




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。

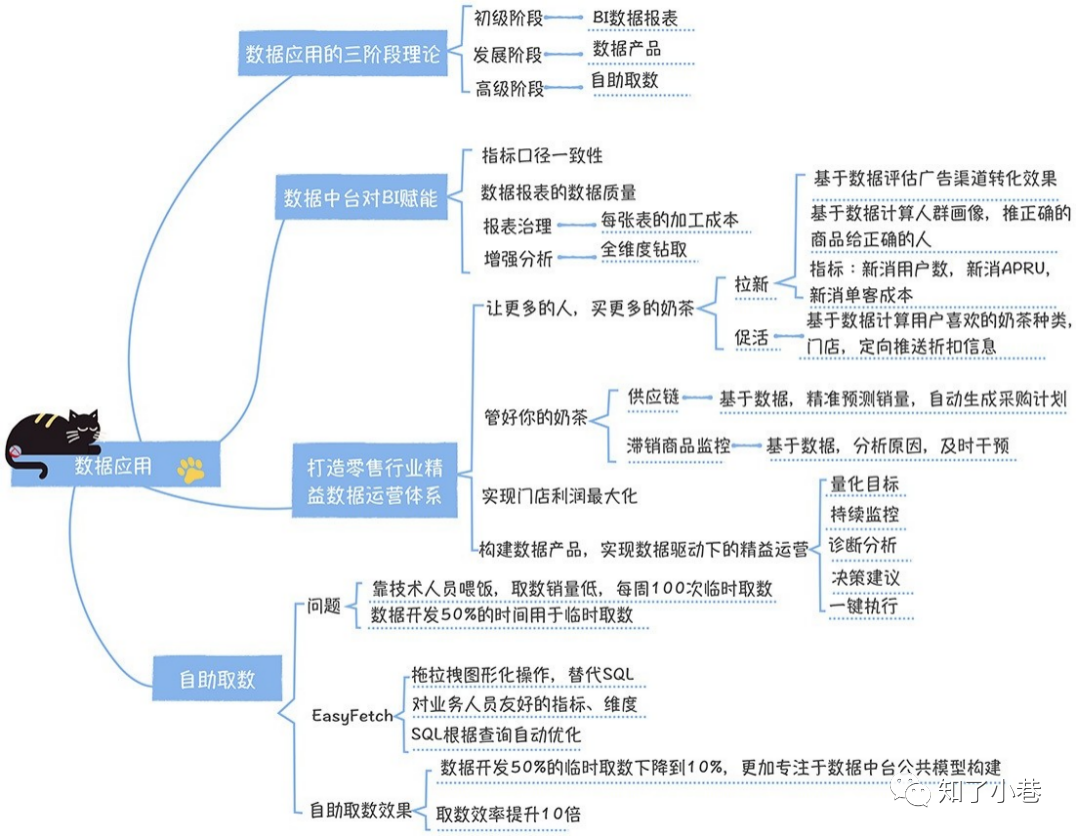
数据应用的叁个阶段
现在是要在数据中台的基础上,构建企业数据应⽤体系,⽤好数据中台的数据。对企业来说,⽤好数据⾮常关键,数据在企业的应⽤划分成如下三个阶段。

初级阶段。⼀般企业的数据应⽤都是从数据报表开始的,分析师会为业务部⻔的负责⼈、运营制作⼀些BI 报表,把数据通过可视化的⽅式呈现出来,这是数据应⽤的初始阶段。 发展阶段。只是可视化的展现数据已经不能满⾜业务的需求,业务需要根据数据持续监控业务过程,发现 问题、诊断分析,并给出决策建议,最后需要⼀键执⾏,形成完成的业务过程闭环,这个时候就要借助数据产品来实现,并逐渐⼤规模构建数据产品体系。 ⾼级阶段。⽆论是数据报表、还是数据产品,它们呈现的都是固化的分析思路,只能解决已经知道的业务问题,但是⽇常⼯作还有很多未知的业务问题,⽐如销售额指标突然下降了,需要基于数据进⾏探索分析。这个时候,如果都依赖分析师,肯定不现实,那么就要实现⾃助取数,让每个⼈都能基于数据去做分析和决策,实现普惠⼤数据。这才是数据应⽤的最⾼级阶段,通过开放越来越多的中台数据,让更多的⾮技术⼈员去使⽤数据。
数据中台该如何赋能BI⼯具
很多⼈对数据的了解,都是从BI⼯具做的报表开始的。本文重点不是放在BI⼯具的产品本⾝,而是,在数据中台时代,如何让数据中台帮助BI⼯具更强⼤。
第⼀,统⼀报表指标业务⼝径
数据报表上会存在指标⼝径不⼀致的问题,相同指标名称,两个报表⾥的数据却相差很⼤,这会让数据使⽤者对数据失去信任。
⽽数据中台的所有的指标都是由指标系统统⼀管理的,如果能在数据报表上直接看到指标系统中,指标的⼝径定义,就可以让看报表的⼈准确理解数据的含义,也可以避免不同报表之间指标⼝径不⼀致的问题。
同时,如果我们在指标系统上修改了指标的⼝径定义,也可以同步到所有的呈现该指标的数据报表中。
第⼆,掌握任务影响了哪些数据报表
当某个任务异常,影响了下游多个任务时,我们往往要根据任务的影响范围,决定任务恢复的优先级。如果任务影响了⽼板每天看的⼀张报表,⽽我们却不知道,没有优先修复它,那就等着被批吧。
那我们要怎么知道⼀个任务影响了哪些数据报表呢?
