




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
1. MapReduce的执行流程
MR的整体执行流程:YARN模式
在MapReduce程序读取文件的输入目录上存放相应的文件。 客户端程序在submit()方法执行前,获取待处理的数据信息,然后根据集群中的参数的配置形成一个任务分配规划。 客户端提交切片信息给YARN,YARN中的ResourceManager启动MRAppMaster。 MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例对象,然后向集群申请机器启动相应数量的maptask进程。 maptask利用客户端指定的InputFormat来读取数据,形成输出的KV键值对。 maptask将输入KV键值对传递给客户定义的map()方法,做逻辑运算。 map()方法运算完成后将新的KV对收集到maptask缓存。 Shuffle阶段
1).maptask收集我们的map()方法输出的KV对,放到环形缓冲区中。 2).maptask中的KV对按照K分区排序,并不断溢写到本地磁盘文件,可能会溢出多个文件。 3).多个文件会被合并成大的溢出文件。 4).在溢写过程中,及合并过程中,都会不停地进行分区和针对K的排序操作。 5).reducetask根据自己的分区号,去各个maptask机器上获取相应的结果分区数据。 6).reducetask会取到同一个分区的来自不同maptask机器的结果文件,reducetask会将这些文件再进行归并排序。 7).合并成大文件后,Shuffle的过程也就结束了,后面进入reducetask的逻辑过程(从文件中取出一个一个的KV对group,调用用户自定义的reduce()方法)。
MRAppMaster监控到所有的maptask进程任务完成后,会根据客户端指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据分区。 reducetask进程启动后,根据MRAppMaster告知的待处理数据所在的位置,从若干台maptask运行所在机器上获取若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一组,调用程序定义的reduce()方法进行逻辑运算。 reducetask运算完毕后,调用程序指定的OutputFormat将结果数据输出到外部。
2. MapReduce程序用到的主要Java类、Mapper中的方法
关键类
GenericOptionsParser 是为Hadoop框架解析命令行参数的工具类。 InputFormat接口,它的实现类包括:FileInputFormat(抽象类)、ComposableInputFormat(接口)等,主要用于使用文件作为输入及数据切分的情况。 Mapper 将输入的KV对映射成中间数据KV对集合。map()将输入数据转换为中间数据。 Reducer 根据KV中间数据集合进行合并处理为更小的数据结果集。 Partitioner 接口,对数据按照K进行分区,比如默认的HashPartitioner。 OutputCollector 接口,文件的收集输出。 Combiner 并不存在Combiner接口或类,它就是Reducer,本地化执行聚合操作。
org.apache.hadoop.mapreduce.Mapper
Mapper的方法有setup map cleanup run
setup方法用于管理Mapper生命周期中的资源,加载一些初始化的工作,每个job只执行一次,setup在完成Mapper构造并即将开始执行map方法之前执行。 map方法,主要是逻辑运算方法。 cleanup方法,主要做一些收尾工作,如关闭文件或者执行map后的键值分发等,每个job只执行一次,比较适合计算全局最大值之类的任务。 run方法执行了上面描述的所有过程,先调用setup方法,然后执行map方法,最后执行cleanup方法。
3. 有个需求,要求一条指令可以把所有文件都Shuffle到同一个Partition中,用MapReduce怎么实现
在Driver驱动类中设置reduce数量,job.setNumReduceTasks(1)为1。
4. Hadoop Shuffle原理
MapReduce Shuffle原理
Shuffle的本质是group by,无论是单机、跨网络、走磁盘走内存...都是一样的,只要是把相同K的数据聚集在一起就是Shuffle。比如斗地主...按照某种顺序或规则将相同【规则】的牌面放在一起
map()方法之后reduce()方法之前这段处理过程叫做Shuffle。 map()方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到环形缓冲区;环形缓冲区默认大小100MB,环形缓冲区达到80%时,进行溢写;(简单一点就是,快要超限了,存到磁盘吧);溢写前对数据进行排序,排序按照对K的索引进行字典序排序,排序的手段是快排;溢写产生大量溢写文件,需要对溢写文件进行归并排序;对溢写的文件也可以进行Combiner操作,前提是汇总操作,求平均值是不行的。最后将文件按照分区存储到磁盘,等待Reduce端过来拉取分区数据。 每个Reduce拉取Map端对应分区的数据。拉取数据后先存储到内存中,内存不够了,再存储到磁盘。拉取完所有数据后,采用归并排序将内存和磁盘中的数据都进行排序。在进入Reduce方法之前,可以对数据进行分组操作。
