




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
7问Impala
1. Impala有什么特点?
https://github.com/cloudera/Impala

基于内存进⾏计算,能够对PB级数据进⾏交互式实时查询、分析 ⽆需转换为MR,直接读取HDFS数据 C++编写,LLVM统⼀编译运⾏ 兼容HiveSQL 具有数据仓库的特性 可对hive数据直接做数据分析 ⽀持列式存储 ⽀持Data Local ⽀持JDBC/ODBC远程访问
2. Impala有哪些核⼼组件?
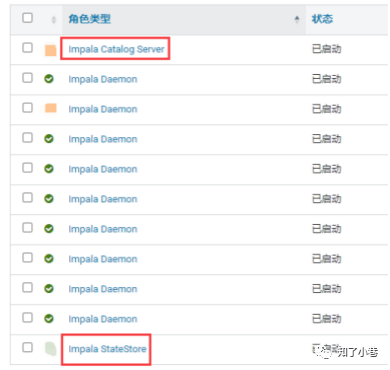
CDH-Impala
The Impala server is a distributed, massively parallel processing (MPP) database engine. It consists of different daemon processes that run on specific hosts within your CDH cluster.
The Impala Daemon
The Impala Statestore
The Impala Catalog Service
Statestore Daemon
实例:1个statestored 负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息。
负责query的调度
Catalog Daemon
实例:1个catalogd
分发表的元数据信息到各个impalad中;
接收来⾃statestore的所有请求
Impala Daemon
(具有数据本地化的特性所以放在DataNode上)
实例:N个impalad
接收client、hue、jdbc或者odbc请求、Query执⾏并返回给中⼼协调节点;
⼦节点上的守护进程,负责向statestore保持通信,汇报⼯作
3. Impala和Hive有什么区别?
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级⼤数据,还能查询Kudu中的数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执⾏使⽤的是MapReduce引擎(已过时,可选择使用Tez或SparkSQL),仍然是⼀个批处理过程,难以满⾜查询的交互性。相⽐之下,Impala的最⼤特点也是最⼤卖点就是它的快速。
相同点:
数据存储:使⽤相同的存储数据池都⽀持把数据存储于HDFS,HBase。
元数据:两者使⽤相同的元数据。
SQL解释处理:⽐较相似都是通过词法分析⽣成执⾏计划。不同点:
执⾏计划:
Hive: 依赖于MapReduce执⾏框架,执⾏计划分成map->shuffle->reduce->map->shuffle->reduce… 的模型。
如果⼀个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执⾏框架本身的特点,过多的中间过程会增加整个Query的执⾏时间。
Impala: 把执⾏计划表现为⼀棵完整的执⾏计划树,可以更⾃然地分发执⾏计划到各个Impalad执⾏查询,⽽不⽤像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。数据流:
Hive: 采⽤推的⽅式,每⼀个计算节点计算完成后将数据主动推给后续节点。
Impala: 采⽤拉的⽅式,后续节点通过getNext主动向前⾯节点要数据,以此⽅式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以⽴即展现出来,⽽不⽤等到全部处理完成,更符合SQL交互式查询使⽤。内存使⽤:
Hive: 在执⾏过程中如果内存放不下所有数据,则会使⽤外存,以保证Query能顺序执⾏完。每⼀轮MapReduce结束,中间结果也会写⼊HDFS中,同样由于MapReduce执⾏架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,版本0.1是直接返回错误,⽽不会利⽤外存,以后版本应该会进⾏改进。(内存不够,会有Memorylimit exceeded)Impala⽬前处理Query会受到⼀定的限制,最好还是与Hive配合使⽤。Impala在多个阶段之间利⽤⽹络传输数据,在执⾏过程不会有写磁盘的操作(insert除外)。
DISABLE_UNSAFE_SPILLS Query Option (CDH 5.2 or higher only)
为了避免因为内存溢出而直接查询失败,可以将中间数据溢出到磁盘。
https://docs.cloudera.com/documentation/enterprise/latest/topics/impala_scalability.html#spill_to_disk
调度:
Hive: 任务调度依赖于Hadoop的调度策略。
Impala: 调度由⾃⼰完成,⽬前只有⼀种调度器SimpleScheduler,它会尽量满⾜数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器⽬前还⽐较简单,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,⽹络IO状况等因素进⾏调度。但⽬前Impala已经有对执⾏过程的性能统计分析,应该以后版本会利⽤这些统计信息进⾏调度吧。
https://github.com/AtScaleInc/Impala/blob/master/be/src/statestore/simple-scheduler.cc容错:
Hive: 依赖于Hadoop的容错能⼒。
Impala: 在查询过程中,没有容错逻辑,如果在执⾏过程中发⽣故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,⼀次查询失败,再查⼀次就好了,再查⼀次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,⽤户可以向任何⼀个Impalad提交查询,如果⼀个Impalad失效,其上正在运⾏的所有Query都将失败,但⽤户可以重新提交查询由其它Impalad代替执⾏,不会影响服务。对于StateStore⽬前只有⼀个,但当StateStore失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能再更新集群状态,有可能会把执⾏任务分配给已经失效的Impalad执⾏,导致本次Query失败。适⽤场景:
Hive: 复杂的批处理查询任务,数据转换任务。
Impala: 实时数据分析,因为不⽀持UDF,能处理的问题域有⼀定的限制,与Hive配合使⽤,对Hive的结果数据集进⾏实时分析。还可以用来查询Kudu。
https://docs.cloudera.com/documentation/enterprise/latest/topics/impala_kudu.html