数据报表在保存时,BI⼯具可以把报表和数据的链路关系,推送给数据中台的元数据中⼼。当数据中台的任何⼀个任务出现异常,通过数据⾎缘,就可以快速找到这个任务影响了哪些数据报表,尤其是在故障恢复的时候,根据报表的优先级,可以优先恢复⾼优先级的报表。
第三,治理低价值的数据报表
根据数据中台的全链路数据⾎缘,可以计算每⼀个报表上游所有的数据加⼯成本,然后得到这个报表的成本。然后根据报表的访问量和访问⼈群,可以计算报表的ROI(投⼊产出⽐),下线低价值的数据报表。
第四,全维度钻取
在制作报表时,分析师只能依靠经验去判断⼀个指标有哪些可分析维度。如果BI⼯具能根据元数据中⼼提供的所有指标可分析维度,⾃动根据指标在各个维度下的取值,找出指标波动的原因,那这就是全维度钻取了,它是⽬前业界最为热⻔的研究领域,增强分析的⼀个⽅向。
⽐如,有⼀个单⻋租赁公司,发现8⽉份的营业额下降了,系统通过根据各个维度的数据对⽐和分析发现,8⽉份营业额下降,是因为那个⽉⾬天的天数增多导致的。如果分析师不知道⽤天⽓的维度去分析营业额,很可能就不知道原因。但是全维度钻取,可以基于数据中台营业额的所有可分析维度,包括天⽓,⾃动计算出⾬天的销售额相⽐晴天的销售额低,同时进⾏交叉分析,发现8⽉份的⾬天数量⽐其他⽉份多,最后找到问题的原因。
实际上,数据中台已经在很⼤程度上增强了BI⼯具的产品能⼒!
在BI⼯具的基础上制作数据报表,这才是数据应⽤的初级阶段,接下来,基于数据中台,做出适合各种业务场景的数据产品,提升业务的运营效率。
打造零售⾏业精益数据运营体系
零售⾏业是⽬前所有⾏业中,对数据使⽤程度最深的⾏业,以零售⾏业为例,了解如何借助数据实现精益运营。
假如现在开了一家“贾天真连锁奶茶店“,作为老板,奶茶店的⽬标是把更多的奶茶卖给更多的⼈,赚更多的钱。要时刻谨记零售⾏业⼀个很经典的理论,那就是:⼈、货、场,在正确的地点,把正确的商品,卖给正确的⼈。
让更多的⼈,买更多的奶茶
为了让更多的⼈,买更多的奶茶,必须要解决客⼾拉新和促活的问题。那如何拉新呢?获得新⽤⼾的⽅式,⼀般就是做⼴告,但是做⼴告也有很多渠道:
微信公众号; 抖⾳; 快⼿短视频; ⼩区电梯; ……
可这么多的⼴告渠道,到底哪个渠道的⼴告效果最好,性价⽐最⾼呢?数据说了算!
⼀般⽤新消⽤⼾数、单个新消⽤⼾的平均消费⾦额(新消ARPU)、新消单客成本来衡量各个渠道的⼴告投放效果。可以参考这⼏点,选择最优的⼴告投放渠道。例如,微信公众号相⽐快⼿短视频,每⽇新消⽤⼾数更多、单个新消的平均消费⾦额更多、新消客成本更低,那么就应该果断选择微信公众号。
当然,⼴告中选择的奶茶种类也会在很⼤程度上影响⼴告拉新效果。⽐如⾼档⼩区投放⼴告时,应该选择价 格⾼、健康的饮品;普通⼩区的话,更加亲⺠的奶茶才能吸引更多的客⼾。那如何来选择奶茶的种类呢?还是数据说了算!