相关细节
maptask执行,收集maptask的输出数据,将数据写入环形缓冲区中,记录起始偏移量。 环形缓冲区默认大小为100MB,当数据达到80MB的时候,记录终止偏移量。 将数据进行分区(默认分组根据K的hash值 与Integer最大值做&操作后,%reduce数量进行分区),分区内进行快速排序。 分区、排序结束后,将数据刷写到磁盘(这个过程中,maptask输出的数据写入剩余20%环形缓冲区,同样需要记录起始偏移量)。 maptask结束后将形成的多个小文件做归并排序合并成一个大文件。 当有一个maptask执行完成后,reducetask启动。 reducetask到运行完成maptask的机器上拉取属于自己分区的数据。 reducetask将拉取过来的数据“分组”,每组数据调用一次reduce()方法。 执行reduce逻辑,将结果输出到文件。
总结
map()方法之后,reduce()方法之前的操作叫做Shuffle。
Map端和Reduce端:map() -> 分区 -> 环形缓冲区 -> 排序 -> 溢写 -> 归并排序 -> 写入磁盘,等待Reduce端拉取。
Reduce端:拉取对应分区数据 -> 存储在内存(内存不足,写入磁盘) -> 拉取完数据,归并排序 -> 对数据进行分组 -> 每组数据调用一次reduce()方法。
5. Combiner的作用?
细节可见public class MapTask extends Task源码查看CombinerRunner处理过程。
①与Mapper和Reducer不同的是,Combiner没有默认的实现,需要显式的设置在conf中才有作用。
job.setCombinerClass(IntSumReducer.class);
②并不是所有的job都适用Combiner,只有操作满足结合律的才可设置Combiner。Combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值、平均值的话,不适用。
每一个Map都可能会产生大量的本地输出,Combiner的作用就是对Map端的输出先做一次合并,以减少在Map和Reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一,其具体的作用如下所述。
Combiner最基本是实现本地key的聚合,对map输出的key排序,value进行迭代。如下所示:
*map: (K1, V1) → list(K2, V2) *
* combine: (K2, list(V2)) → list(K2, V2) *
reduce: (K2, list(V2)) → list(K3, V3)
Combiner还有本地reduce功能(其本质上就是一个reduce),例如Hadoop自带的wordcount的例子和找出value的最大值的程序,combiner和reduce完全一致,如下所示:
*map: (K1, V1) → list(K2, V2) *
* combine: (K2, list(V2)) → list(K3, V3) *
reduce: (K3, list(V3)) → list(K4, V4)
可以理解为谓词下推,把能在本地完成的计算下推到本地完成,而不是直接通过网络把一次计算的结果数据拉到新的计算节点,这也是移动计算而非移动数据的体现(减少网络IO)。总之,在本地进行一次计算后的结果数据还可以二次计算,就等二次计算完成,本地计算不了了,再移动二次计算的结果到Reduce节点进行聚合计算出最终结果。
6. 简述MapReduce的调优方法
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
数据输入
合并小文件,在执行MR任务前将小文件进行合并,大量的小文件会产生大量的Map任务,增大Map任务装载次数,而任务的装载比较耗时,从而导致MR运行较慢; 采用CombineTextInputFormat来作为输入,解决输入端大量小文件的场景。
Map阶段
减少溢写次数,通过调整io.sort.mb及sort.spill.percent参数值,增大溢写的内存上限,减少溢写次数,从而减少磁盘IO。 减少合并次数,通过调整io.sort.factor参数,增大merge的文件数目,减少merge的次数,从而缩短MR的处理时间。 在Map之后,不影响业务逻辑的前提下,先进行Combiner处理,减少IO。
Reduce阶段
合理设置Map和Reduce数量,两个数量都不能太少或者太多,太少,会导致task等待时间太长,延长处理时间,太多,会导致Map和Reduce任务之间竞争资源,造成处理超时等错误; 设置Map和Reduce共存,调整mapreduce.job.reduce.slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,从而减少Reduce等待时间; 规避使用Reduce,因为Reduce在用于连接数据集的时候会产生大量的网络消耗; 合理使用Reduce端的buffer,可以通过设置参数来配置,使得buffer中的一部分数据可以直接输送到Reduce,从而减少IO开销;mapreduce.reduce.input.buffer.percent的默认为0.0,当值大于0时,会保留在指定比例的内存读buffer中的数据直接拿给Reduce使用。
