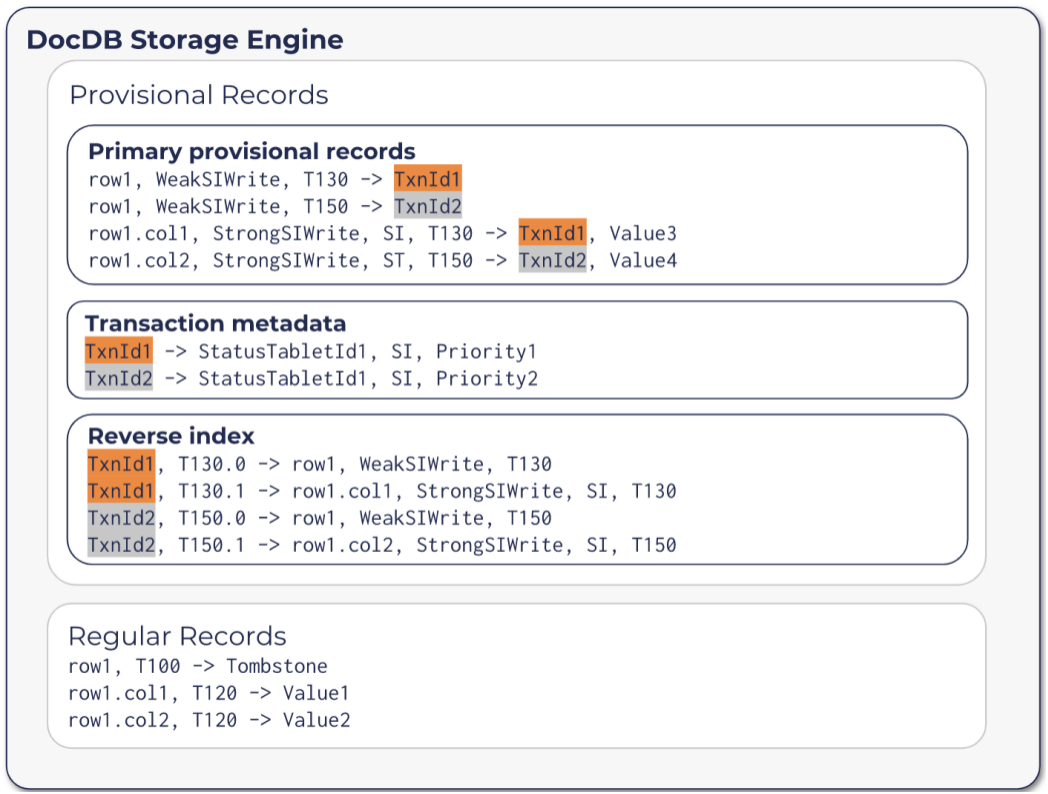
事务的状态信息保存在另一个tablet上,包括三种可能的状态:Pending、Committed或Aborted。事务从Pending状态开始,终结于Committed或Aborted。
事务状态就是Commit Point的那个“开关”,当事务状态切换到Commited的一瞬间,就意味着事务的成功提交。这是保证整个事务原子性的关键。