除了根据数据选择奶茶种类之外,⼴告的投放也要讲究策略,就拿微信公众号这个渠道来说,年纪⼤的客⼾群体,注重健康饮品;年轻的客⼾群体,注重价格亲⺠,⼝感,样式。所以,必须要基于⼈群画像(年龄、 地区、学历等),决定推送哪些⼈哪些商品。⾄于⼈群画像,需要基于⽇常的顾客交易数据计算⽽来。
不过,光拉新⽤⼾,但是如果留不住⽤⼾也不⾏。那么如何让⽼⽤⼾,增加消费奶茶的频率呢?
比如这样⼀些套路,经常收到⼀些短信、App站内消息、⼩程序、微信公众号推送的打折信 息,然后没忍住,就“剁⼿“了。商家是怎么知道我么这些信息和喜欢哪一款的呢??
对于推荐算法有⼀个很经典的论述:⼤数据可以做到让机器⽐我们⾃⼰更了解⾃⼰。 所以,如果我们曾经购买过奶茶,那系统就可以交易⾏为数据计算出我们喜欢的奶茶⼝味、品类,平时喜欢在哪家店购买,然后定向把这些店对应的奶茶优惠信息推送给我们,这样⼤概率会中招!
可以看到,店家总是有各种各样的套路促进人们消费。
店家在数据的基础上,⼀⽅⾯可以让新客源源不断;⼜可以增加⽼客复购的频率,这时整个奶茶⽣意的销售额就实现了最⼤化。
保障奶茶不要断货
作为⽼板,要让更多的奶茶,卖给更多的⼈,那前提必须要保障奶茶的充⾜供应,这就涉及到供应链管理的问题。
因为奶茶本质上属于⽣鲜品,如果⻔店囤货太多,鲜果就会烂掉。但如果缺货,⼜会影响⻔店的销售,所以如何在保证不缺货的前提下,尽量减少⻔店的囤货,这是必须要解决的问题。
⽽供应链涉及到销售、补货、到货和库存四个环节。如果有⼀款数据产品,可以根据奶茶的实际销售情况和销售计划、结合⻔店库存的安全⽔位、采购时间周期,⾃动计算需要补货的原材料,然后推送给采购系统进⾏补货,如此这般是不是会觉得很省⼼?
实现⻔店的利润最⼤化
当然了,奶茶卖的多不多,还和⻔店有很⼤的关系。如果门店的店员,可以根据数据,及时发现滞销的奶茶,然后在客⼾结账的时候,主动推荐这些奶茶,那么门店就可以获得更⾼的收益。我们⼀般使⽤“效坪(每天每平⽶⻔店的营业额)“来衡量单个⻔店的经营状况。
通过这⼏点,可以看到,零售⾏业有很多赚钱的窍⻔。接下来,了解⼀下如何基于数据产品, 轻松地使⽤这些窍⻔。
构建数据产品,实现数据驱动下的精益运营
数据产品与BI报表最⼤的不同,在于它们不仅可以实现数据的可视化展⽰,更为重要的是,可以基于数据,对业务过程进⾏持续的监控,及时发现问题,进⾏诊断,并形成决策建议,付诸执⾏。
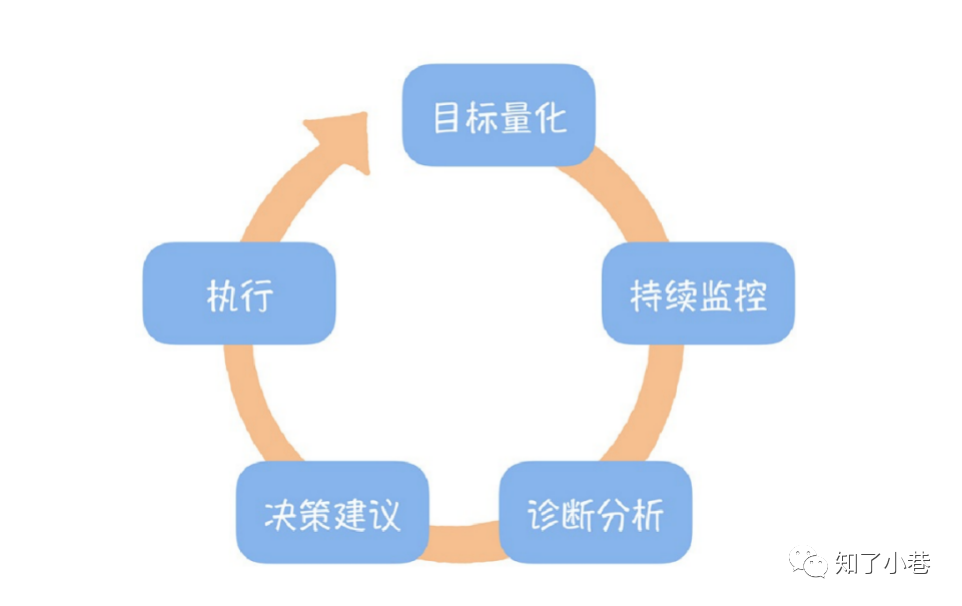
数据产品,⾸先要实现对业务⽬标的量化。对于卖奶茶来说,要关注的重点是研发出更多的⽹红款的奶茶,确保圈住更多的“奶茶粉⼉“,同时降低库存周转的压⼒,因为有越多的滞销奶茶,就会导致积压更多的货物,产⽣更多的成本。