IO传输
采用数据压缩的方式,减少任务的IO时间。 使用Seq二进制文件。
7. Hadoop集群有哪几个进程,各自的作用是什么?
HDFS和YARN
NameNode,管理文件系统的元数据的存储,记录文件中各个数据块的位置信息,负责执行有关文件系统的命名空间的操作,如 打开、关闭、重命名文件和目录等,一个HDFS集群只有一个Active活跃的NameNode,可以有其他从元数据节点Standby。
SecondaryNameNode,合并NameNode的edits log到fsimage文件中辅助NameNode将内存中的元数据信息持久化。
NodeManager,是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点包括与ResourceManager保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
DataNode,数据存储节点,保存和检索block(数据块)负责提供来自文件系统客户端的读写请求,执行块的创建、删除等操作。
ResourceManager,在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点NodeManager的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上就是针对具体应用的ApplicationManager)RM与每个节点的NodeManager(NMs)和每个应用的ApplicationMasters(AMs)一起工作。
8. YARN的job提交流程
主要是MapReduce应用
作业提交
(1). Client调用job.waitForCompletion方法,向整个集群(RM)提交MapReduce作业。
nativejob.waitForCompletion(true);
(2). Client向ResourceManager申请一个作业id。 (3). ResourceManager给Client返回该job资源的提交路径(HDFS路径)和作业id,每一个作业都有一个唯一的id。 (4). Client发送jar包、切片信息和配置文件到指定的资源提交路径。 (5). Client提交完资源后,向ResourceManager申请运行MRAppMaster(The Map-Reduce Application Master.)
作业初始化
(6). 当ResourceManager收到Client的请求后,将该job添加到容量调度器(CapacityScheduler)中。
@LimitedPrivate("yarn")
@Evolving
@SuppressWarnings("unchecked")
public class CapacityScheduler extends
AbstractYarnScheduler<FiCaSchedulerApp, FiCaSchedulerNode> implements
PreemptableResourceScheduler, CapacitySchedulerContext, Configurable,
ResourceAllocationCommitter, MutableConfScheduler {}
(7). 某一个空闲的NodeManager领取到该job。 (8). 该NodeManager创建Container,并拉取jar包启动运行MrAppMaster。 (9). 下载Client提交的资源到本地,根据分片信息生成MapTask和ReduceTask。
任务分配
(10). MRAPPMaster向ResourceManager申请运行多个MapTask任务资源。 (11). ResourceManager将运行MapTask任务分配给空闲的多个NodeManager,NodeManager分别领取任务并创建容器(Container)。
任务运行
(12). MRAppMaster向两个接收到任务的NodeManager发送程序启动脚本,每个接收到任务的NodeManager启动MapTask,MapTask对数据进行处理,并分区排序。 (13). MRAppMaster等待所有MapTask运行完毕后【默认情况下】,向ResourceManager申请容器(Container),运行ReduceTask。 (14). 程序运行完毕后,MRAppMaster会向ResourceManager申请注销自己。 (15). 进度和状态更新。YARN中的任务将其进度和状态(包括Counter)返回给应用管理器,客户端每秒(通过mapreduce.client.completion.pollinterval参数设置)向应用管理器请求进度更新,展示给用户。可以使用YARN WebUI查看任务执行状态。
作业完成
除了向应用管理器申请作业进度外,客户端每5分钟都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后,应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