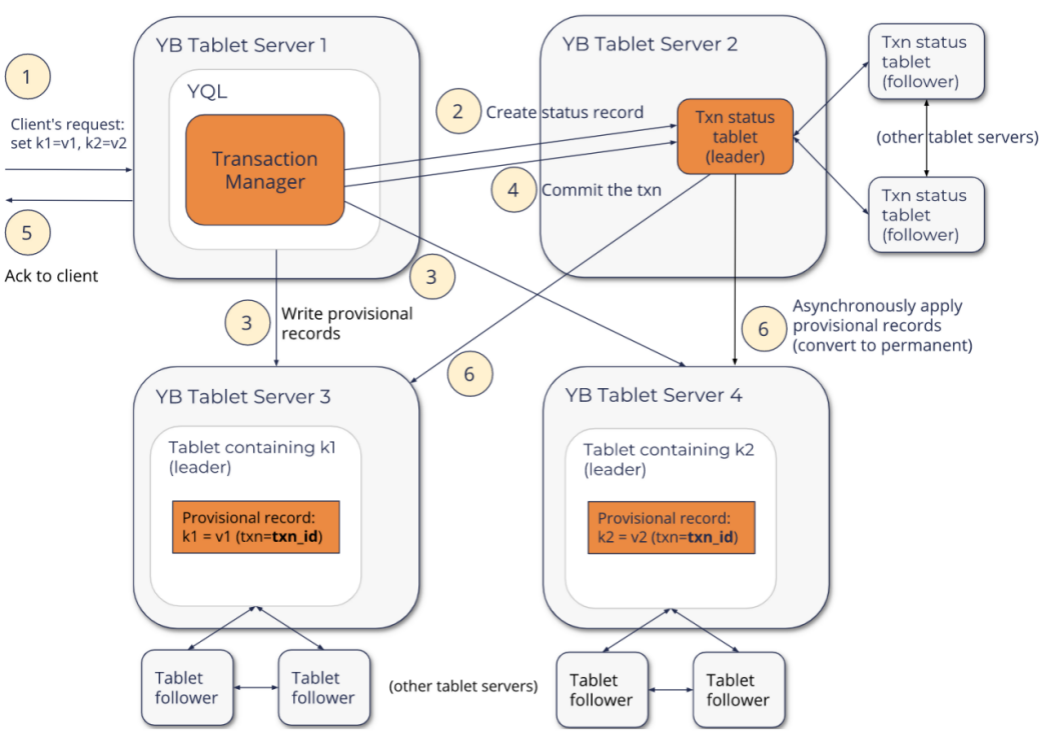
完整的提交流程如下图所示:
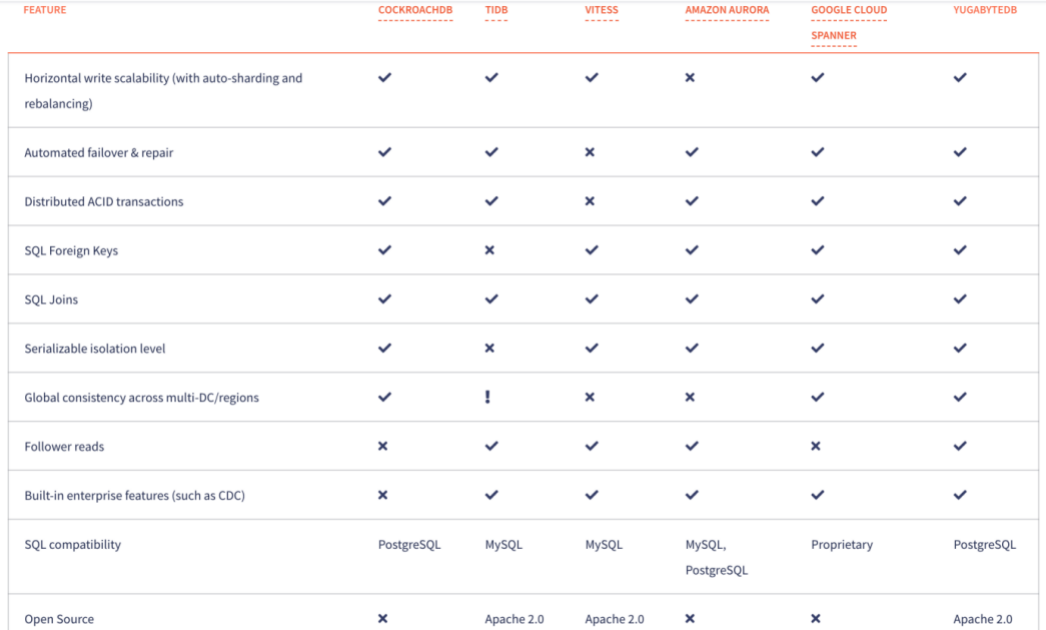
竞品对比
https://docs.yugabyte.com/latest/comparisons/
- END -