为了实现这个⽬标,可以⽤动销率来评估⽬标的达成。
动销率:销售商品的品类数量占库存的商品品类数量的⽐例。
为了提⾼动销率,数据产品必须对每个奶茶品类进⾏销售的跟踪,及时发现零动销的奶茶。
所以,作为奶茶店老板可能会经常收到“xxx款奶茶零动销”"xxx款奶茶慢动销"的预警信息,然后接下来就要对这款奶茶出现零动销进⾏分析了:数据产品会通过不同季节横向对⽐这款奶茶的销售情况,也会通过顾客消费问卷去分析这款奶茶的⼝感,最终找到这款奶茶滞销的原因。
接下来,就要根据原因产⽣决策建议了。⽐如如果是因为奶茶⼝感的因素,应该及时下架这款奶茶,否则会影响⼝碑。数据产品可以推送给运营进⾏审核,然后运营确认后,⼀键下线商品,此后各个奶茶店的菜单中,不会再出现该款奶茶。
当然了,只是拿零售⾏业举了个例⼦,因为很多问题都是共通的,⽤奶茶店,总结了⼀些⽅法论,可以结合⾃⼰所在的⾏业去应⽤:
找到业务问题、量化业务⽬标,⽐如,我们找到提⾼奶茶周转的关键,在于及时发现滞销奶茶品类,那么 我们⽤动销率来衡量业务⽬标;
然后要对业务⽬标持续监控,及时发现问题,⽐如,我们监控各个品类奶茶的销售情况,及时发现零动销奶茶;
紧接着,要对问题进⾏诊断,⽐如,我们要发现奶茶滞销是因为⼝感太差;
当然,还要根据原因形成决策,⽐如下线这款奶茶;
最后付诸执⾏,⽐如通过⼀键,在所有⻔店菜单中去掉了该品类奶茶。
数据产品实现了从监控问题、发现问题、解决问题的完整闭环。可数据产品毕竟还是按照固化的分析思路进⾏分析和产⽣决策建议,在⽇常运营中,还会有很多数据产品或者数据报表⽆法解释的问题,这个时候就必须要依赖探索式的数据分析来解决,⽽探索分析的⻔槛主要在于获取数据,接下来,就是⾃助取数的问题。
让技术⼈员不再是数据的搬运⼯,释放取数效能
对于传统⾏业来说,BI部⻔⼀般有两项职责,⼀个是做报表,⼀个是取数。⽽取数的⼯作量远远多于报表的⼯作量。
⼀年中做的报表可能就⼏百张,但是取数,⼀年可能要取⼏千次,或者上万次。⽽⼤部分传统企业的取数会依赖技术⼈员,因为他们离数据更近,取数还涉及写代码,所以,如果小伙伴是⾮技术⼈员,根本不可能基于数据去做探索式的分析。
所以,⼤量的取数⼯作就落在了懂技术的数据开发的头上。
靠别⼈取数,会存在⼤量的沟通和协作的成本,同时因为公共集市层数据不完善,导致⽆法基于现有的数据,直接完成取数,需要数据开发加⼯新的数据,所以耗时会⾮常的⻓,⼀般需要⼀周时间。⾼昂的取数成本,压制了取数的需求,也导致探索式的数据分析,根本不可能⼤规模的使⽤。