9. HDFS集群的block大小是128MB,现在有一个大小是260MB的文件,对该文件进行split的时候,会被分成几片?
2片,1.1的冗余,每次对文件进行切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分为一个切片。
10. 列举MR中可自定义实现的组件
Combiner:相当于在Map端对每个MapTask生成的文件做了一次Reduce操作。 Partition:分区,默认根据key的hash值与Integer最大值进行&运算后,%Reduce的数量,自定义分区是集成Partitioner类,重写getPartition()分区方法。自定义分区可以有效的解决数据倾斜的问题。
/**
* Partition keys by their {@link Object#hashCode()}.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
Group:分组,继承WritableComparator类,重写compare()方法,自定义分组(就是自定义Reduce输入的数据分组规则)。
public static class MyCmp extends WritableComparator {
public MyCmp() { super(MyWritable.class, true); }
public int compare(WritableComparable a, WritableComparable b) {
MyWritable aa = (MyWritable)a;
MyWritable bb = (MyWritable)b;
return aa.j - bb.j;
}
}
Sort:排序,实现WritableComparable接口,重写compareTo()方法,根据自定义的排序方法,将Reduce的输出结果进行排序。
public static class MyWritable implements WritableComparable<MyWritable> {
int i, j;
public MyWritable() { }
public MyWritable(int i, int j) {
this.i = i;
this.j = j;
}
public void readFields(DataInput in) throws IOException {
i = in.readInt();
j = in.readInt();
}
public void write(DataOutput out) throws IOException {
out.writeInt(i);
out.writeInt(j);
}
public int compareTo(MyWritable b) {
return this.i - b.i;
}
static {
WritableComparator.define(MyWritable.class, new MyCmp());
}
}
分片:可调整客户端的blockSize,minSize,maxSize
11. 分片和分块的区别?
分片是逻辑概念,分片有冗余。 分块是物理概念,是将数据拆分,无冗余。