4. Impala相对于Hive⽤到了什么优化技术?
Impala没有使⽤MapReduce进⾏并⾏计算,虽然MapReduce是⾮常好的并⾏计算框架,但它更多的⾯向批处理模式,⽽不是⾯向交互式的SQL执⾏。与MapReduce相⽐:Impala把整个查询分成⼀执⾏计划树,⽽不是⼀连串的MapReduce任务,在分发执⾏计划后,Impala使⽤拉式获取数据的⽅式获取结果,把结果数据组成按执⾏树流式传递汇集,减少了把中间结果写⼊磁盘的步骤,以及再从磁盘读取数据的开销。Impala使⽤服务的⽅式避免每次执⾏查询都需要启动的开销,即相⽐Hive没了MapReduce启动时间。
使⽤LLVM产⽣运⾏代码,针对特定查询⽣成特定代码,同时使⽤Inline的⽅式减少函数调⽤的开销,加快执⾏效率。
充分利⽤可⽤的硬件指令。
更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利⽤多磁盘的优势,同时Impala⽀持直接数据块读取和本地代码计算checksum。
通过选择合适的数据存储格式可以得到最好的性能(Impala⽀持多种存储格式)。
最⼤使⽤内存,中间结果不写磁盘,及时通过⽹络以stream的⽅式传递。
5. Impala优缺点?
优点:
a. ⽀持SQL查询,快速查询⼤数据。 b. 可以对已有数据进⾏查询,减少数据的加载,转换。 c. 多种存储格式可以选择(Parquet, Text, Avro, RCFile, SequeenceFile)。 d. 可以与Hive配合使⽤。
缺点:
a. 不⽀持⽤户定义函数UDF。 b. 不⽀持text域的全⽂搜索。 c. 不⽀持Transforms。 d. 不⽀持查询期的容错。 e. 对内存要求⾼。
6. Impala如何通过Hive外部表⽅式和HBase进⾏整合?
步骤1:创建HBase表,向表中添加数据
create 'test_info', 'info'
put 'test_info','1','info:name','zhangsan'
put 'test_info','2','info:name','lisi'
步骤2:创建Hive表
CREATE EXTERNAL TABLE test_info(key string,name string )
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES
("hbase.columns.mapping"=":key,info:name")
TBLPROPERTIES ("hbase.table.name" = "test_info");
步骤3:刷新Impala表
invalidate metadata
Impala性能优化?
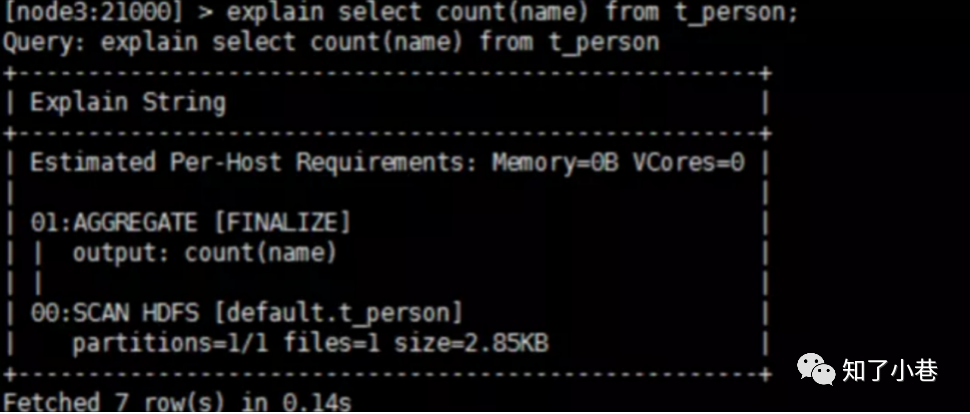
执⾏计划: 查询sql执⾏之前,先对该sql做⼀个分析,列出需要完成这⼀项查询的详细⽅案。
命令:
-- explain sql
-- profile
SQL优化,使⽤之前调⽤执⾏计划 选择合适的⽂件格式进⾏存储 避免产⽣很多⼩⽂件(如果有其他程序产⽣的⼩⽂件,可以使⽤中间表,将⼩⽂件存放到中间表然后写⼊到要执⾏的表⾥A—>V—>B) 使⽤合适的分区技术,根据分区粒度测算 使⽤compute stats进⾏表信息搜集 ⽹络io的优化:
a. 避免把整个数据发送到客户端 b. 尽可能的做条件过滤 c. 使⽤limit子句 d. 输出⽂件时,避免使⽤美化输出
使⽤profile输出底层信息计划,再做相应环境资源优化