对于数据开发来说,他们更希望⾃⼰的⼯作重⼼放在建设公共集市层的数据上,因为公共集市层越完善,取数的成本就越低,不需要额外的开发。但是他们忙于临时的取数需求,根本就没有时间和精⼒去做这些⼯作。最后就形成了不良循环,越是集市层数据不完善,取数的⼯作量就会越⼤(要开发新的模型),越多的时间去临时取数,集市层越没⼈建设。
这个问题该如破解呢?网易研发了⼀个⾃助取数平台,叫EasyFetch(意为简单取数)。
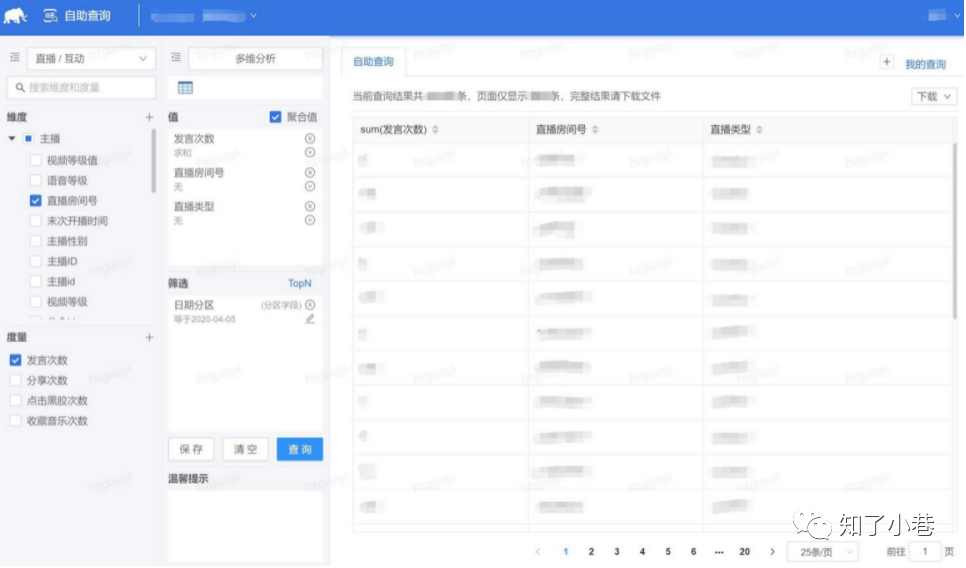
这个平台主要有这样⼏个优点:
⽤图形化的⽅式,替代了写SQL的⽅式; 提供了对业务⼈员⽐较友好的业务过程、指标、维度的概念,替换了表、字段; 每个指标的业务⼝径都能够直接显⽰; ⽤⼾通过选取⼀些指标和维度,添加⼀些筛选值,就可以完成取数过程; 界⾯⾮常简洁,使⽤⻔槛⾮常低。
在实现层⾯,在数据中台⾥,加⼯了多个⾯向不同业务过程的集市层的表,取数平台会⾃动根据⽤⼾选择的度量和维度,去对应的表中关联多张表进⾏查询,SQL会⾃动根据查询进⾏优化,避免⾮技术⼈员调试SQL以及写的SQL质量⾮常差的问题。
通过⾃助取数平台,原先数据开发50%的时间都在临时取数,⽽现在只有10%的时间,在⾃助取数平台⽆法满⾜(需要加⼯集市层模型)的情况下,帮助⽤⼾取数。
同时,这部分的⼯作也会对集市层模型的不断优化产⽣促进作⽤。对于取数效率来说,原先10个数据开发,⼀周做100个取数需求,已经是濒临极限。⽽现在,我们⼀周有1000多次有效取数的需求在⾃助取数平台完成,取数效率提升了10倍以上。
还有⼀个有趣的现象,在周末,也有很多⼈在使⽤取数平台,经过调研,发现很多⼈在基于数据写周报,这是之前完全⽆法想象的事情。
最后,建议在设计取数平台时,⼀定要注重简洁、对⽤⼾的引导、降低⽤⼾的使⽤⻔槛。因为我们⾯临的是⾮技术⼈员,我们要拿出做C端产品的姿态去做取数产品。
总结
数据中台之上,可以有这么多的数据应⽤场景,数据可以帮助我们实现这么多原先不可能做到的事情。重点:
数据中台对BI赋能体现在指标⼝径的⼀致、任务影响分析、数据报表的成本以及基于数据中台的元数据之上的全维度钻取; 数据产品实现了从⽬标量化,持续跟踪,异常诊断,决策建议,最后到执⾏的完整数据驱动业务⽬标达成的闭环; 通过实现⾯向⾮技术⼈员友好的⾃助取数平台,让数据开发专注于集市模型的构建,可以释放取数的效能,⼤幅度促进数据的应⽤范围和深度。
值得一提的是,实时报表使用Kafka+Kudu+Impala架构的还是挺多的,BI基于impala查询实时数据。
往期推荐:
知了小巷
生而分享,为你而美