12. ResourceManager的工作职责
资源调度 资源监控 Application提交
13. NodeManager的工作职责
主要是节点上的资源管理,启动Container运行task计算,上报资源、Container情况非RM和任务处理情况给AM。
14. YARN的调度器
目前YARN有三种比较流行的资源调度器:FifoScheduler、CapacityScheduler、FairScheduler。
FifoScheduler(先进先出调度器) Hadoop1.x使用的默认调度器是FIFO(还没有YARN),FIFO采用队列方式将一个一个job任务按照时间先后顺序进行服务。比如排在最前面的job需要若干MapTask和若干ReduceTask,当发现有空闲的服务器节点就分配给这个job,直到job执行完毕。
CapacityScheduler(容量调度器) Hadoop2.x使用的默认调度器是CapacityScheduler。
支持多个队列,每个队列可配置一定量的资源,每个队列采用FIFO的方式调度。 为了防止同一个用户的job任务独占队列中的资源,调度器会对同一用户提交的job任务所占资源进行限制。 分配新的job任务时,首先计算每个队列中正在运行task个数与其队列应该分配的资源量做比值,然后选择比值最小的队列。如果某队列A有15个task,20%的资源量,那么就是15%/0.2=75,某队列B是25%/0.5=50,某队列C是25%/0.3=83.33。所以选择最小值对垒是B。 其次,按照job任务的优先级和时间顺序,同时要考虑到用户的资源量和内存的限制,对队列中的job任务进行排序执行。 多个队列同时按照任务队列内的先后顺序一次执行。比如job1、job2、job3分别在三个队列A、B、C中顺序各自比较靠前,三个应用的任务就同时执行。
FailScheduler(公平调度器)
支持多个队列,每个队列可以配置一定的资源,每个队列中的job任务公平共享其所在队列的所有资源。 队列中的job任务都是按照优先级分配资源,优先级越高分配的资源越多,但是为了确保公平每个job任务都会分配到资源。优先级是根据每个job任务的理想获取资源量减去实际获取资源量的差值决定的。差值越大优先级越高。
15. 我们开发job时,是否可以去掉Reduce阶段
可以,设置reduce数量为0即可。
附:MapReduce VS Tez VS Spark
MapReduce的编程模型
Hadoop MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。
MapTask:
读数据:读取源数据,MapTask获取分片数据信息(类型有:TextInputFormat,文本文件;SequenceFileInputFormat,序列化文件;DBInputFomrat,数据库文件), 形成key-value数据;
逻辑处理:通过循环调用Mapper类的map方法读取每行数据进行处理;
分区:通过Partitioner类的getPartition()方法对数据进行分区(默认执行HashPartitioner,分发规则:(key的hashcode值&Integer.MAX_VALUE)%numReducetTasks),分区规则注明分区号相同的数据会被分发给同一ReduceTask(只要按照规则就会返回相同的分区号);
排序:将数据通过key的compareTo()方法比较排序(默认是普通的字典排序);
ReduceTask:
读数据:ReduceTask会通过http方式下载各自处理的“分区”的数据到本地磁盘,并合并排序,执行默认的GroupingComparator确定数据key相同的为同一组(我们在自定义的时候写一个类A继承WritableComparator,根据需求重写compare()方法,因为要从磁盘上读取数据,那么需要反序列化,需要在A的构造函数中告知WritableComparator反序列化的类型,否则会出错);
处理数据:ReduceTask把相同key的数据值聚合到Reducer类,按照reduce()方法处理逻辑,输出数据(输出类型:TextOutputFomat,文件类型;SequenceFileOutputFomrat,序列化文件;DBOutputFomrat,数据库数据文件)。如下图:
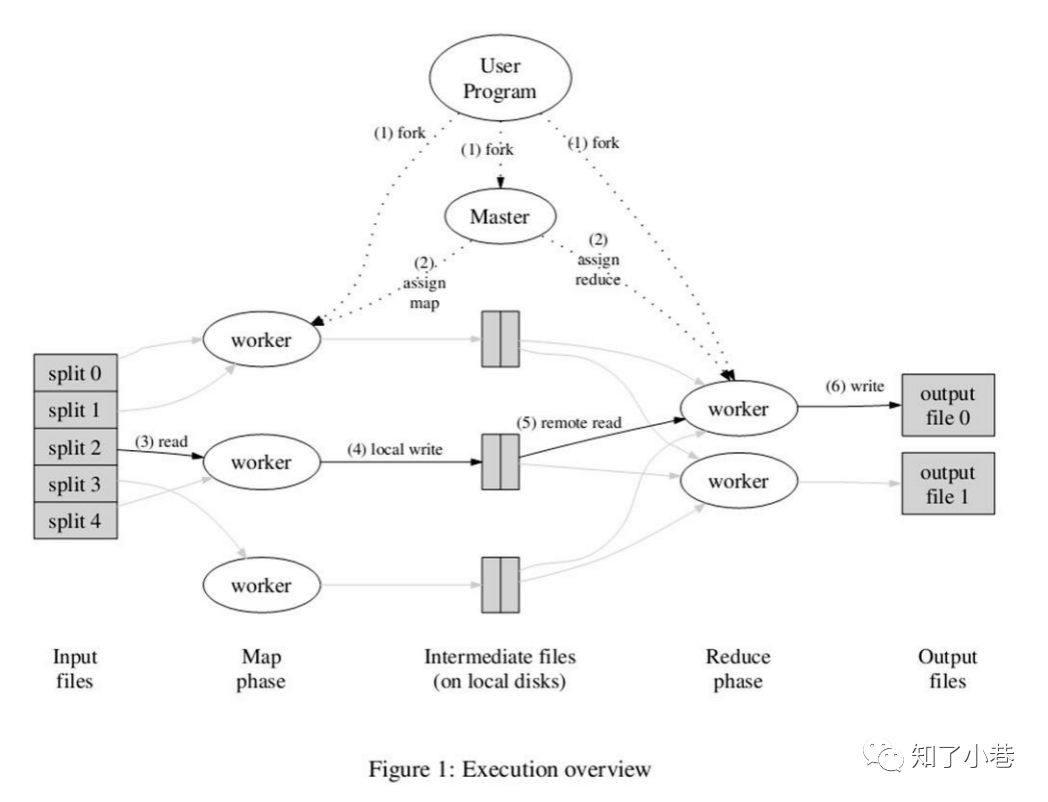
Tez的计算架构
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output,Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。总结起来,Tez有以下特点:
Apache顶级开源项目
http://tez.apache.org/运行在YARN之上 适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
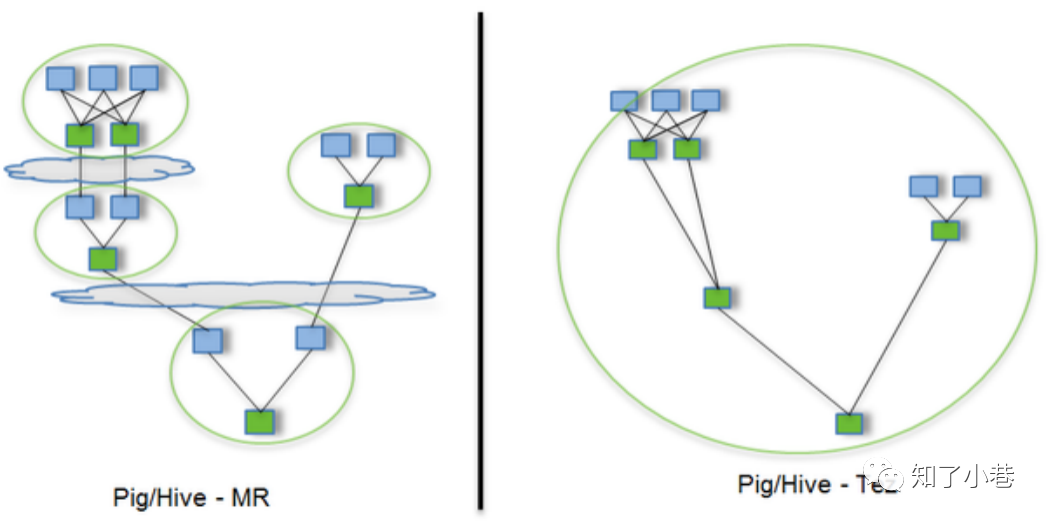
传统的MR(包括Hive,Pig和直接编写MR程序)。假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业)或者用Oozie描述的4个有依赖关系的作业,运行过程如上图(其中,绿色是Reduce Task,需要写HDFS)。Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能。
Spark计算框架
Spark是一个分布式的内存计算框架,其特点是能处理大规模数据,计算速度快。Spark延续了Hadoop的MapReduce计算模型,相比之下Spark的计算过程保持在内存中,减少了硬盘读写,能够将多个操作进行合并后计算,因此提升了计算速度。同时Spark也提供了更丰富的计算API。
MapReduce是Hadoop和Spark的计算模型,其特点是Map和Reduce过程高度可并行化;过程间耦合度低,单个过程的失败后可以重新计算,而不会导致整体失败;最重要的是数据处理中的计算逻辑可以很好的转换为Map和Reduce操作。对于一个数据集来说,Map对每条数据做相同的转换操作,Reduce可以按条件对数据分组,然后在分组上做操作。除了Map和Reduce操作之外,Spark还延伸出了如filter,flatMap,count,distinct等更丰富的操作算子。
知了小巷
长按识别二维码,一键关注


